Copyright © 2002 RNDr. Libor
Dostatek
EurOpen.CZ
Česká společnost uživatelů
otevřených systémů
http://www.europen.cz

Tutorial PKI
RNDr. Libor Dostálek
Jetřichovice
2. června 2002
![]()
1 Obsah
4 Autentizace uživatele a autorizace dat bez
využití asymetrické kryptografie
4.2.1 Seznam jednorázových
hesel
4.2.7 Autentizační
kalkulátory
4.2.8 Jednorázová hesla přes
GSM
6.1 Diffe-Hellmanův algoritmus
7 Využití asymetrické kryptografie
7.1.1 Uložení soukromého
klíče na disku
8.1.2 Identifikační údaje CA
(vystavitel certifikátu) - Issuer
8.1.3 Identifikační údaje
uživatele (předmět certifikátu) - subject
8.3 Žádost o odvolání certifikátu
8.4 Seznam odvolaných
certifikátů - CRL
8.5 On Line zjišťování
platnosti certifikátu - OCSP
8.6 Žádost o certifikát tvaru
CRMF
8.7.2 Typ zprávy „Signed
Data“
8.7.3 Typ zprávy „Enveloped
Data“
9.4 Certikační politiky
(certifikační zásady)
9.4.1 Testovací certifikační
autority
9.5 Vytvoření žádosti o
certifikát
10 Jaké certifikáty budeme používat?
11.1 Architektura elektronické
pošty
11.2.1 Přehled základních
hlaviček z RFC-822
12.1.3 Hlavička
Content-Transfer-Encoding
12.1.5 Hlavička
Content-Description
12.1.6 Hlavička
Content-Disposition
12.2 Standardní kódovací
mechanismy
12.3 Znaky v hlavičce, které
nejsou ASCII
12.4 Jednoduché typy dat v
hlavičce Content-Type
12.5 Kompozitní typy v
Content-Type
13.1 Zpráva CMS používaná
v S/MIME
13.3 MIME: Multipart/Signed a
Multipart/Encrypted
13.5 Jaká číhají nebezpečí na
adresáta
17 Aplikace PKI v elektronickém bankovnictví
přes Internet
17.1 HomeBanking,
InternetBanking apod.
![]()
2 Úvod
 Tento
materiál je určen pro tutoriál konference EurOpen 2002. Jeho základem jsou
texty, které jsem v minulosti používal k výuce a které jsou vystaveny na
http://info.pvt.cz. Z těchto textů také vznikl „Velký průvodce protokoly
TCP/IP, bezpečnost“ vydaný ve vydavatelství CopmputerPress.
Tento
materiál je určen pro tutoriál konference EurOpen 2002. Jeho základem jsou
texty, které jsem v minulosti používal k výuce a které jsou vystaveny na
http://info.pvt.cz. Z těchto textů také vznikl „Velký průvodce protokoly
TCP/IP, bezpečnost“ vydaný ve vydavatelství CopmputerPress.
Z pohledu čtenáře lze to s jistou mírou nadsázky říci i obráceně: tento materiál je zjednodušením publikace „Velký průvodce protokoly TCP/IP, bezpečnost“, tak aby laskavý čtenář nebyl obtěžován zbytečnými detaily jako je např. popis jednotlivých datových struktur atp.
Počátek tohoto materiálu se věnuje některým alternativním technologiím. Na první pohled by se mohlo zdát zbytečné o těchto technologiích v úvodu do PKI psát, ale důvod vložení jejich podpisu do tohoto materiálu je ryze praktický. Mnohdy se tyto technologie kombinují s PKI. Příkladem takové kombinace může být bezpečný web (protokoly SSL/TLS). A podle mého názoru je pro čtenáře podstatně příjemnější si tyto technologie vychutnat i s jejich praktickým využitím než je vkládat jako abstraktní kapitoly do popisu bezpečného webu.
![]()
3 Hash
 Ještě
před tím než se přejdeme k šifrovacím algoritmům, tak si ukážeme jaké užitečné věci lze udělat pomocí
na první pohled tak jednoduchého mechanismu jako je hash. Anglické slovo hash
se do češtiny překládá různě: kontrolní součet, miniatura či výstižně ale asi
ne zcela spisovně „výcuc“. Pokud však hovorově chceme někomu sdělit co máme na
mysli, pak zpravidla použijeme slovo hash [čti heš]. V následujících
kapitolách bude používat termín „kontrolní součet“.
Ještě
před tím než se přejdeme k šifrovacím algoritmům, tak si ukážeme jaké užitečné věci lze udělat pomocí
na první pohled tak jednoduchého mechanismu jako je hash. Anglické slovo hash
se do češtiny překládá různě: kontrolní součet, miniatura či výstižně ale asi
ne zcela spisovně „výcuc“. Pokud však hovorově chceme někomu sdělit co máme na
mysli, pak zpravidla použijeme slovo hash [čti heš]. V následujících
kapitolách bude používat termín „kontrolní součet“.
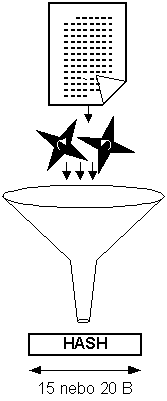
Hash je jednocestná funkce která nám z libovolně dlouhého textu vyrobí krátký řetězec konstantní délky. Výsledný řetězec (hash) by měl maximálně charakterizovat původní text. Typická velikost výsledného textu je 16B (např. algortimus MD-5) nebo 20B (algoritmus SHA-1). Jednocestnou funkcí se rozumí algoritmy, které technicky snadno umožňují spočíst výsledek, ale k výsledku najít původní text je technicky extrémně náročné.
Jelikož se hash počítá z libovolně dlouhého textu, tak ke konkrétnímu hash je teoreticky možné najít nekonečně mnoho původních textů. Kvalitní algoritmy pro výpočet hash jsou klasické jednocestné funkce. Tj. ke konkrétnímu hash je výpočetně obtížné najít nějaký povodní text.
Kvalitní jednocestné funkce pro výpočet hash by měly dát výrazně jiný výsledek při drobné změně původního textu. Počítáme-li např. hash z textu nesoucího platební příkaz, pak by bylo nemilé, kdyby se nám po připsání nuly k převáděné částce hash nezměnil. Ale k tomuto problému se dostaneme u elektronického podpisu.
Hashovací
funkce jsou konstruovány na výpočetních operacích nízké úrovně (především
bitové operace a posuny) a jsou tedy výpočetně velmi rychlé a efektivní.
Hashovací
algoritmy nejsou v žádném případě šifrovacími algoritmy (už vzhledem
k nejednoznačnosti – obecně neexistuje inverzní funkce), ale používají se
v roli kvalitního “otisku prstu dat” (fingerprint).
![]()
4 Autentizace uživatele a autorizace dat bez využití asymetrické kryptografie
Mnohdy se autentizace uživatele spojuje s přihlášením uživatele k počítačovému systému. V dnešní době problém autentizace uživatele je aktuální problém pro internetové aplikace, které používá široká veřejnost. A tak pro volbu autentizace začínají platit i kritéria, která byla dříve spíše v pozadí. Jedná se např. o cenu autentizačních pomůcek či komplikovanost autentizace pro klienta. Stačí se nad problémem zamyslet prakticky: je rozdíl v tom, nakupuje-li firma autentizační kalkulátory v ceně několika set Kč pro padesát zaměstnanců nebo pro dvacet tisíc svých klientů.
Na komplikovanost autentizace je možné se dívat ze dvou pohledů: z pohledu pracnosti a z pohledu nároků na znalosti nutné k provádění autentizace. Mechanická pracnost vstupuje do hry např. při použití autentizačních kalkulátorů, kdy klient musí do kalkulátoru a z kalkulátoru přepisovat data (i když u optických klíčů je možné část tohoto přenosu automatizovat). Při použití digitálního podpisu je autentizace pro uživatele mechanicky jednoduchá, avšak uživatel musí pochopit princip digitálního podpisu, musí obnovovat certifikáty atd.
Autentizace uživatele je možné provést na základě:
- Že uživatel něco ví (heslo).
- Že uživatel něco má (autentizační kalkulátor, čipovou kartu či v poslední době mobilní telefon).
- Že uživatel má nějaké biometrické vlastnosti (otisky prstů, struktury oční sítnice či duhovky, tvar obličeje, rozpoznávání hlasu a mnohé další vlastnosti, které znáte z detektivek a podobné literatury).
Snaha je jednotlivé uvedené metody kombinovat.
4.1 Hesla
Heslo, které se používá vícenásobně, asi všichni znají. Již asi méně známé je, že přístupové heslo na straně serveru nebývá uchováváno v čisté textové podobě, ale znehodnocené jednocestnou funkcí proti zneužití správcem systému.
V okamžiku, kdy uživatel zadá heslo, aby se autentizoval, tak systém zavolá na zadané heslo jednocestnou funkci a výsledek se porovná s údajem uloženým v systému. Algoritmů jednocestných funkcí je celá řada.
Např. v operačním systému UNIX se ukládají jednocestně znehodnocená hesla, kde jednocestný algoritmus je založen na symetrické šifře. Šifruje se stále stejný text (např. samé nuly), ale jako šifrovací klíč slouží právě heslo. Nepříjemné je, že dva uživatelé si mohou zadat stejné heslo, pak by měli i stejný údaj uložený v systému. Tato vada se odstraňuje tím, že do jednocestné funkce vstupuje další číslo – tzv. sůl. Toto číslo při generaci hesla automaticky generuje systém. Sůl se ukládá společně s heslem znehodnoceným jednocestnou funkcí. Při ověřování hesla tak do výpočtu vstupuje heslo a sůl – výsledek se pak porovná s údajem uloženým v systému.
4.2 Jednorázová hesla
Jednorázová hesla řeší problém odposlechu hesla během jeho přenosu sítí a následným použitím odposlechnutého hesla. Jednorázová hesla se nepoužívají pouze u aplikací provozovaných v počítačových sítích, ale i u tak odlišných aplikací jako je CallCentrum, kdy je nutné autentizovat uživatele, který požaduje služby běžným telefonem.
Jak je to vlastně možné, že uživatel může pokaždé zadat jiné heslo? Algoritmů na tvorbu jednorázových hesel je celá řada.
4.2.1 Seznam jednorázových hesel
Nejjednodušší metodou jednorázových hesel je seznam jednorázových hesel. V tomto případě, je vygenerován seznam hesel, který může být vytištěn na papír a předán uživateli (resp. zaslán uživateli bezpečnou elektronickou poštou). Stejný seznam existuje i na straně systému, kde mohou být i jednotlivá jednorázová hesla znehodnocena jednocestnou funkcí.
Uživatel pak pro svou autentizaci zadává jedno heslo po druhém. Po zadání hesla si zadané heslo škrtne ze seznamu.
Jednorázová hesla mohou být v seznamu i očíslována. Systém pak může ve výzvě pro zadání hesla napovědět uživateli jaké heslo má zadat.
Po vyčerpání seznamu musí být uživateli vygenerován a předán další seznam. Další nevýhodou seznamu hesel je, že si jej uživatel těžko může zapamatovat, a tak jej musí nosit s sebou v tištěné či elektronické podobě. Může se tak snadno stát, že uživatel seznam jednorázových hesel zapomene např. v i-kavárně.
Seznamy jednorázových hesel se často kombinují s klasickým heslem. Uživatel pak zadává heslo skládající se ze dvou částí: z klasického (vícenásobného) hesla a z jednorázového hesla. Tím se komplikuje využití seznamu jednorázových hesel zapomenutého v i-kavárně a na druhou stranu se i komplikuje použití odposlechnutého hesla.
Jinou možností používání jednorázových hesel je jednotlivá hesla očíslovat a nevyžadovat hesla jedno po druhém, ale náhodně. Náhodný výběr hesel může být i s opakováním, tj. pak se v podstatě nejedná o „jednorázové heslo“, ale požadavek na výběr dvou stejných hesel v pro útočníka zajímavém čase je málo pravděpodobný.
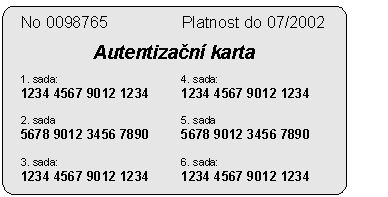 Pro některé aplikace je dostatečná i
autentizační karta. Jedná se o plastikovou kartičku bez magnetického proužku a bez čipu s několika předtištěnými
sadami čísel.
Pro některé aplikace je dostatečná i
autentizační karta. Jedná se o plastikovou kartičku bez magnetického proužku a bez čipu s několika předtištěnými
sadami čísel.
Obr. 4-1 Autentizační karta
Princip použití spočívá v tom, že aplikace vygeneruje dotaz na zadání několika náhodně vybraných čísel vytištěných na kartě. Např. v podobě "zadejte třetí čtveřici čísel ze čtvrté sady vytištěných na Vaší Autentizační kartě".
Autentizační karta je forma použití vícenásobných hesel s jednoduchým doplňkem vzdáleně připomínajícím heslo na jedno použití.
Výhodou tohoto prostředku jsou jeho zanedbatelné pořizovací náklady, kterými jsou získány velmi zajímavé bezpečnostní vlastnosti.
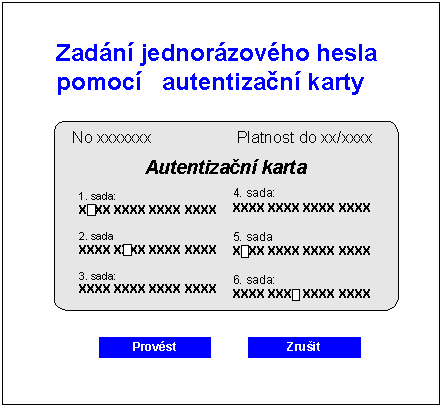
Obr. 4-2. Zadání jednorázového hesla pomocí autentizační karty
4.2.2 Rekurentní algoritmus
Rekurentní algoritmus používá některý z algoritmů pro výpočet kontrolního součtu. Zvolme si jeden z těchto jednocestných algoritmů a označme jej F. Dále si uživatel musí sám zvolit nějaký řetězec násada. Tento řetězec uživatel nikomu nesděluje – je to uživatelovo tajemství.
Kontrolní součet z řetězce násada vyjádříme jako:
F(násada).
Použijeme-li algoritmus F dvakrát opakovaně na tutéž zprávu, tj. F(F(násada)), pak budeme psát:
F2(násada)
a obdobně
Fn(násada)
bude znamenat, že jsme použili algoritmus F na řetězec násada celkem n-krát.
Použití této metody spočívá též nejprve v inicializačním kroku. Uživatel si pořídí text násada (případně si jej zašifruje pomocí PINu).
V inicializačním kroku se uživatel a správce aplikace dohodnou na čísle, např. 1000. Uživatel vyrobí:
F1000(násada) a předá jej správci aplikace.
Správce aplikace si do databáze k našemu uživateli poznamená název algoritmu pro výpočet kontrolního součtu (tj. F), číslo 1000 a F1000(násada). Správce tedy nezná text násada (je to uživatelovo tajemství).
Při autentizaci pošle uživatel na server jméno, server ve své databázi zjistí, jakou uživatel používá autentizační metodu. Obratem server uživateli pošle dotaz obsahující číslo (n-1), tj. nyní 999. Uživatel vygeneruje odpověď F999(násada) a odešle to jako jednorázové heslo serveru.
Server prověří totožnost uživatele, takže provede porovnání
F(F999(násada)) = F1000(násada)
Algoritmus F je mu
znám a F1000(násada) má
uloženo v konfiguračním souboru a F999(násada) obdržel
v odpovědi uživatele.
Po úspěšném prověření uživatele uloží server do konfiguračního souboru místo hodnoty F1000(násada) hodnotu F999(násada) a místo čísla 1000 číslo 999. Při další autentizaci se vše provádí s číslem o jedničku nižším, tj. provádí se autentizace:
F(F998(násada)) = F999(násada)
Uživatel mohl tedy vygenerovat celkem 999 hesel na jedno použití, pak musí změnit hodnotu řetězce násada a správci serveru předat nový F1000(násada).
Ještě bychom se měli vrátit k procesu, kdy uživatel předává správci aplikace číslo n a hodnotu Fn(násada). Tyto údaje sice může předat osobně, ale to není příliš praktické. Uživatel totiž pravděpodobně nepřijde do styku se správcem aplikace, ale s obchodním útvarem provozovatele aplikace. V případě, že by autentizační údaje procházely mnoha rukama, tak je nebezpečí zneužití těchto údajů. Jednodušší je, aby obchodní útvary předaly klientovi jednorázové heslo (např. v zalepené obálce) a uživatel se při první autentizaci prokázal tímto jednorázovým heslem a přitom předal aplikaci i číslo n a hodnotu Fn(násada). Obdobně může dojít i k reinicializaci po dosažení n=1.
4.2.3 S/KEY
Algoritmus S/KEY je implementací rekurentního algoritmu. S/KEY je popsán v RFC-1760. Jádrem je použití algoritmu pro výpočet kontrolního součtu MD4 (MD4 je popsán v RFC-1320).
Násadu si klient volí sám tak, aby byla dlouhá minimálně 8 bajtů.
Algoritmus MD4 produkuje 16 bajtů dlouhý kontrolní součet. Ten se v tomto případě dělí na dvě poloviny po 8 bajtech, které se spojí operací XOR do výsledných osmi bajtů. Použijeme-li terminologii z předchozího paragrafu, pak algoritmem F je algoritmus MD4, jehož výsledek se dělí na dvě poloviny, které jsou operací XOR sloučeny do výsledných osmi bajtů.
S/KEY má nápadité rozšíření umožňující použít stejný algoritmus (včetně stejné násady) pro více aplikací (např. pro více serverů). Princip spočívá v tom, že aplikace (server) vyzývající uživatele k prokázání své totožnosti (k autentizaci) klientovi zobrazí tři údaje:
- Informaci, že se používá algoritmus S/KEY.
- Číslo n kolikrát má uživatel aplikovat algoritmus F.
- Sůl, což je řetězec vygenerovaný serverem a zasílaný uživateli nezabezpečeně jako součást výzvy. Právě solí se budou výzvy jednotlivých aplikací lišit.
Uživatel nejprve spojí násadu se solí a výsledný řetězec teprve použije jako násadu pro algoritmus F.
4.2.4 OTP (One Time Password)
OTP je popsáno v RFC-1938, které rozšiřuje mechanismus S/KEY o možnost použití dalších algoritmů pro výpočet kontrolního součtu, jako jsou např. algoritmy MD5 (popsaný v RFC-1321) a SHA-1.
4.2.5 Sdílené tajemství
Jednorázové heslo vytvořené za využití sdíleného tajemství opět využívá jednocestnou funkci jako je např. hash. Mechanismus autentizace je ale odlišný. Z bezpečnostního hlediska má tento typ autentizace jednu nepříjemnou vlastnost. Obě strany znají společné sdílené tajemství, takže jedna strana může podezírat druhou, že tento mechanismus zneužila. Prokazuje-li např. klient svou totožnost vůči serveru. Pak klient může tvrdit: „To jsem nebyl já, kdo prokazoval svou totožnost, to byl správce serveru, který má přístup ke společnému sdílenému tajemství se přihlašoval místo mne“. Toto zpochybnění nepřichází v úvahu u rekurentního algoritmu (násadu zná pouze klient) ani u asymetrické kryptografie. Vraťme se však k autentizačnímu algoritmu na bázi sdíleného tajemství, který využívá např. SSL/TLS. Popíšeme se jej podle obr. 4-3.
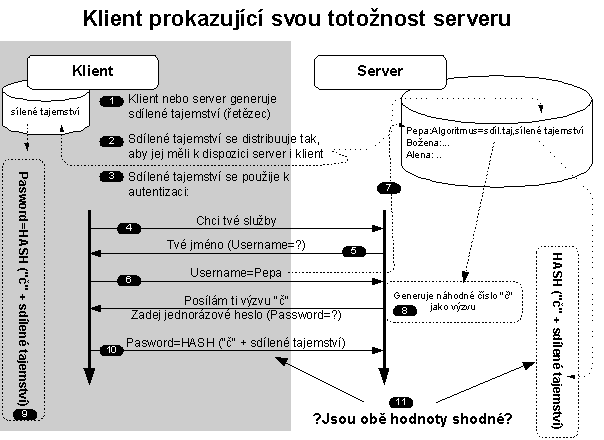
Obr. 4-3 Autentizace za využití sdíleného tajemství
Ještě předtím než se budeme moci využívat mechanismus autentizace, tak jedna strana vygeneruje nějaký řetězec nazývaný sdíleným tajemstvím (1). Sdílené tajemství se předá druhé straně (2). V tomto okamžiku obě strany sdílí společné tajemství (3) a může se začít s autentizací (s generováním jednorázových hesel).
Pro názornost si představíme, že klient prokazuje svou totožnost (autentizuje se) serveru. Klient naváže komunikaci se serverem (4). Server se klienta zeptá na jeho jméno (4). Klient serveru sdělí své přihlašovací jméno (5). Server ve své databázi uživatelů najde klienta zadaného přihlašovacího jména (7) a zjistí, že používá algoritmus na bázi sdíleného tajemství (v databázi by byla uvedena i konkrétní jednocestná funkce – např. MD-5). Jelikož server zjistil, že klient k prokázání své totožnosti používá tento algoritmus, tak server vygeneruje náhodné číslo „č“ (8), které zasílá jako výzvu klientovi. Klient vezme přijaté číslo „č“ a sřetězí jej se sdíleným tajemstvím. Z výsledku spočte hash (9). Tento hash tvoří jednorázové heslo, které zašle serveru (10).
Server zná jak společné sdílené tajemství, tak i číslo „č“. Umí tudíž spočíst stejný hash. Nyní stačí porovnat hash spočtený klientem s hash, který spočetl server. Pokud jsou oba stejné, pak klient prokázal svou totožnost.
Obdobný mechanismus lze použít i jako důkaz pravosti dat (autorizaci dat). Mechanismus si popíšeme na případu bankovního platebního příkazu podle obr. 4-4.
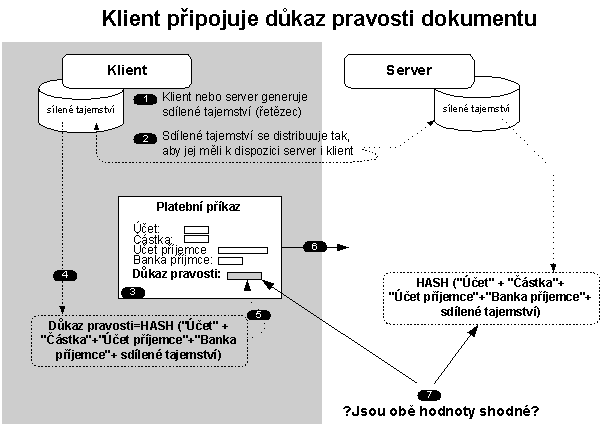
Obr. 4-4 Důkaz pravosti dat
Na počátku se opět vygeneruje sdílené tajemství (1), které se distribuuje tak, aby jej měli k dispozici obě strany (2).
Klient pak např. v Internetové kavárně vyplňuje webový formulář s platebním příkazem (3) na anonymním webu banky (anonymní HTTPS). Jenže takový příkaz by mohl udělat každý, takže je k příkazu nutné přídat i nějaký důkaz, že příkaz vydal majitel účtu. Takový důkaz se vytvoří na základě sdíleného tajemství mezi serverem a majitelem účtu (klientem). Jedná se ve své podstatě o jednorázové heslo přeneseně označované též jako „symetrický elektronický podpis“.
Klient sřetězí důležitá pole platebního příkazu se sdíleným tajemstvím a z výsledku spočte hash. Tento hash bude právě tvořit důkaz pravosti, který klient vloží do příslušného pole webového formuláře (5). Formulář odešle na server (6). Server si v databázi klientů (majitelů účtů) zjistí sdílené tajemství a z polí obdrženého formuláře rovněž spočte hash. Nyní server porovná jestli serverem spočtený hash je shodný s hash z obdrženého webového formuláře, když ano, pak je platební příkaz odeslaný opravdu majitelem účtu (nebo někým komu majitel účtu prozradil sdílené tajemství). Je tu opět problém, že z vyzrazení sdíleného tajemství může klient obvinit banku.
4.2.6 Autorizace dat
Při autentizaci se prokazuje totožnost. Již jsme se však zmínili, že je mnohdy třeba ověřovat pravost předávaných dat. Ověřování pravosti má dva aspekty:
- Ochrana před útočníkem, který data mění na cestě od odesilatele k příjemci.
- Ochrana příjemce před popřením pravosti odeslaných dat odesilatelem. Tuto ochranu je schopen zajistit pouze digitální podpis, kterým se budeme zabývat v následujících kapitolách.
První jednodušší případ autorizace dat (ochrana před útočníkem) je možné zajistit i jednoduššími prostředky než je digitální podpis. Digitální podpis není vždy vhodné nebo možné použít.
Pro takovouto autorizaci přenášených dat se opět používá některý z algoritmů pro výpočet kontrolního součtu. Odesílatel a příjemce se předem dohodnou na nějakém řetězci, který zají pouze oni – na sdíleném tajemství.
Přenášená data se rozdělí do bloků. Každý přenášený blok se doplní o kontrolní součet, který je počítán z přenášeného bloku dat a sdíleného tajemství. Jak se konkrétně tento kontrolní součet počítá, to závisí na konkrétní normě. Příkladem takové normy je např. RFC-2104 (HMAC: Keyed-Hashing for Message Authentication). Jinými příklady jsou protokoly SSL a TLS, kterým je věnována samostatná kapitola.
Sdílené tajemství je sdíleno mezi odesilatelem a příjemcem (nikdo jiný jej nezná). Sdílené tajemství je cosi podobného jako je symetrický šifrovací klíč, nepoužívá se k šifrování, ale spojuje se s přenášeným blokem dat, aby se z toho výsledku spojení spočetl kontrolní součet.
Kdyby útočník chtěl změnit blok přenášených dat, pak by musel dopočítat i kontrolní součet, ten ale není schopen spočíst, protože nezná sdílené tajemství.
4.2.7 Autentizační kalkulátory
Autentizační kalkulátory jsou elektronické pomůcky pro autentizaci klienta (případně pro autorizaci dat zadaných uživatelem). Autentizační kalkulátory zpravidla umí některý z kvalitních algoritmů pro kontrolní součet (např. MD5, SHA-1 apod.).
Uživatel obdrží od správce aplikace autentizační kalkulátor, avšak před tím je třeba autentizační kalkulátor připravit (tj. je třeba provádět management autentizačních kalkulátorů).
Příprava spočívá v tom, že do kalkulátoru se vloží tajemství, které je nazýváno násada. Tajemství je řetězec, který bude uložen v kalkulátoru na serveru aplikace (nikdo jiný toto sdílené tajemství mezi klientem a aplikací nezná). V databázi na serveru musí tak být pro každého uživatele udržována informace obsahující mj. sdílené tajemství. Před předáním kalkulátoru klientovi musí někdo tajemství do kalkulátoru naplnit . Dále je třeba ošetřit ztráty kalkulátorů a recyklaci kalkulátorů v případě vrácení kalkulátoru ošetřit jeho recyklaci (mj. vymazání tajemství).
V případě, že je použit symetrický šifrovací algoritmus, pak toto tajemství se použije jako šifrovací klíč.
Rozlišujeme tak kalkulátory:
? Určené pouze pro autentizaci klienta.
? Určené též pro autorizaci dat zadávaných uživatelem.
Uvedli jsme, že kalkulátory využívají jednocestné funkce – např. funkce pro výpočet kontrolních součtů apod. Detailní popis použitého algoritmus nebývá u autentizačních kalkulátorů zveřejňován – výrobci kalkulátorů jej často považují za své vlastnictví. Dodavatel kalkulátorů zpravidla dodává nejen samotné kalkulátory, ale i software, který je volán aplikací v případě autentizace.
4.2.7.1 Kalkulátory určené pouze pro autentizaci klienta
Čas
Uživatelův autentizační kalkulátor obsahuje hodiny. Čas s přesností na minuty (resp. poloviny minuty) je vstupem pro kalkulátor. Heslo na jedno použití se vytvoří jako kontrolní součet (např. algoritmem MD5) z času a sdíleného tajemství.
Pokud na serveru banky běží stejný čas, pak stejnou operaci je schopna provést i aplikace (tajemství je sdíleno mezi uživatelem a aplikací). Hodnotu získanou od klienta server porovná s hodnotou spočítanou aplikací - pokud jsou obě stejné, pak je klientovi umožněn přístup.
Uživatelův autentizační kalkulátor může být dvojího provedení:
1. Bez klávesnice. Pak se nepoužívá PIN. Heslo se každou minutu (resp. polovinu minuty) na displeji automaticky mění. (Typ bez klávesnice je oblíben zejména u top managementu pro svou primitivnost obsluhy).
2. S klávesnicí, aby bylo možné pořídit PIN. V tomto případě je sdílené tajemství v kalkulátoru uloženo zašifrováno PINem. Pro přístup k tajemství je tak nutné zadat PIN.


Otázkou je, co v případě, že oba řetězce nejsou shodné. Neshoda může být způsobena tím, že se hodiny kalkulátoru rozcházejí s hodinami v serveru aplikace. Server v takovém případě vypočítá některé hodnoty o několik minut vpřed i vzad a hledá, nedojde-li tam ke shodě. Dojde-li ke shodě např. s časem o 2 minuty zpět, pak uživateli též umožní přístup a do konfiguračního souboru si poznamená časový posun.
Challenge -
Response
Server vygeneruje náhodný řetězec jako dotaz (Challenge). Klient tento náhodný řetězec spojí se sdíleným tajemstvím a z takto vytvořeného celku spočte kontrolní součet, který vrátí jako jednorázové heslo (Response) serveru (viz kap. 4.2.6). Jelikož server též zná sdílené tajemství, tak je schopen stejné jednorázové heslo též spočíst. Oba výsledky porovná a pokud jsou shodné, tak klientovi umožní přístup do aplikace.
Důležité je, aby se nezopakoval v krátkém časovém intervalu stejný dotaz. Je třeba použít kvalitní systém na generování dotazů (dotaz může být např. zřetězením času a náhodného čísla apod.).
Prakticky: klient zapne kalkulátor, zadá PIN, čímž si otevře přístup ke sdílenému tajemství. Aplikace klientovi zobrazí dotaz, klient jej pořídí na klávesnici kalkulátoru. Kalkulátor k dotazu připojí tajemství a spočte kontrolní součet - vytvoří jednorázové heslo. Klient opíše z displeje kalkulátoru heslo do okna aplikace a odešle jej na server.
Zjednodušeně lze říci,
že podobný mechanismus se použije i při autentizaci klienta pomocí asymetrické
kryptografie. Server vygeneruje náhodné číslo a klient vrátí digitální podpis
tohoto čísla. V případě elektronického podpisu se však využije soukromý
klíč, který má pouze autentizovaný. Tj. drůhá strana nemůže být podezírána
z podvrhu.
4.2.7.2 Kalkulátory umožňující i autorizaci příkazů
Kalkulátory určené pouze pro autentizaci počítaly kontrolní součet z času či náhodného čísla nebo použily rekurentní algoritmus.
V případě autorizace příkazu je nutné počítat kontrolní součet také z jednotlivých položek předávaných dat. Zpravidla se nepočítá kontrolní součet ze všech polí, ale pouze z těch nejdůležitějších. Která pole jsou ta nejdůležitější je věcí tvůrce aplikace.
Zatímco v případě autentizace klienta mechanismem Challenge - Response byl nucen klient pořídit na klávesnici kalkulátoru PIN a několikaciferný dotaz, tak při autorizaci příkazu je nutné pořídit na klávesnici kalkulátoru také jednotlivá pole příkazu (alespoň ta důležitá).
Prakticky: klient zapne kalkulátor, zadá PIN, čímž si otevře přístup ke sdílenému tajemství. Např. pomocí web-formuláře bude chtít zadat platební příkaz, pak kromě běžných polí platebního příkazu musí klient zadat i jednorázové heslo do dalšího pole. Klient pořídí platební příkaz do web-formuláře, ale nyní potřebuje vygenerovat jednorázové heslo, takže pořídí platební příkaz (určená důležitá pole příkazu) ještě jednou do autentizačního kalkulátoru. Kalkulátor zobrazí na displeji jednorázové heslo, které klient opíše do posledního nevyplněného pole web-formuláře a formulář odešle.
Významnou výhodou autentizačních kalkulátorů je jejich naprostá nezávislost na bezpečnosti prostředí. V tomto směru se jedná o zařízení, které má nesporné bezpečnostní přednosti. U některých klientů však není populární jednak nosit stále s sebou kalkulátor a jednak dvakrát pořizovat stejný příkaz.
Problém dvojího pořizování dat lze technicky řešit pomocí tzv. optického klíče. Uživatel pořídí data jednou na formulář na PC. Program na PC odvysílá pořízená data do autentizačního kalkulátoru, který spočte jednorázové heslo a zobrazí jej na displeji. Uživatel opíše jednorázové heslo z displeje kalkulátoru na PC. Otázka je jak PC odvysílá data do kalkulátoru. Optický klíč pracuje tak, že program na obrazovce PC otevře zvláštní okno, kde přenášenou informaci moduluje do zobrazování obrazců, které přijímá optický klíč. Jinou určitě bezpečnější cestou by bylo pořídit data na kalkulátoru a pomocí IR-portu je přenést do PC.
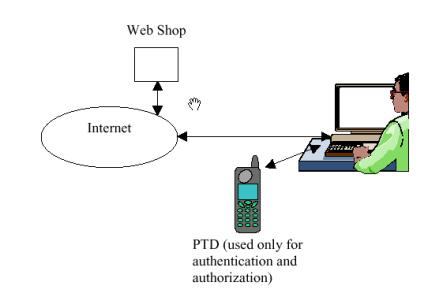
4.2.8 Jednorázová hesla přes GSM
Nevýhodou autentizačních kalkulátorů je samotná existence kalkulátoru, tj. z hlediska provozovatele aplikace se kalkulátor musí pořídit, což není laciné, a z hlediska uživatele je zase nepříjemné, že se kalkulátor musí stále nosit s sebou a přitom je dobré jej nezničit či neztratit. Naopak mobilní telefon má dnes téměř každý a uživatelé jsou zvyklí jej s sebou nosit a starat se o něj a navíc si mobilní telefon pořizuje uživatel sám.
Že by mobilní telefon přímo nahradil autentizační kalkulátor je málo pravděpodobné. Nabízí se ale jiné použití. V okamžiku, kdy se klient má autentizovat, tak oznámí aplikaci své přihlašovací jméno. Aplikace vygeneruje jednorázové heslo a v databázi uživatelů najde číslo mého mobilního telefonu, na které pomocí SMS-zprávy jednorázové heslo zašle.
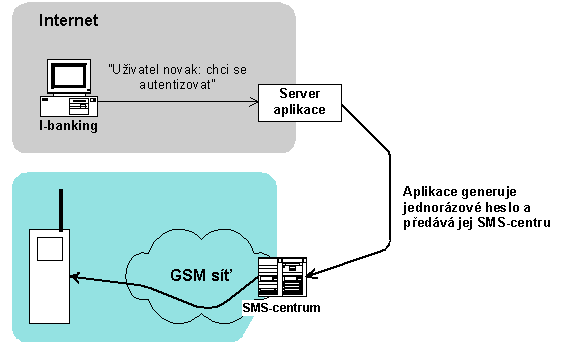
Obr. 4-5 Jednorázové heslo zasílané přes GSM
Tento způsob autorizace kombinuje dva nezávislé komunikační kanály. Tato skutečnost podstatným způsobem omezuje možnost zneužití, protože případný útok by musel být veden společně na oba nezávislé kanály, což je vysoce náročné. Další podstatnou výhodou jsou nízké pořizovací náklady a relativně jednoduchá obsluha. Jistým omezením tohoto řešení je, že klient musí být vybaven mobilním telefonem a že tento pracuje pouze v místě, kde má dostupný signál.
![]()
5 Symetrické šifry
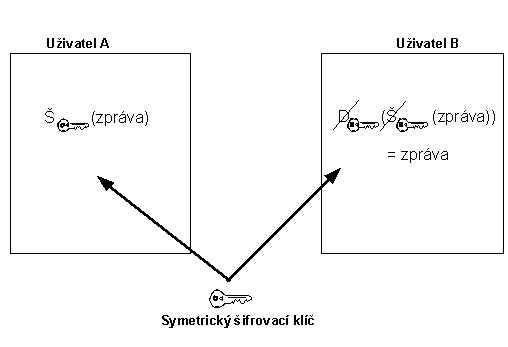
V případě symetrických šifer si uživatelé, kteří spolu chtějí šifrovaně
komunikovat, musejí předem nějakou cestou vyměnit symetrický šifrovací klíč.
Slovo „symetrický“ vyjadřuje skutečnost, že tentýž klíč (tatáž informace) se
používá k šifrování i k dešifrování zpráv.
Obr. 5-1 Symetrická šifra
Pokud např. uživatel A (viz obr. 5-1) bude chtít zaslat zprávu „zpráva“ uživateli B, tak aby během přenosu zprávy se nemohl útočník dostat k obsahu zprávy, tak uživatel A využije k šifrování symetrický klíč, který si předem s uživatelem B vyměnili.
Uživatel B příjme zprávu šifrovanou symetrickým šifrovacím klíčem a k jejímu dešifrování použije stejný klíč. Jak je znázorněno na obr. 5-1, dešifrování „požere“ šifrování a uživatel B získá původní zprávu.
Symetrických šifrovacích algoritmů je celá řada. Snad nerozšířenějším je algoritmus DES používající šifrovací klíč délky 56 bitů. Dnes se však považuje za nedostatečný. Z algoritmu DES byl odvozen algoritmus 3DES sklíčem 112 bitů. Dále se často používají algortimy s délkou klíče 128 bitů (IDEA, RC2 atd.). Na obzoru je praktické používání algortmů s délkou klíče 256 b.
Je však třeba připomenout, že donedávna k nám bylo díky exportním omezením USA povoleno importovat pouze zmrzačený software využívající symetrické algoritmy s délkou klíče do 40b (např. RC2 zmrzačený na 40b).
Jedná se vesměs blokové šifry. Tj. data se šifrují/dešifrují po blocích zpravidla dlouhých 8B. Pokud vstupující data jsou krtatší, pak se musí nějak dorovnat na 8B. I když útočník nevidí do šifrovaného textu, tak by hypoteticky mohl útčit tak, že by zaměnil pořadí jednotlivých zašifrovaných bloků. Tomu se šifry brání vázáním po sobě následujících bloků. Hovoříme o tzv. módu šifry, který zajišťuje že snadno nelze přehazovat jednotlivé bloky. Často používaným médem je např. mód CBC či ECB. Pokud chceme vyjádřit to, že máme namysli šifrovací algortimus s konkrétním módem, pak říkáme např DES-CBC či DES-ECB. Nebo IDEA-CBC či IDEA-ECB.
![]()
6 Asymetrické algoritmy
Tyto algoritmy používají dvojici klíčů. Jeden k šifrování (označuje se jako veřejný klíč) a jeden k dešifrování (označuje se jako soukromý klíč).
6.1 Diffe-Hellmanův algoritmus
Prvním asymetrickým algoritmem byl Diffie-Helmanův algoritmus. Tento algoritmus se nehodí k šifrování dat, proto jsem v nadpisu kapitoly 6 taktně neuvdel „asymetrické šifrovací algoritmy“.
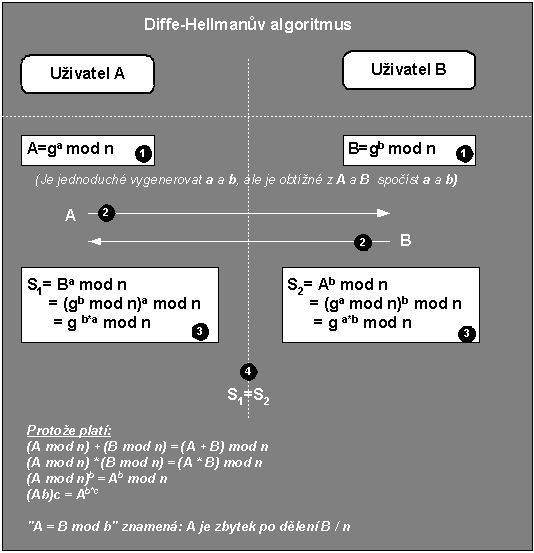
Obr. 6-1 Diffie-Hellmanův algoritmus
Diffe-Helmanův algoritmus je určen k výměně klíčů (key agreement). Pokud spolu chtějí šifrovaně komunikovat uživatelé A a B, pak si oba vygenerují čísla „a“ a „b“ (1), která si ponechají v tajnosti (jsou to jejich privátní čísla). Z těchto privátních čísel vygenerují veřejná čísla „A“ a „B“, která si vzájemně vymění přes nezabezpečený kanál jako je např. Internet (2).
Na základě svého tajného čísla a veřejného čísla protějšku se postupně spočtou čísla S1 a S2 (3). Zajímavým zjištěním je, že S1=S2. Takže obě strany došly ke společnému číslu S. K výpočtu tohoto čísla vždy potřebuji: veřejné číslo protější strany a své soukromé číslo. Tj. pro nějakou třetí stranu určit číslo S je velice obtížné.
Číslo S pak mohu použít např. jako symetrický šifrovací klíč pro šifrování komunikace mezi uživateli A a B. Toto použití je jádrem IPsec. Číslo S však také mohu použít jako sdílené tajemství ve smyslu kap. 4.2.5 ... .
6.2 Algoritmus RSA
Algortimus
RSA se naopak hodí i pro šifrování dat. Ale také se hodí pro elektronický
podpis (jak uvidíme dále).
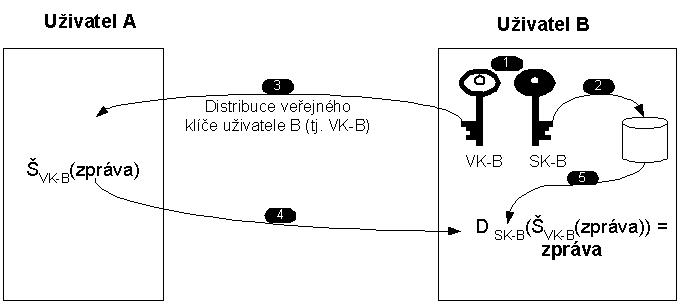
Obr. 6-2 Algoritmus RSA
Pokud chce uživatel A použít algoritmus RSA k šifrování zprávy zasílané uživateli B, pak:
1. Uživatel B, tj. příjemce zprávy si musí vygenerovat dvojici klíčů: veřejný klíč (VK-B) a soukromý klíč (SK-B).
2. Uživatel B si uloží svůj soukromý klíč do důvěryhodného úložiště klíčů. Např. na disk, na čipovou kartu atd. Soukromý klíč je aktivem uživatele, které si uživatel musí střežit.
3. Uživatel B distribuuje svůj veřejný klíč VK-B do celého světa. Tak se VK-B dostane i k uživateli A.
4. Uživatel A konečně může šifrovat zprávu uživateli B. Šifruje ji právě veřejným klíčem VK-B.
5. Uživatel B (příjemce) dešifruje přijatou zprávu svým soukromým klíčem SK-B a získá původní zprávu.
Základní vlastností šifrování na bázi asymetrických algoritmů je skutečnost, že je relativně jednoduché za využití veřejného klíče šifrovat text, ale na základě znalosti veřejného klíče a veřejným klíčem šifrované zprávy je velice obtížné získat původní zprávu.
Délka šifrovacích klíčů pro algoritmus RSA se tč. považuje za ještě bezpečnou pokud je alespoň 1024. Často se však používají klíče dlouhé 2 nebo i 3 K. Algoritmus RSA tedy používá klíče, které jsou o řád delší než klíče se kterými jsme se setkali u symetrických šifer.
6.3 Elektronická obálka
Šifrování je vždy operací do které vstupují šifrovaná data a šifrovací klíče. Pokud jsou klíče extrémně dlouhé pak tyto operace trvají dlouho (často ani nelze použít standardní aritmetické operace programovacích jazyků, protože operandy jsou příliš dlouhé). Proto je šifrování např. algoritmem RSA pomalé.
Řešením tohoto problému je elektronická obálka. Odesilatel zašifruje zprávu náhodným symetrickým klíčem což je rychlá operace. A k takto šifrované zprávě jen přibalí náhodný symetrický šifrovací klíč zašifrovaný veřejným klíčem příjemce. Takže asymetricky šifruje pouze kraťoučký symetrický klíč. Výsledek je velice rychlý a efektivní. Má to ještě jeden pozitivní efekt. Pokud zprávu posíláme více adresátům, pak ji šifrujeme pouze jednou náhodným šifrovacím klíčem a každému adresátovi ke zprávě přibalíme symetrický klíč zašifrovaný jeho veřejným klíčem.
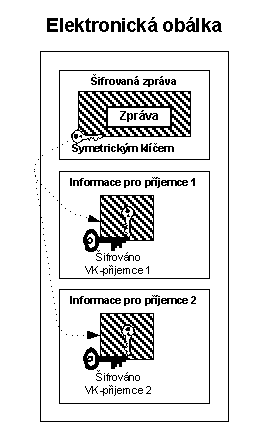
Obr. 6-3 Zpráva v elektronické obálce, která je určena dvěma adresátům
6.4 Elektronický podpis
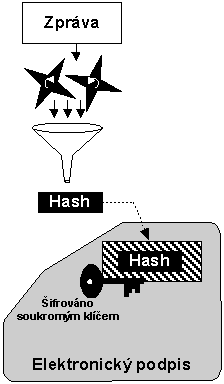 Elektronácký
podpis je mechanismus, kterým se zajišťuje důkaz pravosti dat (dokumentů). Elektronický podpis se vytváří ve dvou
krocích:
Elektronácký
podpis je mechanismus, kterým se zajišťuje důkaz pravosti dat (dokumentů). Elektronický podpis se vytváří ve dvou
krocích:
1. Spočte se kontrolní součet (hash) z dokumentu.
2. Výsledný kontrolní součet se šifruje soukromým klíčem uživatele, který podpis vytváři. Soukromým klíčem šifrovaným hash ze zprávy se nazývá elektronickým podpisem zprávy.
Obr. 6-4 Vytváření elektronického podpisu
Na obr. 6-5 je pak znázorněna verifikace elektronického podpisu. Ta se provádí ve třech krocích:
1. Příjemce samostatně spočte kontrolní součet z přijaté zprávy.
2. Příjemce dešifruje přijatý elektronický podpis veřejným klíčem odesilatele.
3. Příjemce porovná výsledek získaný z bodu 1 s výsledkem získaného z bodu 2. Pokud jsou stejné, pak elektronický podpis mohl vytvořit pouze ten kdo vlastní soukromý klíč odesilatele – odesilatel.
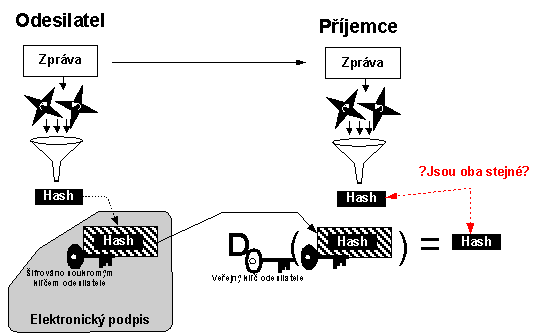
Obr. 6-5 Verifikace elektronického podpisu
Elektronický podpis provádí důkaz pravosti na základě vlastnictví soukromého klíče. Je tedy nutné, abychom si své soukromé klíče dobře střežili.
Na rozdíl od šifrování elektronický podpis použije klíč odesilatele (nikoliv příjemce jako u šifrování). Avšak odesilatel pro podpis použil svůj soukromý klíč. Mlčky jsme tedy předpokládali, že náš algoritmus umožňuje nejprve „dešifrovat“ soukromým klíčem a pak „šifrovat“ veřejným klíčem. Tj. že operace šifrování a dešifrování jsou zaměnitelné. Takovým algoritmem, který takovouto záměnu umožňuje je právě algoritmus RSA.
![]()
7 Využití asymetrické kryptografie
Autentizace
Autentizace na základě asymetrické kryptografie je vždy nějakou variací na situaci znázorněnou na obr. 6-6. Představme si, že policista chce, aby mu občan prokázal svou totožnost na základě asymetrické kryptografie.
Zatímco v klasickém případě občan prokazuje svou totožnost na základě občanského průkazu, který předloží policistovi. Policista v klasickém občanském průkazu ověřuje totožnost na základě občanovy fotografie. Tak v elektronickém případě občan prokazuje svou totožnost na základě vlastnictví svého soukromého klíče.
Princip prokazování totožnosti na základě asymetrické kryptografie je jednoduchý. Policista vygeneruje náhodné číslo č. Toto číslo č předá občanovi, který jej za pomoci svého soukromého klíče digitálně podepíše. Digitálně podepsané číslo č předá občan policistovi, který provede verifikaci digitálního podpisu.
Pro občana se tak základem stává ochrana jeho soukromého klíče. Odcizení soukromého klíče by způsobilo to, že zloděj by se mohl elektronicky prokazovat místo majitele soukromého klíče. Odcizení soukromého klíče lze přirovnat v případě klasických občanských průkazů k odcizení podoby z fotografie občanského průkazu.
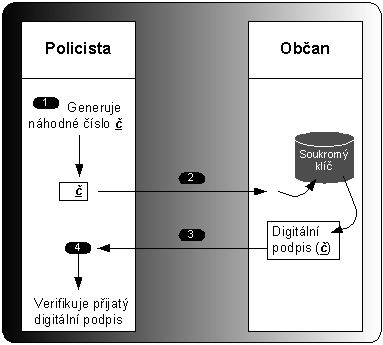
Obr. 6-6. Autentizace za využití asymetrické kryptografie
Na obr. 6-6 jsme si vysvětlili jak se používá elektronický podpis k autentizaci klienta. Kdyby byl policista falešný, pak by mohl místo náhodného čísla vygenerovat např. platební příkaz klienta ve svůj prospěch (obr 6-7).
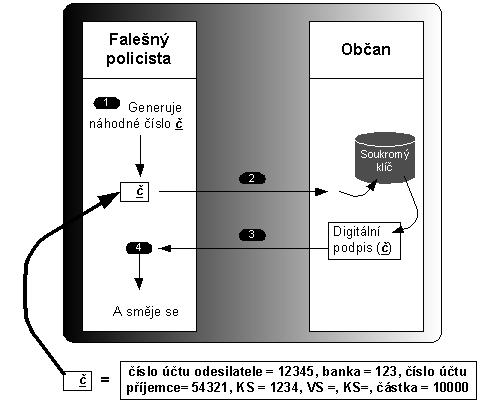
Obr 6-7 Použitím soukromého klíče pro autentizaci by mohlo dojít k nechtěnému podpisu v neprospěch uživatele.
Jinými slovy: je předepsáno: pokud se vystavuje dvojici veřejný/soukromý klíč pro pro elektronický podpis, pak je třeba zamezit tomu, aby tyto kíčr bylo možné použít k něčemu jinému než k podpisu.
Autorizace dat
Autorizace dat na základě asymetrické kryptografie se nazývá digitálním podpisem dat.
7.1.1 Uložení soukromého klíče na disku
Uložení soukromého klíče do souboru na disku je praktické, protože jej pak lze přenášet mezi počítači. Nevýhoda spočívá v tom, že diskový soubor lze poměrně snadno zcizit. Proti tomu jsou soukromé klíče chráněny šifrováním a jejich použití je možné pouze se znalostí vícenásobného přístupového hesla, které slouží jako šifrovací klíč. To je pro prostředí kontrolované klientem dostatečné. Nebezpečí ale stále spočívá v aplikacích typu trojský kůň, které mohou být schopny zjistit přístupové heslo klíče nebo přečíst přímo rozšifrovanou podobu klíče ve chvíli, kdy je v paměti používána. Takové trojské koně mohou být staženy např. z Internetu nebo získány elektronickou poštou.
7.1.2 Hardwarový klíč
Hardwarovým klíčem je označeno technické zařízení, které poskytuje bezpečnostní funkce spojené s podporou digitálního podpisu. Na rozdíl od autentizačních kalkulátorů je nutné hardwarový klíč připojit k počítači, který je vybaven příslušným rozhraním. Takovým nástrojem může být např. čipová karta či USB zařízení. Hardwarový klíč je jedním z nejbezpečnějších východisek pro autentizaci a autorizaci do budoucnosti.
Dnešní hardwarové klíče uchovávají soukromý klíč tak, že soukromý klíč nikdy neopouští hardwarový klíč. Tj. hardwarový klíč:
· generuje dvojici veřejný/soukromý klíč
· generuje podklady pro žádost o certifikát
· vydaný certifikát lze uložit opět do hardwarového klíče
· v případě použití soukromého klíče aplikace vyšle data do hardwarového klíče, a hardwarový klíč provede šifrování soukromým klíčem uloženým v hardwarovém klíči.
Pokud se nakupují hardwarové klíče, tak je třeba ověřit, zda-li dodavatel garantuje skutečnost, že soukromý klíč nikdy neopouští hardwarový klíč. V případě, že by soukromý klíč mohl opustit hardwarový klíč, pak se hardwarový klíč stane pouze nosičem dat a bezpečnostně není rozdíl mezi tím, že soukromý klíč je uložen v takovémto hardwarovém klíči či na disketě či magnetickém proužku.
Hardwarové klíče je možné používat pouze v prostředí kontrolovaném samotným uživatelem (např. uživatelův osobní počítač, který se opravdu provozuje jako osobní počítač) nebo v prostředí kontrolovaném správcem aplikace (např. bankomat). Použití hardwarových klíčů v prostředí kontrolovaném třetí stranou se považuje za nebezpečné. Útok v prostředí kontrolovaném třetí stranou je jednoduchý: třetí strana na svém počítači podvrhne software, který se navenek tváří jako aplikace, kterou uživatel běžně používá. Uživatel aplikaci předá data, která si uživatel přeje, aby aplikace podepsala za využití hardwarového klíče vloženého do počítače. Podvržený software, ale hardwarovému klíči nepředá k podpisu původní informace, ale změněné informace ve prospěch útočníka. Hardwarový klíč tyto údaje podepíše jako by je zadal uživatel … .
Čipová karta
Použití čipových karet je omezeno na počítače vybavené příslušnými čtečkami. Přestože digitálně podepsaná data jsou téměř ideálně autorizována, tak využití čipové karty pro tyto účely má svá úskalí. Bez rizika je možné čipové karty použít pro prostředí spravované klientem nebo v prostředí, které klient nemůže konfigurovat. Skutečností ale je, že uživatelé jsou na karty zvyklí a mají již vypěstované návyky pro manipulaci s platebními kartami. Jako ideální kombinace se tak jeví spojení platební karty s autentizační kartou do jedné karty.
Čipové karty mohou používat k autentizaci i jednodušší
algoritmy než je asymetrická kryptografie. Např. algoritmus Challenge – Response. Takové karty se ale
používají zejména jako přístupové karty, tj. nebývají využívány pro internetové
aplikace. Tyto karty mohou pak být i v „bezkontaktním“ provedení, kdy
např. pro autentizaci pro otevření dveří stačí mít takovou kartu pouze v kapse.
Mini klíč
Obdobné technologie jako v případě čipových karet se ukládají do tzv. mini klíčů. Mini klíč se nepřipojuje k PC prostřednictvím čtečky, ale USB portu, který je součástí všech nových typů PC.
Černá skříňka
Soukromé klíče důležitých serverů (např. soukromý klíč samotné certifikační autority) bývají ukládány ve specializovaných boxech („černých skříňkách“), které jsou vybaveny speciální fyzickou bezpečností, která způsobí např. vymazání soukromého klíče v případě mechanické manipulace s boxem (klíč nemusí být smazán, ale může být např. přešifrován symetrickou šifrou). Dokonalejší boxy i mohou v případě mechanického útoku aktivovat výbušninu, která box i se soukromým klíčem zcela zničí.
![]()
8 PKI
PKI je soustavou technických a především organizačních opatření spojených s vydáváním, správou, používáním a odvoláváním platnosti kryptografických klíčů a certifikátů. Jednu z možných norem PKI definuje sada internetových standardů RFC popisujících základní využití asymetrické kryptografie na Internetu. Navazujícími normami popsanými v dalších kapitolách jsou pak normy pro bezpečnou elektronickou poštu (S/MIME) a norma pro bezpečnou komunikaci nejen s webovým servem (TLS).
Historie PKI v Internetu spočívala v tom, že nejprve vzniklo několik norem využívajících kryptografii s veřejnými klíči. Tyto normy na sebe příliš nenavazlovaly a zejména nepokrývaly celou škálu problémů. Jednotliví dodavatelé software tak začali dodávat programy, které mezi sebou vzájemně někdy komunikovly dobře a jindy to bylo se vzájemnou komunikací slabší. V Internetu proto vznikla pracovní skupina, která se pokusila vytvořit soustavu norem překonávajících tyto potíže. Výsledkem je nová generace norem, která není ideální, ale je krokem o dále. V Internetu pod zkratkou PKI rozumíme systém těchto protokolů. Poznáme je podle toho, že většinu v názvu mají slovo „PKI“.
Kromě zmíněných použití asymetrické kryptografie a certifikátů existují na Internetu i jiné aplikace využívající certifikáty. Jedná se např. o systém SET určený pro platby platebními kartami přes Internet, který rovněž používá certifikáty podle X.509, ale pozor!, protokol SET sice používá certifikáty dle X.509, ale nikoliv podle RFC-3280, tj. nikoliv dle PKI. Prostě protokol SET je analogií PKI – obojí vychází z X.509. Avšak protokol SET se výhradně orientuje na platby na Internetu.
Na počátku je třeba zdůraznit, že normy PKI vycházejí z norem ITU-T řady X.500 (např. pro popis certifikátu konkrétně z normy X.509), ale specifikují konkrétní množinu parametrů a praktik určených pro Internet. Tj. např. ne všechna rozšíření certifikátů popsaná v normě ITU-T X.509 jsou normami PKI podporována. Software určený pro Internet pak jiná rozšíření než ta, která jsou uvedena v PKI, nemusí podporovat. Neměli bychom tak v Internetu používat rčení: „certifikát podle X.509 verze 3“, ale „certifikát podle RFC-3280“.
Naopak normy PKI zavádí některá rozšíření, která normy ITU-T neuvádí.
8.1 Certifikát
Certifikát je struktura obsahující identifikační údaje klienta, veřejný klíč klienta, identifikaci vydavatele, číslo certifikátu, platnost certifikátu a další údaje týkající se zejména vymezení způsobu použití certifikátu. Tato struktura je digitálně podepsána certifikační autoritou (vydavatelem certifikátu).
K čemu slouží tato poměrně komplikovaná konstrukce? Na obr.8-1 je znázorněn případ, kdy uživatel A chce uživateli B zaslat zprávu, kterou chce zabezpečit šifrováním asymetrickou šifrou. V takovém případě je nutné, aby příjemce B nejprve vygeneroval dvojici klíčů: veřejný klíč (VK-B) a soukromý klíč (SK-B). Soukromý klíč si uloží jako své tajemství např. na disk či čipovou kartu. Veřejný klíč (VK-B) nějakým kanálem distribuuje uživateli A.
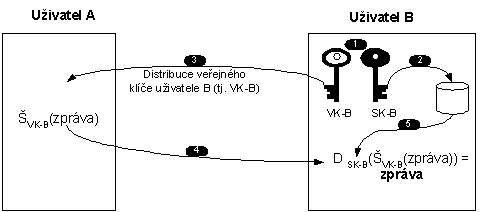
Obr. 8-1 Distribuce veřejného klíče bez certifikátu
Uživatel A pak použije veřejný klíč uživatele B (na obrázku označený VK-B) k zašifrování odesílané zprávy. Uživatel B pak takto šifrovanou zprávu dešifruje svým soukromý klíčem (SK-B) a získá tak původní zprávu.
U asymetrické kryptografie nespočívá nebezpečí ve vyzrazení veřejného klíče. Avšak i u asymetrické kryptografie je nebezpečím podvržení klíče.
Na obr. 8-2 nám vstupuje do hry útočník X, který si vygeneruje svou dvojici klíčů: veřejný klíč (VK-X) a soukromý klíč (SK-X). Útočník svůj veřejný klíč VK-X podvrhne za klíč uživatele B. Tj. uživatel A si myslí, že VK-X je veřejným klíčem uživatele B a provede tímto klíčem šifrování odesílané zprávy. Zprávu odchytne útočník X a dešifruje si ji svým soukromým klíčem SK-X. Útočník tak získá zprávu. Avšak aby uživatel B si neztěžoval, že nedostane zprávu, tak mu ji útočník zašifruje a odešle šifrovanou jeho klíčem (VK-B).
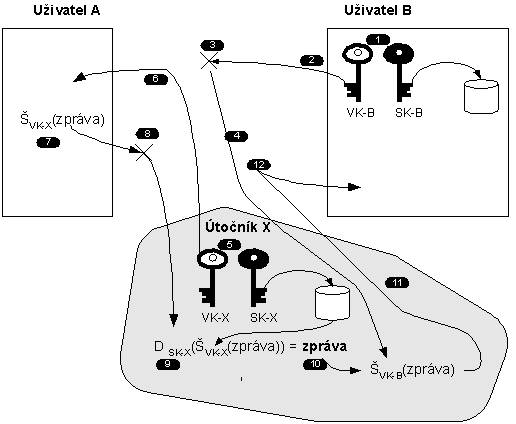
Obr. 8-2 Podvržení veřejného klíče
Proti podvržení veřejného klíče se bráníme certifikací veřejného klíče – tj. pomocí certifikátu (obr. 8-3). Uživatel B vygeneruje dvojici veřejný a soukromý klíč (1), přičemž soukromý klíč si jako tajemství pečlivě uloží. Avšak veřejný klíč neodesílá uživateli B samotný, ale jako součást certifikátu.
Po vygenerování dvojice klíčů uživatel sestaví strukturu „žádost o certifikát“. Tato struktura obsahuje identifikační údaje uživatele, veřejný klíč uživatele a případně další data, která jsou popisována dále. Tuto strukturu digitálně podepíše svým právě vygenerovaným soukromým klíčem a předá certifikační autoritě (2). Certifikační autorita může ověřit totožnost uživatele a v každém případě verifikuje elektronický podpis na žádosti o certifikát. Pokud je žádost certifikační autoritou shledána v pořádku, pak certifikační autorita vystaví certifikát.
Certifikát obsahuje mj.: informace o tom, kdo jej vydal, sériové číslo certifikátu, identifikační údaje uživatele, platnost certifikátu a pochopitelně veřejný klíč uživatele. Certifikát je digitálně podepsán za využití soukromého klíče certifikační autority.
Certifikační autorita má svou dvojici klíčů: veřejný klíč CA (VK-CA) a soukromý klíč (SK-CA). Na bezpečnost uložení soukromého klíče CA jsou kladeny extrémní nároky. Veřejný klíč CA se distribuuje jako součást certifikátu CA. Certifikát CA může být podepsán soukromým klíčem CA samotné nebo i soukromým klíčem jiné CA.
Uživateli je certifikační autoritou vrácen vystavený certifikát (3). S vystaveným certifikátem by měl uživatel obdržet též jeden nebo více certifikátů certifikačních autorit. Pomocí certifikátů certifikačních autorit může být ověřován vystavený certifikát. Dále se dozvíme, že uživatel může od certifikační autority obdržet též seznam zneplatněných certifikátů.
Nyní již může uživatel B svůj certifikát odeslat (4) uživateli A, který jej ověří a v případě, že je vystaven pro uživatele A důvěryhodnou certifikační autoritou a elektronický podpis na certifikátu je v pořádku, pak může z tohoto certifikátu použít veřejný klíč k šifrování zprávy, kterou chce odeslat uživateli B. Šifrovanou zprávu odešle uživateli B (5). Uživatel B pak pomocí svého soukromého klíče dešifruje zprávu (6) a získá tak původní zprávu.
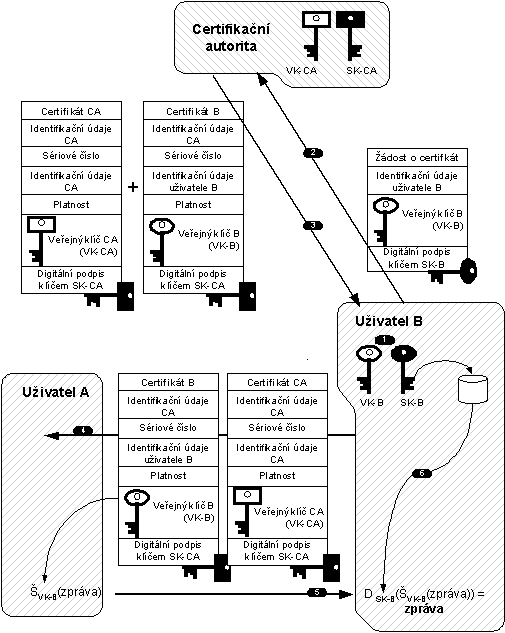
Obr. 8-3 Činnost certifikátu
Pokud namítnete, že ne každý certifikát je určen k elektronickému podpisu, pak i tento případ je dále detailně rozebrán u protokolů CMP a CMC.
Certifikát se často přirovnává k občanskému průkazu. Zatímco občanský průkaz se vydává v tištěné podobě, tak certifikát se popisuje jako struktura v jazyce ASN.1 a mezi počítači se přenáší v kódování DER (podmnožina BER). Certifikát je možné vypsat i v textovém tvaru, ale s tímto případem se setkáváme zřídka - např. certifikát samotné certifikační autority může být vytištěn v textovém tvaru a ověřen (neelektronickým) notářem a podepsán rukou psaným podpisem. Zásadní rozdíl mezi občanským průkazem a certifikátem je, že občanský průkaz neobsahuje šifrovací klíč.
V Internetu je certifikát popsán normou RFC-3280. Tato norma je odvozena od doporučení ITU (dříve CCITT) X.509. Původní verze číslo 1 certifikátu podle normy X.509 z roku 1988 byla postupně rozšířena až do dnes nejběžnější verze 3.
Kromě certifikátů podle RFC-3280 (resp. doporučení X.509) se v praxi můžeme setkat i s certifikáty jiných formátů - např. EDI. Forma takový certifikátu je sice jiná, ale princip zůstává stejný.
Porovnání položek občanského průkazu a položek certifikátu:
|
Položka struktury certifikátu |
Přirovnání k položce občanského průkazu |
|
Verze 0 ... X.509 verze 1 (1988) 1 ... X.509 verze 2 2 ... X.509 verze 3 |
Verze (federální, červený český, karta, ...) |
|
Sériové číslo |
Číslo a série občanského průkazu |
|
Algoritmus použitý pro podpis |
Razítko či samolepka přes fotografii |
|
Vydal (identifikace certifikační autority podle X.500) |
Vydal |
|
Platnost od-do |
Platnost |
|
Jméno a adresa (identifikace vlastníka) |
Jméno a adresa |
|
Veřejný klíč |
- |
|
Rozšíření certifikátu |
Další údaje |
|
Elektronický podpis certifikátu |
Vlastní razítko či samolepka přes fotografii |
8.1.1 Jedinečná jména
Jedinečná jména se používají pro popis vystavitele certifikátu i pro popis předmětu certifikátu. Jedinečné jméno (Distinguished name) je typu Name zavedeného normou X.501.
Cílem norem řady X.500 je vytvořit celosvětovou adresářovou strukturou. Adresářem se přitom nerozumí adresář souborů, ale adresář jako seznam adres. Cílem je vytvořit obdobu celosvětových bílých stránek telefonních seznamů. Jeden záznam v takovém seznamu odpovídá pak jedinečnému jménu. Záznam v takové bílé knize by pak byl hypoteticky tvořen informacemi o státu, telefonní společnosti, telefonním obvodě, jméně, adrese, telefonním čísle.
Obdobně i jedinečné jméno bude tvořeno relativními jedinečnými jmény. Jednotlivá relativní jedinečná jména budou popisovat např.: stát, kraj, organizaci, jméno, adresu elektronické pošty atd.
Jedinečné jméno (někdy též absolutní jedinečné jméno či RDNSequence) je vždy posloupností relativních jedinečných jmen (Relative Distinguished Name). Přitom v jedinečném jméně se mohou i relativní jedinečná jména opakovat.
Relativní jedinečné jméno je množina dvojic tvořených identifikátorem objektu (např. Country, Organization, CommonName apod.) a řetězcem (např. CZ). Textově pak často relativní jedinečné jméno zapisujeme např.
Country=CZ
Jedinečné jméno popisující jedince je pak sekvencí relativních jedinečných jmen. Např.:
Country=CZ, Organization=PVT, CommonName=Libor Dostalek
Tento zápis se často zkracuje pomocí zkratek pro identifikátory objektů relativních jedinečných jmen:
C=CZ, O=PVT, CN=Libor Dostalek
I když relativní jedinečné jméno je množinou dvojic identifikátor objektu + hodnota, tak v praxi bývá tato množina jednoprvková, tj. obsahuje dvojici jen jednu. Jedinečná jména jsou tvořena vždy větví ve stromu relativních jedinečných jmen (obr. 8-4).
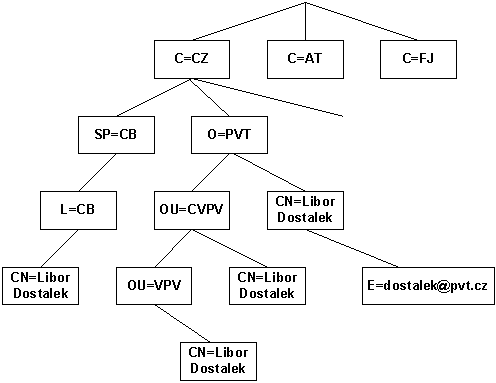
Obr. 8-4 Hierarchická struktura relativních jedinečných jmen
Zajímavé je, že Libor Dostalek může být ve struktuře uveden mnoha způsoby. Např.
- Jako
obyvatel Česka, konkrétně Českobudějovického kraje, konkrétně Českých
Budějovic:
C=CZ, SP=CB, L=CB, CN=Libor Dostalek - Jako zaměstnanec firmy PVT
s adresou elektronické pošty
C=CZ, O=PVT, CN=Libor Dostalek,
- Jako
zaměstnance oddělení CVPV firmy PVT:
C=CZ, P=PVT, OU=CVPV, CN=Libor Dostalek atd.
Použil jsem jméno Dostalek, tj. bez české diakritiky, ale nic nebrání používat diakritiku, protože PKI ve všech řetězcích, u kterých přichází v úvahu použití diakritiky, připouští kódování UTF-8.
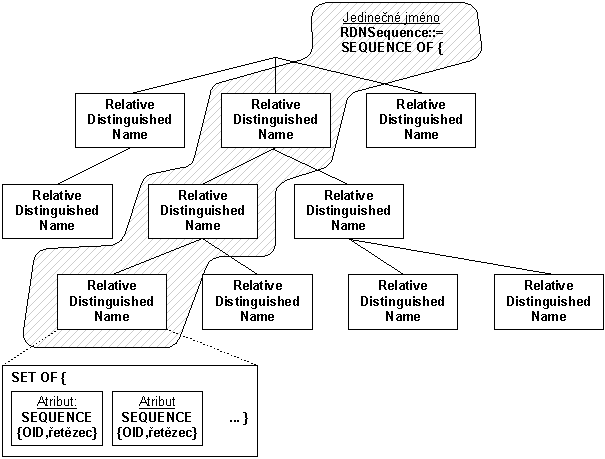
Obr. 8-5 Jedinečné jméno (RDNSequence) je posloupností relativních jedinečných jmen
Přehled atributů relativních jedinečných jmen používaných PKI:
|
Identifikátor / zkratka |
Atribut |
Význam |
|
Common Name CN |
commonName |
Název objektu, pod kterým je místně znám. Např. u osob to může být jméno a příjmení. U serverů pak jejich DNS-jméno. |
|
Surname |
surname |
Příjmení |
|
Serial Number |
serialNumber |
Slouží k rozlišení různých certifikovaných objektů,
kterým by jinak vyšlo stejné jedinečné jméno. Je doporučen používat u
kvalifikovaných certifikátů. |
|
Country C |
countryName |
Stát podle ISO 3166, tj. podle stejné normy, jaká se používá pro top level domény DNS (CZ=Česká republika, SK=Slovensko, FJ=Fidži...) |
|
Locality L |
localityName |
Místo (např. město) |
|
State or Province SP |
stateOrProvinceName |
Nižší organizační jednotka státu. Např. spolková země. |
|
Organization O |
organizationName |
Název firmy |
|
Organization Unit OU |
organizationUnitName |
Název části firmy |
|
Title |
title |
Titul |
|
Postal Adress |
postalAdress |
Poštovní adresa |
|
Name |
name |
Jméno |
|
Given Name |
givenName |
Rodné jméno |
|
Initilas |
initials |
Iniciály |
|
Generation Qualifier |
generationQualifier |
Např. „Jr.“ či „IV“ pro Karel IV |
|
DNQualifier |
dnQualifier |
Slouží k rozlišení různých certifikovaných objektů, kterým by jinak vycházel stejný předmět. |
|
E-mail Address E |
emailAddress či pkcs9mail |
Adresa elektronické pošty (dle RFC-822). |
|
Domain Component DC |
domainComponent |
Jednotlivé řetězce z DNS jména. Např. info.pvt.net je DC=info, DC=pvt, DC=net |
8.1.2 Identifikační údaje CA (vystavitel certifikátu) - Issuer
Položka issuer, česky vystavitel či vydavatel certifikátu, obsahuje jedinečné jméno certifikační autority, které je jako celek též identifikací certifikační autority jako takové. Je třeba, aby certifikační autorita měla jednoznačnou identifikaci (jedinečné jméno) v rámci všech certifikačních autorit
Položka issuer – jedinečné jméno certifikační autority – je tvořena kombinací atributů relativních jedinečných jmen. Musí být podporovány následující atributy: country, organization, organizationUnit, dnQualifier, stateOrProvinceName, commonName a podpora domainComponent. Programy by měly být dále podporovány atributy: locality, title, surname, givenName, initials, a generationQualifier.
8.1.3 Identifikační údaje uživatele (předmět certifikátu) - subject
Položka subject certifikátu se do češtiny překládá jako předmět certifikátu. Tato položka obsahuje jedinečné jméno objektu, kterému je certifikát vydán.
Předmět certifikátu musí být jedinečný v rámci všech objektů certifikovaných danou certifikační autoritou. V případě, že pro dva různé objekty by vycházel stejný předmět, pak se pro rozlišení objektů použije atribut DNQualifier (v případě kvalifikovaných certifikátů použijeme atribut serialNumber).
Důležité je, že pro stejný objekt může tatáž certifikační autorita vydat i několik různých certifikátů, které mají stejný předmět (stejné jedinečné jméno). Tj. Václav Vopička může mít více různých certifikátů se stejným předmětem, protože se jedná o stejného Václava Vopičku. Ale jeho jmenovec, který se jen shodou okolností také jmenuje Václav Vopička, musí mít jiný předmět. Může mít např. jinou lokalitu (město), ale kdyby i všechny ostatní údaje byly stejné, pak CA použije k rozlišení jedinečné jméno dnQualifier či jedinečné jméno serialNumber u kvalifikovaných certifikátů (nezaměňovat s číslem certifikátu – to musí být v každém případě různé).
V předmětu certifikátu zpravidla využíváme širší paletu atributů jedinečných jmen než u jedinečného jména vystavitele, kde bychom měli být střídmí, i když software má podporovat nejrůznější atributy.
U certifikátů kořenových certifikačních autorit obsahuje předmět i vystavitel stejné údaje. Kořenová certifikační autorita si podepisuje certifikáty sama sobě – vydává tzv. „self-signed“ certifikáty.
Mnohé údaje, které se „nevejdou“ do předmětu certifikátu, je možné uložit do rozšíření certifikátu.
8.1.4 Rozšíření certifikátu
To, co
se nevešlo do předchozích položek certifikátu, se snažíme uložit do některého
z rozšíření
I když rozšíření je definováno zcela obecně, tak je i u rozšíření potíž podobně jako u atributů předmětu certifikátu spočívající v tom, že aplikace s některým rozšířením nebude počítat – nebude znát, k čemu nějaké konkrétní rozšíření slouží. Tento problém řeší položka závažnost rozšíření (critical). Tato položka sděluje, jestli je rozšíření kritické či nikoliv. V případě, že je tato položka nastavena na TRUE, pak je rozšíření označeno jako kritické.
Nejčastěji používaná rozšíření:
|
Rozšíření |
Označení |
|
Identifikátor klíče certifikační autority |
id-ce-AuthorityKeyIdentifier |
|
Identifikátor klíče předmětu |
id-ce-SubjectKeyIdentifier |
|
Doba platnosti soukromého klíče |
id-ce-PrivateKeyUsagePeriod |
|
Použití klíče |
id-ce-keyUsage |
|
Rozšířené použití klíče |
id-ce-extKeyUsage |
|
Alternativní jméno předmětu |
id-ce-subjectAltName |
|
Alternativní jméno vydavatele |
id-ce-issuerAltName
|
|
Certifikační politiky |
id-ce-certificatePolicies |
|
|
id-ce-policyMappings |
|
|
id-ce-policyConstraints
|
|
Základní omezení |
id-ce-basicConstraints
|
|
Omezení jména |
id-ce-nameConstraints |
|
Distribuční místa odvolaných certifikátů |
id-ce-cRLDistributionPoints
|
|
|
id-ce-subjectDirectoryAttributes |
Identifikátor
klíče certifikační autority – Authority Key Identifier

Obr. 8-6 Otazníkem je vyznačená doba, po kterou platí dva certifikáty CA. Pro ověření 2. certifikátu uživatele je nutný veřejný klíč ze starého certifikátu CA a pro ověření 3. certifikátu uživatele je třeba veřejný klíč z nového certifikátu CA. Jelikož položka issuer ve všech certifikátech uživatele může být stejná, tak právě identifikátor klíče certifikační autority určuje, který z certifikátů CA je nutný pro ověření certifikátu uživatele.
CA tak poměrně dlouhou dobu má dva certifikáty, které se překrývají. Někteří uživatelé mají svůj certifikát podepsán „starým“ certifikátem CA a jiní „novým“ certifikátem CA. Oba certifikáty CA budou mít stejný předmět. Budou se lišit sériovým číslem a veřejným klíčem. V certifikátu uživatele je však v položce vydavatel (issuer) uveden pouze předmět z certifikátu CA, kterým je certifikát uživatele podepsán. Jenže jak sestavit řetězec certifikátu, když máme dva certifikáty certifikační autority se stejným polem předmět? Pro identifikaci je možné použít sériové číslo či samotný veřejný klíč z certifikátu, ale použití rozšíření „Identifikátor rozšíření veřejného klíče CA“ je podstatně jednodušší.
Příkladem je situace na obr. 8-6. Certifikační autorita vystavuje svým uživatelům certifikáty platné nejvýše 1,5 roku. Sama CA si vydává certifikáty CA platné 4 roky. Proto 1,5 roku před vypršením svého certifikátu si musí vydat nový certifikát. Pokud by např. 1 rok před vypršením certifikátu CA vydala uživateli certifikát podepsaný soukromým klíčem příslušejícím ke starému certifikátu, pak by v posledním 0,5 roce platnosti takto vydaného uživatelského certifikátu byla potíž s ověřováním certifikátu: certifikát uživatele by byl platný, ale při ověřování tohoto certifikátu by se narazilo na to, že již není platný příslušný certifikát CA.
V době označené na obr. 8-6 otazníkem jsou platné dva certifikáty CA. 2. uživatelův certifikát je podepsán starým certifikátem CA a 3. uživatelův certifikát novým certifikátem CA. Přitom ve 2. i 3. certifikátu je uvedena stejná CA. Jak má tedy software poznat, kterým certifikátem CA má ověřovat 2. a kterým 3. uživatelův certifikát?
Tj. pro ověření certifikátu je třeba vytvořit řetězec certifikátů až ke kořenovému certifikátu. Pro usnadnění tvorby tohoto řetězce certifikátů slouží rozšíření identifikátor klíče certifikační autority.
Identifikátor klíče certifikační autority, která certifikát vydala, je ve své podstatě rozšířením pole vystavitel certifikátu (issuer) o identifikaci klíče. Zatímco v poli vystavitel certifikátu je pouze předmět certifikátu, jehož příslušným soukromým klíčem byl certifikát vydán, tak v rozšíření „identifikátor klíče CA“ může být navíc i sériové číslo certifikátu, jehož příslušným soukromým klíčem byl certifikát podepsán. Tj. snadno lze pak vytvářet řetězce certifikátů pro ověření cerifikátu.
Použití
klíče – Key
Usage
Pomocí tohoto rozšíření lze omezit způsob použití veřejného klíče obsaženého v certifikátu (resp. jemu příslušejícího soukromého klíče). Toto rozšíření obsahuje bitový řetězec. Každý bit z řetězce pak odpovídá konkrétnímu způsobu použití certifikátu. Je-li příslušný bit nastaven na jedničku, pak je certifikát k danému použití možné používat. Rozšíření se označí jako kritické, čímž se zamezí použití certifikátu k jiným účelům než k účelům vyznačeným v certifikátu.
Význam jednotlivých bitů:
- digitalSignature – certifikát je určen k elektronickému podpisu dat. Nastavení tohoto bitu neopravňuje k:
- Ověřování pravosti (k té je nutné nastavení bitu číslo 1). To vás asi překvapilo. Asi si říkáte, k čemu teda může takový certifikát sloužit. Může sloužit k autentizaci uživatelů nebo k ověřování integrity dat.
- Podepisování certifikátů (k tomu je třeba nastavení bitu číslo 5)
- Podepisování CRL (k tomu je třeba nastavení bitu číslo 6)
- nonRepudation – certifikát je určen pro ověřování pravosti dat (ověřování elektronického podpisu).
- keyEncipherment – certifikát je určen k šifrování klíčů. Klasickým případem je elektronická obálka, kdy data jsou šifrována náhodným symetrickým šifrovacím klíčem, který je ke zprávě přibalen a zašifrován právě veřejným klíčem z takto označeného certifikátu.
- dataEncipherment – veřejný klíč z takto označeného certifikátu je určen pro šifrování dat (jiných než šifrovacích klíčů).
- keyAgreement – certifikát je určen pro výměnu klíčů (např. DH metoda výměny klíčů).
- keyCertSign – veřejný klíč uvedený v tomto certifikátu je určen pro verifikaci certifikátů. Tj. soukromý klíč příslušející k tomuto veřejnému klíči je možné použít pro podepisování certifikátů.
- cRLSign – veřejný klíč uvedený v tomto certifikátu je možné použít k verifikaci CRL.
Pokud bychom chtěli vydat certifikát se všemi nastavenými bity, pak jej vydáme bez tohoto rozšíření.
Rozšířené
použití klíče
Je obecnějším řešením pro
určení účelů, k jakým je certifikát určen.
- Objekt id-kp-serverAuth určuje, že certifikát je určen pro
autorizaci webového serveru. Tento objekt je konzistentní
s následujícími nastavenými bity rozšíření „Použití klíče“: buď
digitalSignature a keyEncipherment nebo keyAgreement.
- Objekt id-kp-clientAuth určuje, že certifikát je určen pro
autorizaci webového klienta. Tento objekt je konzistentní
s následujícími nastavenými bity rozšíření „Použití klíče“:
digitalSignature nebo keyAgreement.
- Objekt id-kp-codeSigning určuje, že certifikát je určen pro
podepisování stahovaného software (např. digitálně podepsaných ActiveX
komponent nebo digitálně podepsaných Java appletů). Tento objekt je
konzistentní s nastaveným bitem digitalSignature rozšíření „Použití klíče“
digitalSignature.
- Objekt id-kp-timeStamping určuje, že certifikát je určen pro
vydávání časových razítek. Tento objekt je konzistentní
s následujícími nastavenými bity rozšíření „Použití klíče“:
digitalSignature a nonRepudiation.
- Objekt id-kp-emailProtection určuje, že certifikát je určen pro
bezpečný mail. Tento objekt je konzistentní s následujícími
nastavenými bity rozšíření „Použití klíče“: buď digitalSignature a
nonRepudiation nebo
keyEncipherment a keyAgreement.
- Objekt id-kp-OCSPString je určen pro protokol OCSP. Toto rozšíření
je určeno pro certifikát OCSP serveru.
Při vydávání certifikátů je třeba zajistit, aby údaje
v rozšířeních „Použití klíče“ a „Rozšířené použití klíče“ byly vzájemně
konzistentní.
Alternativní jméno předmětu - Subject Alternative
Name
Toto rozšíření umožňuje vložit do certifikátu další identifikační
údaje, které se nevešly do předmětu. Při vydávání certifikátu nesmí být
opomenuta kontrola i údajů uvedených v tomto rozšíření.
Uvedeno zde mj. může být:
- rfc822Name - adresa
elektronické pošty dle RFC-822 (např. dostalek@pvt.cz,
- dNSName - DNS jméno (např.
jméno serveru www.firma.cz),
- x400Address - adresa
elektronické pošty podle norem řady X.400,
- directoryName - adresářové
jméno podle norem řady X.500,
- ediPartyName - jméno
podle norem EDI,
- uniformResourceIdentifier
- URI (např. http://www.firma.cz),
- iPAddress - IP adresa,
- registeredID -
identifikátor objektu.
konvertor nepozná o jaký typ se jedná).
Certifikační politiky - Certificate Policies
Certifikační politika je skupina dokumentů vydaných certifikační
autoritou. V těchto dokumentech jsou popsány postupy, praktiky a cíle CA.
Tj. pravidla, za kterých CA vydává certifikáty, a zejména jak za vydané
certifikáty ručí. Na rozdíl o některých
jiných dokumentů CA je certifikační
politika veřejným dokumentem.
MS Explorer používá místo „Certifikační politika“ název „Certifikační
zásady“.
Provozovatel CA si zpravidla zaregistruje identifikátor objektu pro své
dokumenty. Identifikátory objektu certifikační politiky se pak uvádí
v rozšíření certifikátu nazývaném „Certifikační politika“. Jestliže je toto rozšíření označeno jako
kritické, pak software ověřující certifikát může certifikát akceptovat jedině
v případě, že je schopen interpretovat toto rozšíření včetně jeho
parametrů. Jinými slovy: musí pro něj být akceptovatelná uvedená certifikační
politika.
Základní omezení - Basic
Constraints
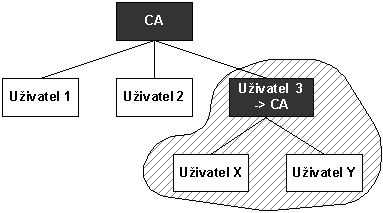
Obr. 8-7 Uživatel 3 se prohlásil za certifikační autoritu
Jádrem činnosti CA je to, že svým podpisem ručí za údaje uvedené ve vydaných certifikátech. Na obr. 8-7 je znázorněno nebezpečí pro CA spočívající v tom, že CA vydává certifikáty svým uživatelům a najednou uživatel 3 se svévolně prohlásí za CA a vydá certifikáty uživatelům X a Y. Problém je v tom, že CA ručí za takto vydané certifikáty uživatelů X a Y díky tomu, že např. uživatel X dostane řetězec certifikátů obsahující: certifikát uživatele X, certifikát uživatele 3 a certifikát CA. Čili není problém ověřit platnost takového certifikátu (tj. zodpovědnost CA za takto vydaný certifikát).
Jeden mechanismus, jak takovémuto počínání uživatele zamezit, jsme již popsali – pomocí rozšíření „Použití klíče“, kterým v certifikátech vydávaných uživatelům jejich klíč neoznačíme, že je jej možné používat k verifikaci certifikátů.
Rozšíření „Základní omezení“ umožňuje označit certifikát, aby bylo zřejmé, zdali se jedná o certifikát CA nebo koncového uživatele, nastavením položky cA (je-li nastavena na TRUE, pak se jedná o certifikát CA). Pomocí položky pathLenConstraint pak sdělíme, kolik může v certifikační cestě následovat certifikátů certifikačních autorit pod tímto certifikátem. Např. je-li tato položka nastavena na nulu, pak se pod tímto certifikátem certifikační autority může v certifikační cestě vyskytovat pouze certifikát koncového uživatele (nikoliv certifikát CA).
Distribuční
místa odvolaných certifikátů – CRL Distribution points
- Toto rozšíření obsahuje sekvenci URI, na kterých je vystaven seznam odvolaných certifikátů (CRL).
8.2 Kvalifikované certifikáty
Kvalifikovaný certifikát je zvláštní typ certifikátu, které používá Evropská unie ve své legislativě. Zvláštní není ani svou syntaxí (ta je ve své podstatě podmnožinou certifikátu popsaného v předchozí kapitole, tj. certifikátu dle RFC-3280). Zvláštnost je v právní oblasti. Cílem kvalifikovaného certifikátu je i po právní stránce nahradit rukou psaný podpis elektronickým podpisem. Jádro myšlenek ohledně kvalifikovaných certifikátů je uvedeno v RFC-3039. Je to snad jediné RFC, které vychází z Evropských zkušeností a pokouší se je celosvětově zobecnit. V Česku je použití kvalifikovaných certifikátů vymezeno zákonem o elektronickém podpisu.
Kvalifikovaný certifikát se vydává konkrétnímu člověku (nikoliv např. serveru). Kvalifikovaný certifikát obsahuje identifikaci držitele certifikátu založenou na oficiální identifikaci člověka nebo na jeho pseudonymu. Certifikační autorita vždy zná konkrétní osobu, které certifikát vydala.
Předmět certifikátu musí být jednoznačný pro konkrétní osobu, tj. dvě různé osoby nemohou mít vydán certifikát se shodným předmětem. Tato podmínka musí být splněna po celou dobu existence konkrétní CA. Pro docílení této podmínky je možné použít atribut serialNumer (nezaměňovat s položkou sériové číslo certifikátu). Kdyby dvě osoby mely mít stejné předměty, pak se odliší hodnotou v položce serialNumer.
U kvalifikovaných certifikátů nestačí, aby byl pouze předmět jednoznačný pro konkrétní osobu, ale certifikační autorita nesmí vydat dvěma různým osobám certifikát, který by měl stejný veřejný klíč. Tj. certifikační autorita musí po dobu své existence archivovat i veřejné klíče, které uživatelům podepsala. U veřejných klíčů musí mít i informaci pro jaké algoritmy se budou používat, aby mohla porovnávat klíče, zdali již nejsou použité. Otázkou je, co udělat, když CA obdrží žádost o certifikát s veřejným klíčem tč. platného certifikátu. Asi by měl být platný certifikát odvolán z iniciativy CA a žádost zamítnuta.
Podle zákona o elektronickém podpisu je nutné, aby byly kvalifikované certifikáty používané pro styk se státní správou vydávány státem akreditovaným certifikačními autoritami.
RFC-3039 určujeatributy položek vydavatele certifikátu, předmět certifikátu a jaká rozšíření mohou být použita v kvalifikovaném certifikátu.
8.3 Žádost o odvolání certifikátu
Představte si situaci, kdy přijdete o soukromý klíč nebo se vám podaří soukromý klíč vyzradit. Pak je třeba příslušný certifikát odvolat.
Při odvolávání certifikátu nejde o to, postupovat podle nějakých norem, ale jde především o rychlost. Pokud soukromý klíč máte, pak pošlete žádost o odvolání certifikátu na CA např. elektronickou poštou. Zprávu elektronické pošty podepíšete soukromým klíčem příslušejícím odvolávanému certifikátu. Jenže to stejně nejde, pokud není certifikát k takovémuto podpisu určen.
Pokud o soukromý klíč přijdete nebo certifikát není určen pro ověřování elektronického podpisu, pak elektronické cesty selhávají.
Některé CA při vydání certifikátu pro takové případy vystaví jednorázové heslo pro odvolání certifikátu. Pokud toto heslo znáte, pak lze odvolat certifikát telefonicky, faxem nebo nepodepsanou elektronickou poštou s uvedením zmíněného jednorázového hesla.
Pokud neznáte ani jednorázové heslo, pak nezbývá, než se s doklady totožnosti a smlouvou o vydání certifikátu vydat na registrační autoritu. Pokud přijdete úplně o vše, pak máte problém. V takovém případě to ale asi není ten největší problém který máte.
8.4 Seznam odvolaných certifikátů - CRL
Certifikát může ztratit svou platnost tak, že vyprší, tj. uplyne čas notAfter uvedený v certifikátu. Druhou možností, jak může pozbýt certifikát své platnosti, je na základě žádosti držitele certifikátu či jeho zaměstnavatele (např. při rozvázání pracovního poměru) o odvolání certifikátu podané na certifikační autoritu. Třetí možností je odvolání certifikátu z iniciativy samotné CA (např. dorazí-li na CA žádost o certifikát se stejným veřejným klíčem jako má existující vydaný certifikát).
CA odvolaný certifikát zveřejní na seznamu odvolaných certifikátů (Certificate Revocation List - neboli CRL).
Mechanizmus žádosti o odvolání certifikátu zveřejňuje CA v dokumentu „Certifikační politika CA“. Žádost o odvolání certifikátu nemusí být prováděna ani elektronickou formou, ale CA může vyžadovat např. osobní účast uživatele. Pokud se provádí elektronickou cestou, pak žádost musí být elektronicky podepsána soukromým klíčem odvolávaného certifikátu (v případě, že by takou žádost provedl hacker neoprávněně, tj. uměl ji elektronicky podepsat, tj. znal soukromý klíč, pak je pro uživatele jen dobře, že ji podal). Nebo může být použito jednorázové heslo pro odvolání certifikátu.
CRL obsahuje sériová čísla odvolaných certifikátů (CRL může být i prázný). Odvolané certifikáty se zveřejňují v CRL až do vypršení jejich původní doby platnosti (notAfter).
Způsob zveřejňování CRL je opět uveden v dokumentu „Certifikační politika CA“. Může jej např. vystavovat na webovém serveru atp. V rozšíření certifikátu „Distribuční místa odvolaných certifikátů“ jsou uvedená URI, na kterých CA dává k dispozici CRL.
Mechanismus CRL spočívá v tom, že CA vydává CRL zpravidla v pravidelných intervalech. V intervalu mezi vydáváním CRL schraňuje jednotlivé žádosti o odvolání certifikátu, které pak shrne do následujícího CRL. Tj. účinnost odvolání CRL není okamžitá, ale až s vydáním následujícího CRL.
Tvar CRL specifikovala norma X.509. Avšak v Internetu používáme CRL, které sice vycházejí ze specifikace CRL podle normy X.509 verze 2, ale opět je tato struktura pro Internet popsána v RFC-3280. Podle RFC-3280 musí CRL obsahovat: pravděpodobné datum a čas vydání následujícího CRL, číslo CRL uvedené v příslušném rozšíření CRL a rozšíření „Identifikátor klíče certifikační autority“.
8.5 On Line zjišťování platnosti certifikátu - OCSP
V případě, že držitel certifikátu zjistí, že jeho soukromý klíč byl ztracen nebo odcizen, pak mechanismus CRL mu nebude příliš vyhovovat, protože do vydání dalšího CRL může být jeho soukromý klíč zneužit.
Pokud uživatel používá certifikát primárně pouze v jedné aplikaci (např. při styku s bankou), pak nejspíše okamžitě kontaktuje provozovatele této aplikace a certifikát si nechá zablokovat v této aplikaci. V tomto případě snad ani CRL nepotřebuje.
Jenže pokud uživatel používá certifikát k více účelům, pak takovou službu vyžaduje od CA. Tuto problematiku řeší protokol OCSP (Online Certificate Status Protocol).
Protokol OCSP je protokol typu klient/server. Klient pošle na OCSP server dotaz obsahující identifikaci certifikátu a OCSP server vrátí informaci o tom, zda-li je certifikát odvolán či nikoliv, nebo vrátí odpověď, že mu tato informace není známa či nějakou chybovou hlášku. V případě, že byl odvolán certifikát CA, pak OCSP server odpovídá na všechny dotazy na platnost certifikátů touto CA vydaných informací, že jsou neplatné.
Ve své podstatě protokol OCSP může být užitečný i v případě, že CRL obsahují příliš velké množství odvolaných certifikátů. Pak při každé manipulaci s certifikátem by procházení tak rozsáhlého CRL zabralo příliš mnoho času – kdežto protokol OCSP na jednoduchý dotaz vrátí jednoduchý výsledek. Problém vyhledání certifikátu v CRL se tak přesouvá na server, který ho může umět řešit mnohem efektivněji.
OCSP
server může provozovat samotná CA, pak odpovědi OCSP serveru jsou podepsány
klíčem samotné CA. CA však může delegovat svou pravomoc na jiný server. Pak
vydá tomuto serveru certifikát s rozšířením „Rozšířené použití klíče“
obsahující objekt id-kp-OCSPSigning.
Poslední možností je, že certifikát OCSP
serveru není ani certifikát CA, jež dotazovaný certifikát vydala, ani
neobsahuje zmíněné rozšíření, pak v lokální konfiguraci OCSP klienta musí
být tento certifikát explicitně uveden. Tuto možnost lze použít i
v intranetu, odkud není přímé spojení na oficiální OCSP servery.
Naopak uživatelský certifikát může obsahovat privátní rozšíření „Přístupové informace CA“ s objektem id-ad-ocsp specifikující např. URI, na kterém běží OCSP server.
8.6 Žádost o certifikát tvaru CRMF
Žádost o certifikát tvaru CRMF (Certificate Request Message Format) je podstatně bohatší než žádost PKCS#10. Řeší totiž některé problémy, se kterými žádost PKCS#10 nedokáže vyrovnat. Žádost PKCS#10 je digitálně podepsána soukromým klíčem příslušejícím veřejnému klíči v žádosti. Jenže co si počít v případě, že certifikát nemá být používán pro elektronický podpis? V takovém případě je nekorektní použít elektronický podpis, byť jen v žádosti o certifikát.
8.7 PKCS#7 a CMS
Už jsme si ukázali, jak se certifikát vydá, jak se odvolá atd. Nyní přistoupíme k tomu nejdůležitějšímu, a to jak certifikát použít. V Internetu se nejspíše setkáme se čtyřmi způsoby:
- Použití certifikátu pro elektronické podepisování a šifrování zpráv (PKCS#7 a CMS).
- Použití certifikátu pro přístup na bezpečný webový server (SSL či TLS).
- Použití certifikátu pro vytváření virtuálních privátních sítí (IPsec).
- Použití certifikátu pro elektronické podepisování kódu (Java aplety, ActiveX komponenty, drivery pro Windows 2000)
Jelikož tato kapitola pojednává o PKI, tak se budeme věnovat PKCS#7 a CMS. Protokolům SSL a TLS je věnována samostatná kapitola; rovněž problematice IPsec je také věnována samostatná kapitola.
Takže nyní k zabezpečeným zprávám PKCS#7 a CMS. Pojmem je protokol PKCS#7, který zavedla firma RSA. Je to podobný pojem jako Lux pro vysavače či IBM PC pro osobní počítače.
Protokol PKCS#7 byl přejat jako RFC pod označením RFC-2315. Avšak postupně i v této oblasti došlo k některým úpravám, a tak vyšla norma RFC-2630: Cryptographic Message Standard – CMS. Takže postupně přecházíme na protokol CMS, ale stále často mluvíme o PKCS#7, a přitom bychom měli mluvit o CMS.
Protokol CMS se snaží být maximálně zpětně kompatibilní s protokolem PKCS#7.
Obr. 8-15 PKCS#7 může data zpracovávat cyklem – např. je nejprve elektronicky podepsat a výsledek pak šifrovat
Protokoly PKCS#7 a CMS jsou určeny k zabezpečení dat. Jenže pod slovem zabezpečení rozumíme jak elektronický podpis, tak elektronickou obálku či autentizaci dat.
Zpracovávaná i zabezpečená (výsledná) data jsou vždy určena dvojicí: identifikátor objektu typu dat a vlastní data. Jak je znázorněno na obr. 8-15, tak do zpracování PKCS#7 (resp. CMS) vstupuje jedna dvojice (např. identifikátor nezabezpečených dat, tj. „data“ + nezabezpečená data). PKCS#7 (resp. CMS) provede elektronický podpis, tj. výsledkem je dvojice identifikátor objektu pro podepsaná data + podepsaná data. Tato dvojice opět vstoupí do procesu PKCS#7 (resp. CMS) a výsledkem je dvojice identifikátor objektu pro data v elektronické obálce + elektronicky zaobálkovaná data (uvnitř elektronické obálky jsou podepsaná data).

Obr. 8-16 Formát zprávy PKCS#7 (resp. CMS)
Jak je znázorněno na obr. 8-16, zpráva PKCS#7 (resp. CMS) se skládá z identifikátoru objektu typu dat (contentType) a vlastních přenášených dat (content). Vlastní data jsou nepovinná. Nepovinných dat se používá zejména u elektronicky podepisovaných zpráv, a to jednak pro tzv. externí elektronický podpis a jednak pro distribuci certifikátů samotných.
8.7.1 Typy dat
PKCS#7 specifikujíce následující typy obsahu zpráv:
- „Data“ - obecná data s identifikátorem objektu id-data.
- „Signed Data" - elektronicky podepsaná data s identifikátorem objektu id-signedData.
- „Eenveloped Data“ – data v elektronické obálce (šifrovaná data) s identifikátorem objektu id-envelopedData.
- „Signed And Enveloped Data“ - elektronicky podepsaná a zároveň šifrovaná data s identifikátorem objektu signedAndEnvelopedData.
- „Digested Data“ - data s kontrolním součtem s identifikátorem objektu id-digestedData.
- „Encrypted Data“ – šifrovaná data jiným způsobem s identifikátorem objektu id-encryptedData.
CMS přináší následující úpravy:
- Nepodporuje typ „Signed And Enveloped Data“. To považuji za vítězství rozumu, protože je rozumné oddělit šifrování dat od elektronického podepisování. Šifrováním zabezpečujeme data na jejich přenos Internetem a pak už elektronická obálka ztrácí smysl . Kdežto elektronický podpis mnohdy chceme i archivovat. Pokud se podepisování spojí se šifrováním, tak je nutné archivovat i soukromé šifrovací klíče uživatelů, což je dlouhodobě prakticky možné snad jen opravdu jako služba CA. Nedovedu si představit, že běžný občan si sám zajistí archivaci soukromého klíče třeba po dobu dvaceti let. Pokud namítnete, že přece v archivu archivujete šifrované zprávy, pak je ale nejspíše archivujete šifrovány šifrovacím klíčem archivu. Pokud opravdu archivujete zprávy šifrované klíčem příjemce, pak si tréninkově zkuste se podívat např. na pět let starou zprávu (jestli k ní uživatel najde svůj starý soukromý klíč).
- Zavádí typ: „Authenticated Data“ – autorizovaná dat s identifikátorem objektu id-ct-authData.
8.7.2 Typ zprávy „Signed Data“
Tento typ se používá u elektronicky podepsané zprávy. Jedna zpráva může obsahovat i více elektronických podpisů. Zajímavostí je, že tento typ zprávy může být i degenerován na případ, kdy zpráva neobsahuje žádný elektronický podpis. Tento degenerovaný případ se používá pro distribuci certifikátů a CRL, kdy nezáleží na obsahu zprávy.
Uvnitř podepsané zprávy je vnořena zpráva, která se podepisuje (vstupní data). Vstupní data se opět skládají z identifikátoru typu dat a vlastních dat. Další zajímavostí je, že položka vstupních dat může být prázdná. To může mít dva důvody:
1. Může se jednat o již uvedenou degenerovanou zprávu sloužící pro distribuci certifikátů.
2. Může se jednat o tzv. externí elektronický podpis, kdy podepisovaná data jsou přepravována mimo vlastní strukturu pro elektronický podpis. To je časté např. u elektronické pošty. U elektronické pošty pak zprávu rozdělíme na data a elektronický podpis. Příjemce, který nemá software pro zpracování elektronického podpisu, pak může alespoň první část zprávy přečíst, což je mnohdy velice praktické.
Obr. 8-17 Struktura elektronicky podepsané zprávy (Signed Data)
Formát elektronický podepsané zprávy je znázorněn na obr. 8-17. Význam jednotlivých položek je následující:
· Položka version obsahuje verzi struktury elektronicky podepsané zprávy. PKCS#7 používá verzi 1, CMS doporučuje používat verzi 3 a jen v případech, kdy jsou zásadně používány certifikáty nemající žádné rozšíření a kdy podepisovaná zpráva je pouze typu id-data, tak použít verzi 1.
· Položka digestAlgorithmus obsahuje množinu identifikátorů algoritmů použitých pro výpočet kontrolního součtu.
· Položka encapContentInfo může obsahovat podepisovaná data. Jedná se opět o dvojici identifikátor objektu (tj. co je to za typ dat, které podepisuji) a případně vlastních dat. Nepovinná jsou pouze vlastní data (nikoliv identifikátor objektu).
· Množina certifikátů může obsahovat certifikáty, které jsou pro uživatele užitečné k tomu, aby sestavil certifikační cestu až ke kořenovému certifikátu. Nikde však není řečeno, že by tam musely být všechny certifikáty, které uživatel bude potřebovat pro verifikaci elektronického podpisu, a mohou tam být i certifikáty, které uživatel vůbec nepotřebuje. Ale teoreticky by tam měly být všechny, o kterých si autor zprávy myslí, že uživatel bude potřebovat pro verifikaci elektronického podpisu. Při tvorbě takovéto zprávy je dobré si uvědomit, že verifikovat ji bude nutné třeba za 10 let a mnohé certifikáty v té době již prošlé může být obtížné obstarávat.
· Položka crls může obsahovat CRL. O CRL platí totéž, co jsem uvedl u certifikátů. Opět je třeba se vžít do role toho, kdo bude elektronický podpis po letech ověřovat a tudíž bude hledat příslušná CRL platná v době podepsání zprávy.
·
Položka signerInfos obsahuje množinu
elektronických podpisů. Už jsem chtěl napsat „… obsahuje množinu elektronických
podpisů vstupních dat“. Což by nebylo správně, protože to by mnohdy bylo málo.
Elektronický podpis nemusí totiž být počítán jen ze vstupních dat, ale i např.
z aktuálního data a času – obecněji z tzv. podepisovaných atributů.
Obecně
může zpráva obsahovat více elektronických podpisů. To je běžné i u rukou
psaného podpisu. Např. pro platební příkazy v bance nad stanovený limit mohou
být požadovány také dva podpisy. Ještě běžnější je podepisování smluv. Smlouva
je vztah minimálně mezi dvěma stranami, takže na smlouvě budou také minimálně
dva podpisy atd.
Poslední položka SignerInfos obsahuje množinu elektronických podpisů. Nyní se podíváme na elektronický podpis podrobněji. Elektronický podpis (struktura signerInfo) je sama strukturou zobrazenou na obr. 8-18.

Obr. 8-18 Struktura elektronický podis
Tato struktura obsahuje následující položky:
· Položka version obsahuje verzi. V případě, že je podepisovaný certifikát identifikován jedinečným jménem CA a číslem certifikátu, pak se použije verze 1 (obdoba PKCS#7). V případě, že je podepisovaný certifikát identifikován identifikátorem klíče předmětu, pak se použije verze 3.
Položka sid obsahuje identifikaci podepisovaného (konkrétně obsahuje identifikaci jeho certifikátu).
·
Identifikací
může být buď sekvence (jedinečné jméno CA, číslo certifikátu) nebo
identifikátor klíče předmětu.
· Položka signatureAlgorithm definuje algoritmus použitý k elektronickému podpisu včetně jeho příslušných parametrů.
· Položka signature obsahuje příslušný elektronický podpis. Asi největším překvapením pro vás bude způsob, jakým se počítá kontrolní součet pro vytvoření elektronického podpisu. Problém je totiž v tom, že je nutné spočíst kontrolní součet nejenom ze samotných vstupních dat, ale i z podepisovaných atributů. Proto se rozlišují dva případy a v každém se kontrolní součet počítá z něčeho jiného:
1. Zpráva neobsahuje žádný podepisovaný atribut. V tomto případě se kontrolní součet spočte ze vstupních dat, tj. z položky eContent.
2. Zpráva obsahuje podepisované atributy. V tomto případě musí být jako podepisované atributy uvedeny: „Kontrolní součet zprávy“ a „Typ podepisovaných dat“. Pro výpočet kontrolního součtu pro vlastní elektronický podpis se pak vezmou všechny podpisované atributy. Kontrolní součet podepisované zprávy je tak obsažen nepřímo v kontrolním součtu, ze kterého se vytváří elektronický podpis.
Pokud chcete programovat výpočet příslušných kontrolních součtů, pak doporučuji si přímo přečíst RFC-2630, kde jsou uvedena jistá upřesnění.
· Položka unsignedAttrs obsahuje nepodepisované atributy podpisu, které se nezahrnují do výpočtu elektronického podpisu. Syntaxe je obdobná podepisovaným atributům.
Důležité podepisované atributy:
·
Atribut „Kontrolní
součet zprávy“ (Message Digest) obsahuje kontrolní součet podepisované zprávy. Kontrolní součet se
počítá z položky eContent.
Identifikátor tohoto atributu je id-messageDigest.
·
Atribut „Typ podepisovaných dat“ (Content Type)
obsahuje identifikátor objektu typu podepisovaných dat. Tím, že se do
elektronického podpisu zahrne jak obsah podepisované zprávy atributem
„Kontrolní součet zprávy“, tak typ dat atributem „Typ podepisovaných dat“, tak
se do elektronického podpisu zahrnou veškeré informace o podepisovaných datech.
·
Atribut „Datum
a čas podpisu“ (Signing Time) obsahuje datum a čas podpisu.
Důležité nepodepisované atributy
·
Atribut
„Kontrasignatura “ (Countersignature) obsahuje „podpis z podpisu“.
Každý elektronický podpis zprávy může obsahovat jeden nebo více atributů
kontrasignatura. Tento atribut se opět skládá ze struktury SignerInfo,
tj. opět obsahuje položku sid, ze které se identifikuje certifikát nutný
k ověření kontrasignatury.
Vstupními daty pro výpočet kontrasignatury je elektronický podpis, tj.
položka signature.
Kontrasignaci známe např. při uzavírání smluv. Smlouvy podepíší ministři
zahraničí, ale až po schválení parlamentem je kontrasignuje prezident republiky.
Typ zprávy „Enveloped Data“
Tato zpráva obsahuje data v elektronické obálce. Pro vytvoření elektronické obálky zprávy jsou nutné certifikáty všech příjemců (adresátů). Princip elektronické obálky spočívá v tom, že zpráva (vstupní data) se šifruje náhodně generovaným symetrickým klíčem. Každý adresát zprávy má pak ve zprávě jeden výskyt položky „Informace pro adresáta“. Struktura „Informace pro adresáta“ v sobě obsahuje ten náhodně generovaný symetrický klíč. Jenže jej neobsahuje jen tak, ale zašifrován veřejným klíčem z certifikátu adresáta.
 Obr.
8-19 Elektronická obálka pro dva adresáty
Obr.
8-19 Elektronická obálka pro dva adresáty
Takto to perfektně pracuje v případě, že adresátův certifikát obsahuje asymetrický šifrovací klíč adresáta – např. pro algoritmus RSA. Asi proto, norma PKCS#7 je podnikovou normou RSA, tak se její tvůrci nezabývali jinými možnostmi. Norma CMS popisuje celkem tři možnosti:
1. Symetrický šifrovací klíč obsahu zprávy je zašifrován veřejným klíčem adresáta (již zmíněná metoda PKCS#7).
2. Z veřejného klíče adresáta a soukromého klíče odesilatele se spočte symetrický šifrovací klíč, kterým odesilatel šifruje obsah zprávy (Diffie-Hellman). Adresát pak z veřejného klíče odesilatele a svého soukromého zjistí symetrický šifrovací klíč zprávy. Adresát tak potřebuje veřejný klíč odesilatele. Proto struktura Enveloped Data musela být rozšířena o položku recipientInfos obsahující certifikáty odesilatele a případně CRL.
3. Symetrický šifrovací klíč obsahu zprávy je šifrován symetrickým šifrovacím klíčem předchozí zprávy. Zpráva proto musí obsahovat identifikaci klíče, kterým je symetrický šifrovací klíč šifrován. Tento případ v podstatě nevyžaduje žádnou asymetrickou šifrovací metodu (poprvé může být klíč distribuován jinou cestou).
Vytvoření elektronické obálky zprávy lze shrnout do následujících bodů (obr. 8-23):
· Vygeneruje se náhodné číslo, které bude použito jako symetrický šifrovací klíč pro šifrování textu zprávy (1).
· Náhodné číslo (šifrovací klíč) se šifruje veřejnými klíči z certifikátù příjemců (2, 3 a 4).
· Pro každého příjemce se vytvoří struktura RecipientInfo (5) obsahující informace pro příjemce. Do této struktury se mj. vloží zašifrované náhodné číslo (zašifrovaný klíč) veřejným klíčem příjemce z jeho certifikátu.
· Data zprávy se šifrují náhodným číslem – symetrickým šifrovacím klíčem (6).
· Vytvoří se struktura EncryptedContentInfo (7) do které se vloží šifrovaná data.
· Vytvoří se výsledná zpráva typu EnvelopedData skládající se z verze, množiny struktur RecipientInfo a struktury EncryptedContentInfo.
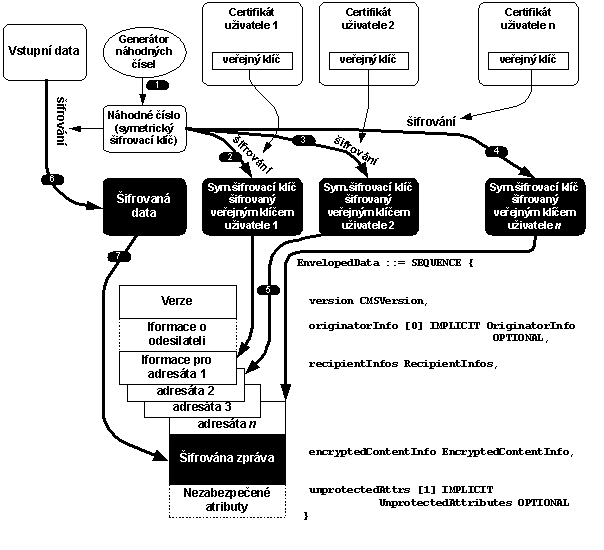 Obr. 8-23 Zpráva v elektronické obálce (případ 1, kdy symetrický šifrovací klíč obsahu zprávy
je zašifrován veřejným klíčem adresáta)
Obr. 8-23 Zpráva v elektronické obálce (případ 1, kdy symetrický šifrovací klíč obsahu zprávy
je zašifrován veřejným klíčem adresáta)
8.8 Protokol DVCSP
Obdržím-li elektronicky podepsaná data, pak zpravidla budu chtít ověřit elektronický podpis těchto dat. Pro ověření elektronického podpisu dokumentu musím:
1. Nalézt certifikát obsahující příslušný veřejný klíč pro ověření tohoto dokumentu.
2. Ověřit platnost tohoto certifikátu. Což je často potíž, protože:
· Musím zjistit, zda-li certifikát není na CRL. Přesněji: musím zjistit, zda-li certifikát nebyl na CRL v době vytvoření elektronického podpisu. Tj. musím zjistit, zdali byl certifikát v době podpisu platný.
· Pokud se jedná o čerstvý dokument (např. právě došlou elektronickou poštu), pak bych se měl dotázat OCSP serveru, zda-li certifikát není odvolán a na aktuálním CRL není pouze proto, že od odvolání certifikátu prostě nové CRL ještě nevyšlo.
3. Musím ověřit elektronický podpis certifikátu. Tj. musím nalézt certifikát certifikační autority, jež certifikát vydala, a ověřit jeho platnost. Také musím ověřit elektronický podpis certifikátu certifikační autority tzn., že musím nalézt řetězec certifikátů až k certifikátu, který považuji za platný díky nějaké předchozí relaci, a u všech mezilehlých certifikátů ověřit jejich platnost a jejich elektronický podpis.
4. U konečného certifikátu musím zjistit, zdali se shoduje s certifikátem, který mám lokálně uložen a kterému důvěřuji díky nějaké předchozí relaci. V mnoha případech bývá tímto certifikátem kořenový certifikát CA.
5. Nakonec, když je příslušný certifikát platný, mohu jeho veřejným klíčem verifikovat dokument.
Jenže ono je to ještě složitější v případě, že na certifikáty aplikujeme certifikační politiku. Tj. používáme rozšíření „certifikační politika“ a rozšíření omezující jména či certifikační politiku apod. V tomto případě máme v ruce ověřený certifikát z hlediska platnosti certifikátu i ověřen elektronický podpis na něm, ale nevíme, zdali jej může použít pro konkrétní aplikaci. Musíme se vnořit do těchto „nepříjemných“ rozšíření a opět ověřit celý řetězec certifikátů.
Je to složité, ale v případě, že potřebujeme ověřit dokument několik let starý, pak získání CRL platných v době podpisu dokumentu i získání všech „starých“ certifikátů do řetězce certifikátů je značně obtížné. Řešením je protokol DVCSP.
Protokol DVCSP (Data Validation and Certification Server Protocols) je specifikován v RFC-3029. Tento protokol v žádném případě nenahrazuje CRL či protokol OCSP. Potřebujeme-li ověřit nějaký elektronicky podepsaný dokument, pak jej protokolem DVCSP zašleme na DVCS server, který nám vrátí buď chybové hlášení nebo nám ověří pravost (tj. platnost) zaslaného dokumentu. Pravost ověřuje vystavením ověřovacího certifikátu (Data Validation Certificate - DVC).
DVCS server je určen pro důvěryhodné třetí strany, které mohou vystavovat ověřovací certifikáty o:
· Držení dat (vlastnictví dat). Tj. uživatel chce od DVCS serveru certifikát o tom, že v konkrétním čase měl nějaká data. Tato data zašle DVCS serveru, který vystavením DVC certifikátu stvrdí tuto skutečnost. Příkladem může být např. ověřovací certifikát pro vyvinutý software.
· Kontrolním součtu z držených dat. Je obdobou předchozí možnosti, avšak necertifikují se celá data, ale pouze kontrolní součet z dat. Certifikace kontrolního součtu se také nazývá časovým razítkem dat
*).
· Pravosti elektronického podpisu dat. Tj. DVCS server provede všechny uvedené body verifikace elektronického podpisu pro všechny elektronické podpisy uvedené v zaslaném dokumentu k datu uvedeném v žádosti o DVC certifikát. Pokud má dokument více elektronických podpisů a pouze některé z nich se DVCS serveru jeví jako nedůvěryhodné, tak to ještě nemusí znamenat, že dokument je celkově nedůvěryhodný. Naopak DVCS server může dokument prohlásit za nedůvěryhodný, i když všechny elektronické podpisy jsou na něm v pořádku, ale celkový počet elektronických podpisů je nesprávný.
· Platnosti certifikátu. Tj. DVCS server ověří, zdali certifikát je platný (např. není odvolán). Důležité je, že DVCS server to zjistí i k uvedenému datu. Důležité je i to, že DVCS server to zjistí i v k uvedenému času v minulosti. Tj. chci-li verifikovat starší dokument podepsaný v konkrétním čase, tak se zeptám na platnost příslušného certifikátu k danému času. DVCS server by měl mít k dispozici veškeré údaje pro zjištění příslušných informací.
Je zjevné, že ověřování platnosti certifikátů a elektronických podpisů dokumentů je netriviální záležitostí, pro kterou je navíc třeba i značné množství informací (např. stará CRL či staré certifikáty certifikačních autorit). Je proto výhodné např. na vnitropodnikové síti zřídit DVCS server, který tyto záležitosti bude vyřizovat centrálně. Tím se zamezí nutnosti všechna uvedená krkolomná ověřování provádět v každé aplikaci.
Ve veřejném sektoru je zase pro uživatele praktické, když služby DVCS serveru nabídne veřejná certifikační autorita.
DVCS server může být kombinován s „Evidenční a záznamovou autoritou“, tj. s aplikací udržující logy a ukládající ověřená data pro případ odmítnutí zodpovědnosti za tato data.
8.9 Time Stamp Protocol (TSP)
Tč. se jedná pouze o návrh protokolu (RFC draft). Zatímco protokol DVCSP je poměrně komplikovaným protokolem, u nějž se předpokládá, že např. pro ověřování elektronického podpisu dokumentu budou aplikace zpočátku implementovat jen část protokolu, tak protokol TSP je jednoduchým protokolem pro vydávání časových razítek.
Protokol TSP je určen pro server označovaný jako „autorita pro vydávání časových razítek (Time Stamping Authority –TSA)“. Předpokládá se, že TSA bude provozovat nějaká důvěryhodná nezávislá organizace.
Jak jsme popsali již v případě protokolu DVCSP, tak časové razítko elektronického dokumentu uživatel získá tak, že na TSA zašle kontrolní součet z tohoto dokumentu a TSA mu vrátí časové razítko, což je elektronicky podepsaný zaslaný kontrolní součet.
Jelikož je časové razítko elektronicky podepsaný dokument, tak si hypoteticky můžeme časová razítka nechat ověřit DVCS serverem.
TSA je povinna:
· Používat důvěryhodný zdroj času.
· Vkládat do každého časového razítka čas.
· Každé časové razítko musí mít své jednoznačné sériové číslo.
· Každé časové razítko musí obsahovat identifikátor objektu politiky TSA (obdoba certifikační politiky u CA), tj. za jakých podmínek je možné vydané časové razítko používat. Politika TSA by též měla obsahovat údaj o tom, zda-li TSA archivuje log vydávání časových razítek, tj. poskytuje možnost dohledat žádost a příslušné vydané časové razítko.
· TSA nesmí zkoumat, z jaké zprávy je kontrolní součet spočten. Pouze formálně zkontroluje tvar kontrolního součtu. (Žadatel s kontrolním součtem zasílá identifikátor objektu algoritmu pro výpočet kontrolního součtu, takže TSA může zkontrolovat např. délku kontrolního součtu apod.)
· TSA nesmí do časového razítka vkládat identifikaci žadatele.
· TSA smí své soukromé klíče používat pouze k podepisování časových razítek, a to způsobem uvedeným v politice TSA. Tj. TSA může mít více certifikátů a odpovídajících soukromých klíčů. Každý pak používá pro konkrétní politiku TSA. TSA může používat klíče různé délky či různých algoritmů tak, aby uživatel byl schopen verifikovat elektronický podpis či aby se optimalizovala režie pro verifikaci podpisu.
TSA může mít více certifikátů. Všechny však musí mít právě jedno rozšíření „Rozšířené použití klíče“.
![]()
9 Certifikační autorita
Pro běžného zákazníka je automobilka továrna vyrábějící automobily. Avšak při podrobnějším zkoumání zjistíme, že se skládá z motorárny, lakovny, karosárny a ostatních provozů. Podobně je to i s certifikační autoritou, jejíž základní schéma je znázorněno na obr. 9-1.
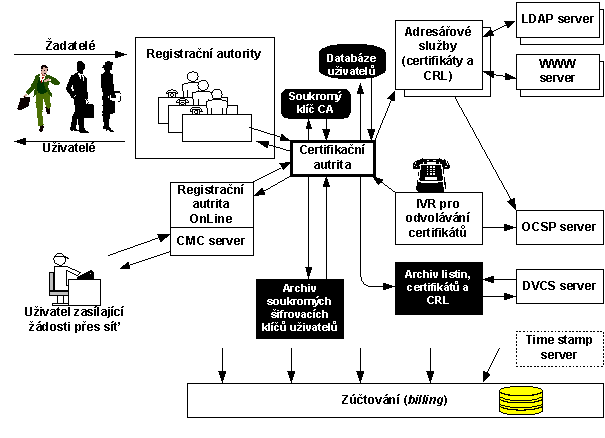
Obr. 9-1 Základní schéma CA
Na počátku je třeba zdůraznit, že mnohé části certifikační autority znázorněné na obr. 9-1 nemusí reálné certifikační autority vůbec mít. Reálné certifikační autority budou mít ty části, které budou odpovídat jimi nabízeným službám, a pochopitelně jejich bezpečnostní politice.
Certifikační autorita má čtyři nejdůležitější aktiva, která musí maximálně chránit:
· Soukromý klíč CA je tím největším aktivem CA. Jeho zcizení je pro CA katastrofou, po které již patrně nemá smysl obnovovat činnost této CA. Se soukromým klíčem musí CA schraňovat též sekvenci vydaných čísel certifikátů. Vydání dvou různých certifikátů se stejným sériovým číslem je opět katastrofou, kterou by CA patrně nepřežila.
· Databázi uživatelů musí CA rovněž chránit, a to hned ze dvou důvodů:
o CA nesmí vydat dvěma různým osobám certifikát se stejným předmětem.
o Databáze uživatelů obsahuje osobní údaje uživatelů (identifikace průkazu totožnosti, rodné číslo apod.).
· Archiv soukromých šifrovacích klíčů uživatelů. Pokud CA tuto službu poskytuje, tak nesmí dopustit, aby se soukromý klíč uživatele dostal do nepovolaných rukou.
· Archiv listin uložených na CA a archiv vydaných certifikátů a CRL. V případě certifikátů a CRL se sice jedná o veřejné informace, ale minimálně po celou dobu existence CA musí být tyto informace dostupné pro verifikaci dokumentů podepsaných certifikáty vydanými touto CA. Jejich ztráta by znamenala, že nelze příslušné podpisy verifikovat.
Dále certifikační autorita může mít:
· Registrační autority, kam přicházejí žadatelé o certifikáty. Žadatel může na registrační autoritu přinést přímo žádost o certifikát, registrační autorita ověří totožnost žadatele, verifikuje žádost o certifikát a předá žádost (zpravidla podepsanou RA) certifikační autoritě. Certifikační autorita ověří údaje z žádosti uživatele a údaje doplněné RA a vydá (či nevydá) příslušný certifikát. Vydaný certifikát může být vrácen na RA, kde je předán žadateli. Jiná strategie spočívá v tom, že RA vydá pouze jednorázové heslo pro vydání certifikátu a uživatel žádost o certifikát pošle elektronicky přes OnLine RA.
· OnLine RA slouží k přijímání žádostí elektronickou cestou. OnLine RA komunikuje protokolem CMC (resp. CMP). Žadatel může přes OnLine RA žádat o:
o Obnovení certifikátu v době platnosti starého certifikátu žadatele.
o O vydání nového certifikátu na základě jednorázového hesla pro vydání certifikátu.
o V případě, že vlastní platný podpisový certifikát, pak může žádat o další certifikáty. Žádosti podepisuje platným certifikátem. (Teoreticky se může žadatel autentizovat i šifrovacím certifikátem.)
o O svůj soukromý šifrovací klíč, který má archivován na CA.
o O odvolání certifikátu.
o O CRL nebo jiný certifikát vydaný CA.
· IVR nebo telefonní záznamník slouží k odvolávání certifikátu jinou cestou (telefonem). Uživatel se autentizuje jednorázovým heslem pro odvolání certifikátu. Odvolané certifikáty se jednak řadí do fronty certifikátů čekajících na odvolání a jednak informace o odvolání certifikátu může být OnLine obratem k dispozici pomocí OCSP serveru.
· Adresářové služby nabízejí informace o uživatelích, které si uživatelé o sobě přejí publikovat, a zejména poskytují vydané certifikáty a CRL. Důležité je, že adresářů může být více. To je důležité zejména při výpadku příslušného serveru CA.
· DVCS server poskytuje protokolem DVCSP informace o platnosti certifikátu, o platnosti listin a dále může poskytovat časová razítka. Platnost certifikátu poskytovaného DVCSP protokolem je zajímavá zejména u starších certifikátů, kdy je již obtížné zjišťovat, zdali certifikát v době podpisu nějakého staršího dokumentu náhodou nebyl odvolán. CA má všechny tyto informace k dispozici a na jednoduchý dotaz dá odpověď, kterou by bylo jinak poměrně komplikované obstarat.
· Dnes se uvažuje též o speciálních serverech poskytujících pouze časová razítka. Důležité je, že TimeStamp server nemusí mít přístup do archivu CA, tj. může být situován i mimo CA a tudíž dostupný i při hypotetickém výpadku CA.
Poslední součástí je zúčtovací systém, jehož cílem je za poskytnuté služby vystavit fakturu uživateli. Mohlo by se zdát, že to sem snad ani nepatří, ale není to až tak triviální problém. Informace o uživatelích jsou totiž dvojí:
· Informace nutné pro vydání samotného certifikátu, tj. zjištěné při ověření totožnosti uživatele (číslo občanského průkazu, fotokopie občanského průkazu apod.). Tyto informace jsou spolu s vydaným certifikátem uloženy v databázi uživatelů a jedná se o osobní údaje uživatelů, které podléhají režimu podle příslušného zákona na ochranu osobních údajů.
· Informace nutné pro vystavení faktury uživateli. Tyto údaje se tisknou na fakturu a jsou tím pádem veřejnými údaji. Kdo tyto údaje nechce zveřejnit, tak zaplatí hotově (peníze jsou anonymní). Tyto údaje jsou vedeny ve zúčtovací databázi.
Důležité je, že obojí údaje musí být přijaty od uživatele na RA. RA pak na CA posílá obojí údaje. Osobní údaje uloží CA do databáze uživatelů a obchodní údaje předá zúčtovacímu subsytému. Důležité je i to, že protokol CMC (resp. CMP), kterým RA komunikují s CA, musí mít možnost (a také má možnost) přenášet obojí údaje.
Další otázkou je, jak CA připojit na Internet. Na obr. 9-2 je jedna z takovýchto eventualit. CA musí být od Internetu bezpečně oddělena. Jelikož uživatelé budou na CA přistupovat z Internetu, tak oddělujícím prvkem nemůže být pouze firewall, ale musí jím být Internetový FrontEnd.
Na Internetovém FrontEndu pak poběží příslušné servery. Důležité je, jestli mohou některé servery běžet někde jinde. To je důležité např. při výpadku CA jako takové. Samostatně může běžet server pro časová razítka, záložní adresářové služby (LDAP a WWW) a případně i OCSP server.
Na obrázku 9-2 je samostatně také nakreslena OnLine registrační autorita. To je však spíše pouze hypotetická možnost, která by měla smysl snad v případě, kdyby OnLine RA bylo více. V takovém případě mohou být některé RA dislokovány např. na intranety významných zákazníků CA.
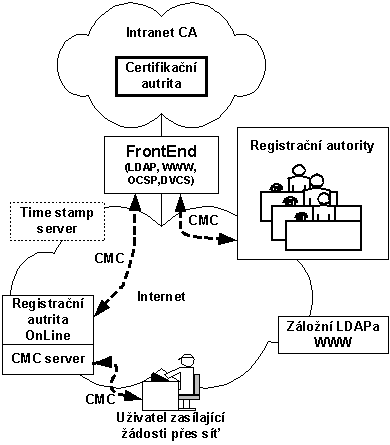
Obr. 9-2 Připojení CA na Internet
9.1 Řetězec certifikátů
Pokud verifikujeme certifikát, pak musíme mít k dispozici množinu certifikátů, ze které lze vybrat řetězec, až ke kořenovému certifikátu (obr. 9-3). Všechny certifikáty do sestavovaného řetězce mohu získat z libovolných zdrojů včetně adresářových služeb s výjimkou kořenového certifikátu – ten musím mít předem získán bezpečnou cestou, protože ten je podepsán sám sebou nelze jej ověřit prostřednictvím elektronického podpisu. Proto může být velice snadno podvržen.
Pokud mi někdo zašle množinu certifikátů i s kořenovými certifikáty, tak tyto kořenové certifikáty mohu použít pouze pro snazší vyhledání řetězce certifikátů. Avšak vždy se musí zkontrolovat, zdali příslušný kořenový certifikát je shodný s některým kořenovým certifikátem získaným jinou – bezpečnou cestou.
Uvažujeme-li, že jednotlivé CA mohou mít i obnovené certifikáty, pak řetězec certifikátů bez rozšíření certifikátu „Identifikace klíče CA“ lze sestavit jen velice špatně.
V neposlední řadě nesmíme zapomenout na bezpečnostní politiku. Je třeba, aby řetězec kvalifikátorů bezpečnostních politik (OID bezpečnostních politik) sahal též až ke kořenovému certifikátu. (Microsoft certifikáty s těmito rozšířeními nazývá kvalifikovanými certifikáty a již ve Windows XP bude i tuto kontrolu podporovat).
Dále je nutné u jednotlivých certifikátů zkontrolovat, zdali nejsou odvolány (nejsou na CRL).
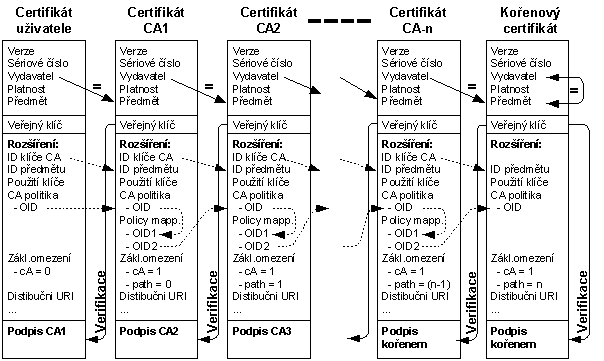
Obr. 9-3 Řetězec certifikátů
Za důvěryhodný certifikát není nutné vždy prohlásit až kořenový certifikát. Pokud se za důvěryhodný certifikát prohlásí některý z certifikátů uprostřed řetězce mezi certifikátem uživatele a kořenovým certifikátem, pak se verifikace provádí pouze k tomuto důvěryhodnému certifikátu a celé ověřování se tím výrazně zrychlí.
Pro bezpečnost počítače je zásadní seznam důvěryhodných certifikátů, který je instalován na počítači. Pokud se na tento seznam podaří podvrhnout např. certifikát některé z testovacích certifikačních autorit, tak máme o nepříjemnosti postaráno. Přitom starší verze prohlížečů byly distribuovány s celou řadou certifikátů certifikačních autorit o kterých jsme nikdy nemohli vědět jestli jsou důvěryhodné. A tak první operací po instalaci prohlížeče bylo zrušení těchto certifikátů a vložení důvěryhodných certifikátů (důvěrných certifikačních autorit).
Windows 2000 zavádí tzv. CTL (Certificate Trusted List) tj. seznam důvěryhodných certifikátů, který je podepsán správcem podnikové sítě. Windows 2000 pak akceptují jako důvěryhodné pouze certifikáty z tohoto seznamu.
9.2 Křížová certifikace
Doposud jsme předpokládali, že certifikační autority tvoří stromovou strukturu. Avšak je možná i jiná struktura – křížová.
Dvě certifikační autority, které nejsou zařazeny do téže stromové struktury, si mohou vzájemně podepsat své certifikáty – provést křížovou certifikaci. Pro úplnost je třeba dodat, že křížově se mohou certifikovat i CA patřící do společného stromu – to má však význam, když je strom příliš košatý a CA leží na velmi vzdálených větvích stromu; pak lze křížovou certifikací jejich vzdálenost zmenšit.
Avšak vraťme se na počátek k vysvětlení podstaty křížové certifikace.
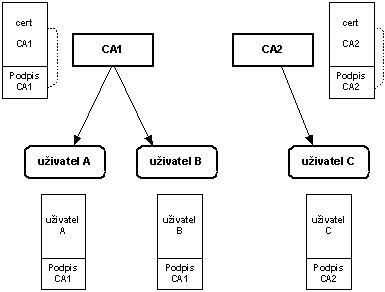
Obr. 9-4 CA1 není křížově certifikována CA2
Na obr. 9-4 jsou dvě certifikační autority CA1 a CA2. Uživatel A bez potíží komunikuje s uživatelem B,. protože uživatel A uznává CA1 jako důvěryhodnou. V případě, že uživatel A obdrží certifikát uživatele B, pak si sestaví řetězec certifikátů z certifikátu uživatele B a certifikátu CA1. CA1 je kořenová certifikační autorita, které uživatel A důvěřuje. Tj. uživatelé A a B společně důvěřují certifikační autoritě CA1.
V případě, že ale chce s uživatelem B komunikovat uživatel C, tak je tomu již jinak. Uživatel C si sestaví řetězec certifikátů počínající certifikátem uživatele B – ten ale končí vždy u CA1, které uživatel C nedůvěřuje, protože ji nezná.
Řešením je, že CA1 si kromě svého původního kořenového certifikátu nechá vydat další certifikát, tentokrát certifikační autoritou CA2 (obr. 9-5). CA1 tak má svůj kořenový certifikát a navíc další křížový certifikát, který je vydán CA2.
V případě, že uživatel C chce komunikovat s uživatelem B, tak B mu pošle množinu certifikátů obsahující:
· Certifikát B,
· Certifikát CA1 podepsaný CA1 (kořenový certifikát CA1),
· Certifikát CA1 podepsaný CA2,
·
(Certifikát CA2 podepsaný CA2 by měl uživatel C mít,
protože mu sám důvěřuje).
Uživatel si najde řetězec, kterému může důvěřovat. Jedná se následující řetězec zakončený pro něj důvěryhodnou CA2: B -> CA1 podepsaný CA2 -> CA2 podepsaný CA2. Tak se stane certifikát uživatele B důvěryhodným i pro uživatele C, který důvěřuje CA2.
Je zajímavé, že stejnou množinu certifikátů může od B obdržet i A, ten si ale vybere z této množiny kratší řetězec: B -> CA1 podepsaný CA1.
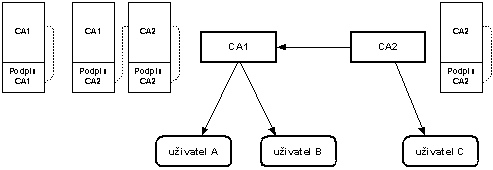
Obr. 9-5 CA2 křížově certifikovala CA1
Touto křížovou certifikací se CA1 a její uživatelé stali důvěryhodní pro CA2 a její uživatele. Není tomu však naopak. Aby tento vztah byl oboustranný, tak je nutné, aby i CA2 si nechala vydat certifikát u CA1 (obr. 9-6).
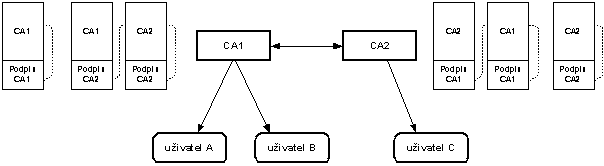
Obr. 9-6 Oboustranná křížová certifikace CA1 a CA2
Výsledkem je, že máme čtyři certifikáty:
1. CA1 podepsaný CA1.
2. CA2 podepsaný CA2.
3. CA1 podepsaný CA2.
4. CA2 podepsaný CA1.
9.3 Obnovení certifikátu CA
Se skutečností, že je nutné obnovovat i certifikáty samotné certifikační autority, jsme se seznámili již na obr. 8-6. Tam jsme si objasnili, že nový certifikát CA je nutné vydat s takovým předstihem, aby soukromým klíčem náležejícím ke starému certifikátu nebyly vydány certifikáty, jejichž platnost skončí později než platnost klíče, kterým byly podepsány.
Jenže v době, kdy platí oba certifikáty CA, starý i nový, tak někteří uživatelé mají podepsány své certifikáty starým a někteří uživatelé novým soukromým klíčem CA. Je to vlastně obdoba křížové certifikace.
Aby uživatelé s certifikátem podepsaným starým klíčem důvěřovali certifikátům podepsaným novým klíčem, tak je ideální udělat křížovou certifikaci. Opět získáme čtyři certifikáty:
1. Nový.
2. Starý.
3. Nový podepsaný starým.
4. Starý podepsaný novým.
Druhé dva by měly mít omezenou platnost na dobu, po kterou se překrývá platnost dvou prvních certifikátů. Jelikož PKI nedoporučuje používat rozšíření „Doba platnosti soukromého klíče“, které je pro tyto účely určeno, tak se to musí udělat pomocí doby platnosti certifikátu.
Podepsání nového certifikátu CA starým soukromým klíčem CA je poslední akce, kterou bychom se starým soukromým klíčem měli udělat. Poté by měl být zlikvidován, neboť je zbytečné ochraňovat to, co je již nepotřebné.
Poznámka: Nyní si představte, že máte křížově certifikované certifikační autority CA1 a CA2 a je třeba obnovit jejich certifikáty. Kolik budete muset vydat certifikátů? (Nedej bože, abyste měli těch křížově certifikovaných autorit více než dvě.) Připomíná mi to silně úlohu: „Jde starý stopař se svým velkým synem. Vystopují dvě ženské stopy: stopy velké nohy a stopy malé nohy. I rozhodnou se, že obě ženy vystopují; a až je vystopují, tak je pojmou za manželky. Starý stopař si vezme tu co má velké stopy a mladý tu co má malé stopy. Když je vystopují, tak zjistí, že to jsou matka s dcerou. Matka má menší nohu než dcera. Tj. na otce připadla dcera a na syna matka. Po čase se jim narodí děti. Úlohou je vyjmenovat všechny příbuzenské vztahy, které tím vzniknou.
9.4 Certikační politiky (certifikační zásady)
Na obr. 9-3 je znázorněno, že při verifikaci certifikátů se neověřuje pouze elektronický podpis certifikátu, ale též certifikační politika (nazývanou též certifikačními zásadami). Ta by měla být v celém řetězci certifikátů stejná. Ve složitějším případě (uvedeném na obr. 9-3) může být pomocí rozšíření certifikátu Policy Mapping provedena transformace politiky podřízené CA na odpovídající politiku nadřízené CA. Tento složitější případ je aktuálním např. v případě křížové certifikace.
Co to je certifikační politika? Certifikační politika je dokument (text) ze kterého by mělo být jasné pro jaké aplikace je vydaný certifikát určen. Dále by mělo být v certifikační politice popsáno jaký je vztah mezi uživatelem a údaji uvedenými v certifikátu, tj. jak a jakým způsobem ověřuje certifikační autorita totožnost žadatele o certifikát. V certifikátu může být uvedeno více certifikačních politik.
Certifikační autorita si pro jednotlivé své certifikační politiky nechá přiřadit identifikátory objektů (identifikátory certifikačních zásad). V rozšíření certifikátu „Certifikační politiky“ se pak uvádí tyto identifikátory objektů (položka policyIdentifier).
Otázkou je zdali má praktický smysl v jedné firmě vydávat certifikáty s různými certifikačními politikami. Příklad je asi následující: V naší firmě vydáme všem zaměstnancům certifikát, aby mohli komunikovat bezpečnou elektronickou poštou. Pro tyto certifikáty použijeme „všeobecnou certifikační politiku“. Avšak pro zaměstnance, kteří budou podepisovat finanční transakce vydáme „finanční certifikační politiku“ a do jejich certifikátů budeme vkládat identifikátor objektu této „finanční certifikační politiy“. Někteří zaměstnanci tak mohou mít ve svém certifikátu identifikátory objektů obou politik. Ve finančních aplikacích pak zajistíme, aby fungovali pouze certifikáty splňující „finanční certifikační politiku“.
Rozšíření certifikátu „Certifikační politiky“ může být označeno jako kritické. V tomto případě pro příznak kritičnosti rozšíření certifikátu platí důležitá výjimka (viz kap. 3.3.1 v RFC-2527). Totiž pokud je rozšíření „Certifikační politiky“ označeno jako kritické, pak použití takto označeného certifikátu je omezeno pouze na aplikace vyhovující alespoň jedné z certifikačních politik uvedených v certifikátu. Pokud vyvinu aplikaci A pro své zákazníky a vydám jim firemní certifikáty, pak se mohu bránit tomu, aby zákazník podepsal nějaký dokument jménem firmy tím, že vydám certifikační politiku pro aplikaci A a identifikátor objektu této certifikační politiky uvedu v rozšířením „Certifikační politiky“, které označím jako kritické.
Rozšíření „Certifikační politky“ může obsahovat parametry (kvalifikátory):
· Hypertextový odkaz (URI) na Certifikační prováděcí směrnici (Certification Practice Statement - CPS).
· Poznámku označovanou též jako „prohlášení vystavitele“ nebo „uživatelské oznámení“ (explicitText), která v nejvýše 200 znacích úderně charakterizuje účel použití certifikátu.
CPS (hovorově „CPSka“) je patrně nejdůležitější dokument certifikační autority. V něm jsou detailně uvedena pravidla a praktiky prováděné zaměstnanci certifikační autority při vydávání certifikátu. Jedná se o dokument, který musí být dostupný klientům certifikační autority (je na něj hypertextový odkaz z certifikátu). (V případě veřejných certifikačních autorit je to tedy veřejný dokument.)
CPS nevytváříme pouze pro certifikační autority, ale vytvářejí si ji i firmy, které si nechávají vystavit certifikáty od externích (veřejných) certifikačních autorit. Každá firma využívající PKI by měla mít vytvořenu CPS. Netřeba se bát vytvoření tohoto dokumentu. Využijeme RFC-2527, které je kuchařkou na tvorbu CPS. Je zde velice podrobný obsah, který stačí přeložit do češtiny a doplnit. Na mnoha místech, kde byste mohli být bezradní co napsat, tak je odkaz do dodatku, kde je vždy ještě podrobnější komentář.
9.4.1 Testovací certifikační autority
Pro testovací účely jsou často provozovány certifikační autority, které nijak neprověřují totožnost žadatele. Zašlete na takovou certifikační autoritu žádost a ona vám automaticky vydá certifikát. Takováto certifikační autorita garantuje jedinou věc – a to, že nevydá dva různé certifikáty o stejném sériovém čísle. U takto vystavených certifikátů je slušné, aby v „prohlášení vystavitele“ bylo jasně uvedeno, že se jedná o testovací certifikáty.
Pokud byste chtěli testovací certifikát použít pro praktickou komunikaci, pak se jedná o certifikát jako každý jiný – pouze neproběhlo ověření totožnosti žadatele. Takže si ověření totožnosti musíte provést při použití certifikátu sami.
Např. šéf bandy lupičů si nechá vystavit certifikát na testovací certifikační autoritě. Distribuuje jej tak, že všem svým podezřelým banditům rozešle tímto certifikátem elektronicky podepsaný mail s bezvýznamným textem obsahujícím např. pozdrav k Vánocům.
Jednotliví
lupiči se pak telefonicky spojují se svým šéfem a ověřují si jeho totožnost
např. na nějaký společný zážitek: „Hele šéfe pamatuješ si, jak jsme byli minulý
týden na tahu … Kolik tam bylo blondýnek?“ Pokud šéf správně odpoví, že tam
nebyla žádná blondýnka, pak lupič opravdu ví, že mluví se svým šéfem. Zbývá tedy otázka: „Zarecituj mi miniaturu
(otisk, kontrolní součet) certifikátu, kterýms podepsal svůj mail. Pokud např.
odpoví: „D96F 563E E0EC 3570 94BB
DF05 75D6 300E 563E E0EC“, tak si lupič zobrazí podrobnosti o inkriminovaném
certifikátu a podívá se jestli položka „Miniatura“ opravdu obsahuje šéfem
zarecitovaný kontrolní součet. Pokud ano, pak lupič zafungoval jako registrační
autorita a vím, že certifikát může použít k šifrování svých pravidelných
hlášení šéfovi.
9.5 Vytvoření žádosti o certifikát
V kapitole 8 jsem popsal formáty žádosti o certifikát tvaru PKCS#10 i CRMF. Tyto žádosti může žadatel vytvořit nějakým svým programem. Takové programy jsou dodávány např. s webovými servery. Ale běžný uživatel, který si chce vystavit certifikát zpravidla nemá tyto programy k dispozici. Má k dispozici pouze běžný prohlížeč.
Otázkou je jak vytvořit běžným prohlížečem žádost o certifikát. V praxi se setkáváme z dvěma způsoby generování žádosti o certifikát v prohlížeči:
· Využitím programové komponenty, která je součástí webové stránky.
· Použitím speciální značky, která rozšiřuje jazyk HTML o možnost generování žádosti o certifikát.
9.5.1 Žádost formátu SPK
Netscape definuje zvláštní HTML značku <keygen> sloužící k vygenerování dvojice veřejný/soukromý klíč. Odeslání tohoto formuláře způsobí:
· Vygenerování dvojice klíčů veřejný/soukromý klíč.
· Veřejný klíč podepíše vygenerovaným soukromým klíčem
· Base64 kódovaný veřejný klíč včetně jeho podpisu vloží do obsahu pole HTML stránky jež obsahuje značku <keygen>.
Tato
žádost o certifikát se označuje jak žádost formátu SPK. Žádost formátu SPK je
nestandardní typ žádosti o certifikát, protože neobsahuje elektronický podpis
celé žádosti, ale pouze podpis veřejného
klíče. Normy PKI tento formát žádosti v podstatě neznají, ale
certifikační autority jej často podporují.
Jako příklady generování žádostí formátu SPK („žádostí pro Netscape“) mohou opět sloužit žádosti o vydáni certifikátu vystavené na www.ica.cz.
![]()
10 Jaké certifikáty budeme používat?
Z technického hlediska můžeme mít jeden certifikát pro všechno. Pro podepisování, pro autentizaci i pro šifrování (obálkování). Jak jsme si ukázali v kap. 7 tak není úplně ideální mít společný certifikát pro pospis a pro autentizaci (autentizací je i např. přihlášení do Windows 2000 atp.).
Jiný problém je s šifrovacími certifikáty. Pokud totiž ztratím soukromý klíč, pak nejsem schopen dešifrovat staré zprávy zašifrované příslušným veřejným klíčem. Je tedy praktické archivovat soukromé šifrovací klíče. Tuto službu může poskytovat i certifikační autorita.
Naopak v připadě elektronického podpisu starý soukromý klíč zlikviduji jakmile jej již nepotřebuji. Staré elektronické podpisy se verifikují pomocí veřejného klíče a ten je v certifikátu. A certifikát, ten musí být archivován minimálně na certifikační autoritě. Soukromý klíč pro elektronický podpis nikdy neádávám z ruky – ani certifikační autoritě!
Výsledkem jsou tři aktuální certifikáty:
1. Pro elektronický podpis. Příslušný soukromý klíč budu mít nejspíše na čipové kartě.
2. Pro autentizaci. Příslušný soukromý klíč budu mít nejspíše rovněž na čipové kartě.
3. Pro šifrování (přesněji pro dešifrování elektronických obálek) jej budu mít na disku a zálohován v nějakém důvěryhodném uložišti.
Jinými kritérii je délka klíče. Nebo certifikační politika vyznačená v certifikátu atd. Kvalifikované certifikáty mohou mít v rozšíření specifikováno pro hodnotu transakce do které je elektronický podpis verifikovaný tímto certifikátem pojištěn atd.
![]()
11 Elektronická pošta
11.1 Architektura elektronické pošty
Základní představa architektury elektronické pošty (obr. 11-1) na Internetu pochází z poloviny 70. let. Dnes je základem poštovní komunikace na Internetu norma RFC-821 z roku 1982 (tvar poštovní zprávy popisuje RFC-822). Tehdy uživatelé seděli u terminálů, ze kterých spouštěli poštovní klienty. Poštovní klient nemá nic společného se síťovou komunikací, poštovní klient je v podstatě pouze specializovaný textový editor. Tento textový editor umí uživateli zobrazit obsah zprávy z poštovní schrány, umí manipulovat se zprávami v poštovní schránce a totéž umí také s privátními poštovními schránkami uživatele. Dále poštovním klientem je možné zprávu pořídit a odeslat. Opět odesláním se nerozumí nějaká síťová komunikace, ale uložení zprávy do fronty zpráv.
Fronta zpráv je pak pravidelně procházena SMTP klientem, který navazuje spojení se vzdálenými SMTP servery, kterým zprávu předá.
SMTP server přijme zprávu a zjišťuje, zda-li je určena pro jeho lokální uživatele. V případě, že nikoliv, pak zprávu opět uloží do poštovní fronty, kterou obsluhuje jeho poštovní klient jenž se pokouší zprávu doručit směrem k adresátovi.
V případě, že adresát je lokálním uživatelem systému, pak SMTP server uloží přijatou zprávu do poštovní schránky adresáta. Zde je třeba upozornit, že poštovní server mívá přístupová práva ke všem uživatelům svého systému. Tj. SMTP server bývá spuštěn pod privilegovaným uživatelem. Pokud by tak útočník se dokázal prolomit do poštovního serveru, pak může získat neomezený přístup do systému. Proto je správnější jiný postup: poštovní server běží pod jiným uživatelem než superuživatgelem a přístup do poštovních schránek uživatelů se mu zajistí přes skupinová práva.
Uživatel má v systému zpravidla jednu poštovní schránku INBOX, kam SMTP server ukládá jeho příchozí poštu. Ona se ta poštovní schránka nejmenuje INBOX jako soubor, ale zpravidla má jméno shodné se jménem uživatele. Název INBOX pro ni používá protokol IMAP4.
Kromě toho si uživatel může zřídit i privátní poštovní schránky, kam si ukládá ze schránky INBOX došlou poštu. Privátní poštovní schránky nejsou obsluhovány SMTP serverem a bývají zřizovány pod domovským adresářem uživatele. Cílem je přimět uživatele k tomu, aby v „systémové“ schránce INBOX příchozí poštu nearchivovali. Tohoto cíle dosahují i někteří poštovní klienti tím, že pokud příchozí poštu uživateli zobrazí, tak ji automaticky přenesou do privátní poštovní schránky, kterou pokud uživatel nepojmenuje jinak, tak pojmenují INBOX nebo inbox, ale v domovském adresáři uživatele.
Internetová pošta má díky ukládání odchozí pošty do fronty a ukládání příchozí pošty do poštovní schránky jednu zásadní vlastnost. Tou je skutečnost, že uživatel může „odeslat“ mail, který si příjemce může vyzvednout ze své schránky až bude chtít. Tj. není nutné okamžitě navazovat spojení na příjemcův systém v době odeslání pošty. Příjemcův systém může být i vypnut v době, kdy odesilatel zprávu odesílá. Nepodaří-li se klientovi SMTP odeslat poštu, tak ji ponechá ve frontě. Zpráva pochopitelně nebude ve frontě do nekonečna. Správce systému má většinou nastavenu maximální dobu položky v poštovní frontě na 2-7 dní. Poté se pošta vrací odesilateli jako nedoručená.
Je to ještě komplikovanější. SMTP klient nemůže odeslat zprávu z mnoha důvodů. Je na správné konfiguraci aby v podstatě rozlišovala mezi dvěmi situacemi:
· Momentálně např. nelze poštu dále doručit, ale je pravděpodobné, že za jistou dobu to půjde (např. jméno cílového systému se přeložilo v DNS, ale systém je nedostupný).
· Zprávu nelze doručit pro chybu, kterou nelze odstranit (např. jméno vzdáleného systému je správně, ale uvedený adresát na systému neexistuje). V takovém případě je třeba zprávu neštosovat ve frontě, ale okamžitě vrátit odesilateli.
Obr. 11-1 Architektura SMTP
Na obr. 11-1 uživatel A chce odeslat zprávu elektronickou poštou uživateli B. Uživatel A pomocí svého poštovního klienta pořídí zprávu. Nakonec pořízenou zprávu „odešle“, avšak odeslání je pouze uložení zprávy do fronty. Klient SMTP prochází frontu až dorazí na naší zprávu. Zprávu se pokouší doručit na adresátův systém, pokud se mu to nepodaří, tak zprávu ponechá ve frontě.
V případě, že server zprávu přijme, pak zkoumá, zda-li je adresát zprávy lokálním uživatelem systému, pak mu zprávu uloží do jeho poštovní schránky. V případě, že adresát není lokálním uživatelem systému, tak zprávu uloží do fronty k odeslání dále.
Příjemce si pak může přijatou zprávu zpracovat svým poštovním klientem.
S příchodem osobních počítačů přišel zvrat i v používání elektronické pošty. Ve svém jádře elektronická pošta zůstala zachována, avšak uživatel již nechce sedět u terminálu poštovního serveru (byť emulovaného protokolem Telnet na svém PC), ale chce využívat aplikace na svém PC. Otázkou je, jak z PC poštu odeslat a jak na PC poštu přijmout.
Zatímco při odesílání pošty z PC lze vcelku bez problému opět použít protokol SMTP, tak pro příjem pošty z poštovního serveru na PC není protokol SMTP tím pravým. Co by to totiž znamenalo? Příjemce má své PC zapnuto zpravidla jen několik hodin. Mimo tuto dobu by zůstávala pošta v odesilatelově frontě a příjemcův systém by se jevil jako nedostupný. Dalším problémem je, že na příjemcově PC by musel běžet SMTP server. Zvolila se proto jiná strategie znázorněná na obr. 11-2.
Uživatel má svou příchozí poštovní schránku (INBOX) na poštovním serveru. Tj. z hlediska protokolu SMTP je poštovní server cílovou stanicí. Zůstává vyřešit, jak si vybírat INBOX ze svého PC.
Pro práci s poštovní schránkou uživatele na poštovním serveru jsou k dispozici dva protokoly (oba jsou podporovány jak klienty Microsoft, tak klienty Netscape):
· Protokol POP3. Jedná se o velice jednoduchý protokol, kterým pracuje uživatel OffLine. Tj. z poštovního serveru si uživatel stáhne příchozí poštu na své PC a ukončí TCP spojení se serverem. Teprve po stažení pošty uživatel pracuje s jednotlivými poštovními zprávami. V případě, že chce uživatel poštu odeslat, pak použije protokol SMTP.
· Protokol IMAP4. Jedná se o komplikovaný protokol, který umožňuje nejen pracovat OffLine, ale i OnLine. Uživatel může mít navázáno spojení s poštovním serverem delší dobu a být serverem průběžně informován o změnách ve své poštovní schránce. Protokol IMAP umožňuje též pracovat s privátními poštovními schránkami přímo z terminálu na serveru . Protokolem IMAP4 je možné také synchronizovat poštovní schránky na PC a na serveru. Schránky na serveru tak zůstávají zálohou schránek na PC. V případě, že chce uživatel poštu odeslat, pak také použije protokol SMTP. Použití protokolu IMAP je praktické zejména v případě, že občas chceme pracovat z PC a občas z terminálu serveru.
Obr. 11-2 Protokoly POP3 a IMAP4
Otázkou je kdy zvolit POP3 a kdy IMAP4. Odpověď je jak kdy. Např. pro velké poskytovatele internetových služeb je velice výhodný protokol POP3, protože pošta nezůstává na serveru (obr. 11-3). Uživatelé si ji stahují na svá PC. Při představě, že sto tisíc uživatelů má trvale svou poštu na serveru, pak žádná disková kapacita není dostatečná pro takové ohromné množství dat. To může být příležitost pro malé poskytovatele, kteří mohou poskytovat některým svým klientům nadstandardní službu privátních poštovních stránek na serveru.
Naopak pro menší firmy je výhodný protokol IMAP4, protože se tím provádí záloha poštovních schránek. A je jednodušší zálohovat jednu diskovou kapacitu, než aby si to dělal každý uživatel sám. Přitom ztráta obsahu poštovní schránky může pro vedoucího pracovníka způsobit i velké ekonomické škody. Je proto nutné při použití protokolu POP3 dbát na to, aby pošta byla zálohována např. na server, na diskety či na magnetickou pásku.
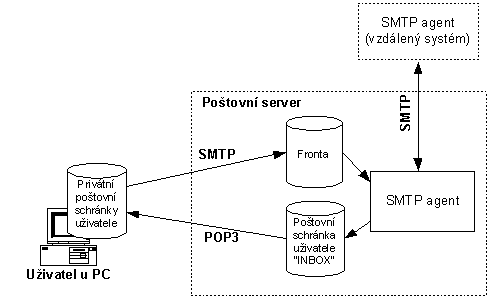
Obr. 11-3 Pošta v případě velkých poskytovatelů internetových služeb
Na obrázcích neuvádíme slovo poštovní server, ale SMTP agent. Je to proto, že na poštovním serveru je vždy SMTP klient pro odesílání pošty a SMTP server pro příjem pošty. Navíc software poštovního klienta musí v pravidelných intervalech procházet frontu a její položky se snažit odeslat. Tj. jedná se o službu (resp. démona), který stále běží. A jen v okamžiku odesílání jedné položky fronty se tento démon chová z hlediska protokolu TCP jako klient.
11.2 Formát poštovní zprávy
Formát poštovní zprávy je specifikován normou RFC-822. Zpráva se skládá ze záhlaví a těla zprávy. Záhlaví je od těla zprávy odděleno jedním prázdným řádkem (CRLF CRLF). Záhlaví i tělo zprávy jsou tvořeny pouze ASCII znaky!
Záhlaví se skládá z jednotlivých hlaviček. Hlavička začíná klíčovým slovem ukončeným dvojtečkou. Za klíčovým slovem mohou následovat parametry. Hlavička se ukončuje koncem řádku, tj. CRLF.
Mezi jednotlivými částmi hlavičky mohou být vkládány mezery a tabelátory. Hlavička může pokračovat na další řádek. Další řádek však v takovém případě musí začínat mezerou nebo tabelátorem (klíčové slovo hlavičky musí být odsazeno od první pozice řádku).
Zejména v adrese mají důležitý význam následující znaky:
· Středník a dvojtečka mají význam oddělovače v seznamu. Např. při oddělování jednotlivých adresátů v hlavičce TO.
· Špičaté závorky <> mají speciální význam v adrese. Vyskytuje-li se v adrese řetězec ve špičatých závorkách, pak se vše mimo tento řetězec ignoruje – za adresu se vezme řetězec ze špičatých závorek.
· Hranaté závorky [ ] mají význam ve jméně počítače; signalizují, že jméno počítače nemá být překládáno v DNS.
· Do kulatých závorek ( ) se uzavírá komentář.
Příklad:
From: Libor Dostalek
dostalek@pvt.cz;
Frantisek.Novak@firma.cz
To: Novak@[195.47.40.4] (to je primo
IP-adresa)
11.2.1 Přehled základních hlaviček z RFC-822
|
Hlavička |
Význam |
|
Received: |
Tuto hlavičku připisuje na počátek mailu každá mailová gateway (mailový server), kterou zpráva prochází. Takže čteme-li hlavičky Received: od spodu nahoru, tak zjistíme celou trasu, přes které mailové servery zpráva šla. V této hlavičce se mohou vyskytovat slova:
|
|
From: |
Od |
|
Sender: |
Vyřizuje (sekretářka) – prakticky zde bývá např. informace
o konferenci, přes kterou zpráva přišla |
|
Date: |
Datum odeslání |
|
Reply-To: |
Odpověď zasílejte na |
|
In-Reply-To: |
Odpovídáme Vám na vaší zprávu: Identifikace původní zprávy |
|
To: |
Adresát |
|
Cc: |
Na vědomí (Carbon Copy) |
|
Bcc: |
Tajná kopie - tato hlavička se před odesláním smaže
(Blind Carbon Copy) |
|
Message-Id: |
Identifikace zprávy. |
|
Keywords: |
Klíčová slova charakterizující obsah |
|
References: |
Další odkazy |
|
Subject: |
Věc (krátká charakteristika obsahu zprávy) |
|
Comments: |
Komentář |
|
Encrypted: |
Šifrováno (zastaralé) |
|
X- |
Uživatelsky definovaná hlavička (uživatelem se
rozumí autor software). Např. X-Mailer se často používá pro specifikaci
programu, kterým odesilatel odesílá zprávu |
|
Resent- |
Při automatickém předávání zprávy (např. vrácení
nedoručitelné zprávy) se před původní hlavičky vloží řetězec Resent-
Např.Resent-From nebo Resent-Cc apod. |
Příklad:
Received: from mh.pvt.cz (mh.pvt.cz [194.149.105.36])
by cbu.pvtnet.cz (8.8.5/8.7.3)
with SMTP id PAA23028;
Wed, 16 Apr 1997 15:10:14 +0200 (MET DST)
Received: from ncc.ripe.net by mh.pvt.cz
with SMTP id AA08008 (5.67b/IDA-1.5
for <registr@pvt.cz>);
Wed, 16 Apr 1997 15:05:09 +0200
Received: by ncc.ripe.net
id AA00228 (5.65a/NCC-2.41);
Wed, 16 Apr 1997 13:55:02 +0200
Received: from mail.freedotnet.net
by ncc.ripe.net with SMTP
id AA00215 (5.65a/NCC-2.41);
Wed, 16 Apr 1997 13:55:00 +0200
Received: from jon.freedotnet.net ([208.215.186.129])
by homer.freedotnet.com (Netscape Mail Server v2.02)
with ESMTP
id AAA105 for <local-ir@ripe.net>;
Wed, 16 Apr 1997 13:09:15 +0100
Reply-To: <jon.brody@freedotnet.net>
From: "Dr Jon Brody" <jon.brody@freedotnet.net>
To: <local-ir@ripe.net>
Subject: Re: Role?
Date: Wed, 16 Apr 1997 12:58:51 +0100
X-Mailer: Microsoft Internet Mail 4.70.1155
Text mailu
Hlavičky této zprávy se musí rozdělit na hlavičky začínající Received a ostatní hlavičky. Hlavičky Received přidávají na začátek zprávy poštovní servery, kterými zpráva prochází. Proto u hlaviček Received záleží na pořadí. Hlavička Received, kterou přidal první server je poslední. Hlavička Received před ní je hlavičkou, kterou přidal další server atd.
Čteme-li
hlavičky Received od spodu nahoru, pak vidíme, že zpráva byla odeslána z
počítače jon.freedotnet.net, pak ji zpracovával počítač homer.freedotnet.net
(počítač mail.freedotnet.net je jen jiné jméno téhož počítače). Dále zpráva
putovala na ncc.ripe.net, který ji předal na mh.pvt.cz a nakonec skončila na
cbu.pvtnet.cz.![]()
12 MIME
Formát zpráv protokolu SMTP definovaný normou RFC-822 umožňoval přenášet data pouze formátu US-ASCII. Brzy se však ukázalo, že tento standard nevyhovuje mnohým požadavkům uživatelů, kteří chtějí elektronickou poštu využít i pro posílání textu jiných znakových sad, formátovaného textu, obrázků, zvuků, obecně binárních souborů atp. V poslední době pak přibyl požadavek na posílání zabezpečených zpráv, tj. šifrovaných zpráv nebo elektronicky podepsaných zpráv.
Požadavky uživatelů rychle překročily možnosti nabízené normou RFC821. Objevilo se tak rozšíření MIME (Multipurpose Internet Mail Extension) dnes specifikované normami RFC-2045 až 2049.
Problém jak poslat elektronickou poštou zprávu obsahující jiná data než text v kódu US-ASCII lze řešit i bez MIME. Znamená to zprávu před odeslání zakódovat do US-ASCII. Příjemce pak musí nejprve zprávu dekódovat a pak ji může teprve zpracovat (přečíst). Odesilatel a příjemce se musí jinou cestou dohodnout na typu kódování přenášených dat do US-ASCII. V praxi se zpravidla používá kódování Base64, Quotet Printable nebo v UNIXu kódování UUENCODE. Zkušený příjemce se podívá na zakódovaná data a na první pohled vidí jak jsou data zakódovaná a podle kódování se rozhodne použít vhodný dekódovací program na přijatá data před tím, než je bude zpracovávat (např. číst).
Tato
cesta je pro běžné uživatele nepřijatelná. Uživatel si nepřeje se nějakým
kódování zabývat – přeje si, aby tyto problémy za něj vyřešil software
poštovního klienta sám. Pro běžného uživatele je tak přijatelná druhá možnost
spočívající v myšlence rozšířit repertoár hlaviček zprávy o hlavičky popisující
typ přenášených dat a algoritmus, kterým byla data před odesláním zakódována do
US-ASCII. Tím je pak možné celý proces zautomatizovat, aniž by do něj musel
uživatel zasahovat. Popis dodatečných hlaviček specifikuje právě norma MIME.
V tomto případě může příjemcův software z hlaviček automaticky rozeznat, jak byla data kódována, a automaticky zprávu dekódovat. Navíc v hlavičce Content-Type odesilatelův software uloží typ přenášených dat, podle kterého příjemcův software automaticky rozpozná, jakým prohlížečem má data příjemci zobrazit. Příjemci pak podle typu přenášených dat spustí příslušný prohlížeč:
1. Textový editor pro text.
2. Grafický editor pro obrázek.
3. Příslušný přehrávač pro zvuk, video či animaci.
Tyto dodatečné informace o přenášených datech nesou hlavičky začínající řetězcem "Content-", které specifikuje norma MIME. MIME je standardem, který doplňuje normu RFC-822 a zajišťuje zpětnou kompatibilitu. MIME je navrženo tak, aby mohly být posílány stávajícím poštovním systémem zprávy obsahující diakritiku, obrázky, zvuk atd.
Tento
standard řeší dvě otázky:
· Jak
vytvořit ze zprávy obsahující např. binární data zprávu vyhovující normě
RFC-822 a tedy přepravitelnou používanými přenosovými protokoly.
· Jak rozlišit jednotlivé druhy zpráv, tj. zavádí klasifikaci přenášených informací. Klasifikace přenášených informací se ukázala velmi užitečnou i mimo e-mail. Moderní služby Internetu ji přebírají a používají ke stejnému účelu. MIME zavádí další hlavičkové řádky do poštovní zprávy, které specifikují typ posílaných dat a způsob jejich kódování.
12.1 Hlavičky MIME
MIME zavádí hlavičky:
o MIME-Version - přítomnost této hlavičky elektronické pošty indikuje, že je zpráva sestavena podle MIME, tj. dle RFC2045 až RFC2049.
o Content-Type - specifikuje typ a podtyp dat posílaných v těle zprávy (text, audio, video, virtuální realita).
o Content-Transfer-Encoding - specifikuje použité kódování, pomocí kterého je zpráva převedena do formátu vyhovujícího přenosovému mechanismu (do ASCII).
o Content-ID - identifikace zprávy použitelná v možném odkazu.
o Content-Description - textový popis obsahu.
o Content-řetězec - je rezervováno pro budoucí použití v MIME.
o Content-Disposition – je hlavička specifikovaná normou RFC-2183.
12.1.1 Hlavička Mime-Version
Tato hlavička je jediná hlavička MIME nezačínající řetězcem "Content-". Hlavička specifikuje verzi normy MIME. Důvodem zavedení této hlavičky je zajištění kompatibility. Tj. podle přítomnosti této hlavičky software klienta rozpozná, že jde o zprávu rozšířenou podle MIME, a dále rozezná verzi MIME, podle kterého byla zpráva rozšířena. Rozšíření MIME podle RFC2045 až RFC2049 je verze 1.0. V budoucnu však mohou přijít další verze MIME s jiným repertoárem hlaviček.
Protokol HTTP používá také hlavičky vycházející z filosofie MIME a mnohé rovněž začínají řetězcem „Content-“, ale jsou uzpůsobeny protokolu HTTP. Právě skutečnost, že záhlaví HTTP není zcela kompatibilní s MIME, je v protokolu HTTP signalizováno neexistencí hlavičky Mime-Version v záhlaví HTTP zprávy.
Zpráva
sestavená podle RFC2045 až RFC2049 musí tuto hlavičku vždy obsahovat. Tedy
konkrétní tvar hlavičky vypadá takto: Mime-Version: 1.0 Hlavička musí
být uvedena před ostatními hlavičkami MIME.
12.1.2 Hlavička Content-Type
Hlavička popisuje typ dat obsažených v těle zprávy tak, aby klient, který tuto zprávu obdrží, mohl zvolit vhodný způsob prezentace obsahu zprávy. Hlavička má tvar:
Content-Type: typ/podtyp; parametry
Hlavička
specifikuje charakter obsahu zprávy pomocí typu a podtypu a případně pomocí
doplňkových parametrů. Parametry mají tvar:atribut=hodnota; …Parametrů může být
i více – jsou pak odděleny středníkem a na jejich pořadí nezáleží. Typ
specifikuje, o jaký typ dat se jedná, zda je v těle zprávy obsažen text,
obrázek (image) nebo např. obecný binární soubor (octet stram). Podtyp
pak specifikuje konkrétní formát obrázku, textu apod. Např. hlavička Content-Type:
image/jpeg informuje příjemce o tom, že obsahem zprávy
je obrázek formátu JPEG. RFC2045 až RFC2049 definuje několik základních typů.
Způsob registrace dalších typů je popsán v RFC2048. Typy jsou dvojího druhu:
· Jednoduché typy popisující typ přenášených dat. Jedná se např. o typy:
o text
o application
o image
o audio
o video
o model
· Kompozitní typy specifikující, že zpráva se skládá z několika částí. Jedná se např. o typy:
o message
o multipart
o report
Lze použít i experimentální typy, ty je však potřeba odlišit od standardních typů prefixem x- před jménem typu. Např. pro zprávu VRML se kdysi používalo x-world/x-vrml. Dnes však VRML (po ukončení experimentů) používá model/vrml.
Jména
typů, podtypů a parametry jsou nezávislé na tom, zda je píšeme velkými nebo
malými písmeny.
12.1.3 Hlavička Content-Transfer-Encoding
Data, která chceme posílat elektronickou poštou, jsou často 8bitová nebo binární. Tato data není možné zpravidla poslat přímo. Proto je potřeba definovat mechanismus převodu – kódování, jakým se data převedou na data, která jsou v kódu US-ASCII, tj. jsou převedena do 7bitového tvaru. Použitý typ kódování je uveden právě v hlavičce Content-Transfer-Encoding.
Ona hlavička Content-Transfer-Encoding v podstatě nenese pouze informaci o tom, jakým algoritmem jsou přenášená data kódována, ale v případě, že kódována nejsou, tak nese informaci o datech jako takových: jsou-li sedmibitová, osmibitová či binární (7bit, 8bit či binary).
MIME
definuje dva algoritmy kódování dat: Quoted-Printable a Base64. Další algoritmy
mohou být registrovány rovněž podle RFC2048. Hlavička Content-Transfer-Encoding
tak nejčastější nese následující
způsoby kódování:
·
quoted-printable
·
base64
· 7bit – data nejsou kódována, jsou v krátkých řádcích, obsahují pouze znaky US-ASCII.
· 8bit – data nejsou kódována, řádky jsou krátké, ale mohou se vyskytnout i znaky, které nejsou US-ASCII.
· binary – data nejsou kódována, tok bitů není dělený na řádky. Celkový počet přenášených bitů musí být dělitelný osmi.
· x-rozšíření - experimentální kódování (určeno pro vývojáře).
Hodnoty
8bit, 7bit a binary nepředstavují žádné kódování. Tyto hodnoty jsou užitečné
jako indikace typu dat. Hlavička Content-Transfer-Encoding se vztahuje k celému
tělu zprávy. Pokud se hlavička objeví v konkrétní části zprávy, pak se vztahuje
pouze na tuto část. Problém, jak kódovat ne US-ASCII informace v hlavičce,
je popsán v kapitole „Znaky v hlavičce, které nejsou US-ASCII“.
Kódovací mechanismus kóduje všechna data do ASCII znaků. Výsledkem kódování je
tedy US-ASCII řetězec. Příklad
Content-Type:
text/plain; charset=ISO-8859-2
Content-Transfer-Encoding: base64 interpretujeme takto: tělo
zprávy je řetězec znaků US-ASCII vzniklých kódováním base64. Původní data byla
ve znakové sadě ISO-8859-2 a musí být do této sady opět převedena při
zobrazování příjemci.
12.1.4 Hlavička Content-ID
Hlavička nese jednoznačnou identifikaci obsahu zprávy. Hlavička je volitelná, její použití je ale v některých případech povinné – např. v implementacích používajících data typu message/external-body.
12.1.5 Hlavička Content-Description
Hlavička obsahuje popisné informace o přenášené zprávě, např. název obrázku, který je jako tělo posílán.
Příklad:
Content-Description: "Obrazek Prazskeho hradu". Popis musí být
v US-ASCII.
12.1.6 Hlavička Content-Disposition
Hlavička Content-Disposition určuje, zda-li jsou přenášená data určena k automatickému zobrazení příjemci (inline) či nejsou určena k automatickému zobrazení příjemci (attachment), tj. příjemce je má zpracovávat ručně (např. se jedná o soubor, který má být uložen na lokální disk). Dále hlavička může obsahovat další parametry:
· filename=jméno souboru
· creation-date=datum vytvoření
· modification-date=datum poslední modifikace
· read-date=datum posledního čtení
·
size=velikost
přenášeného souboru
Příklad
(zpráva nesoucí zvuk, který se má příjemci přehrát):
Message-ID: <335A2639.C79@pvt.cz>
Date: Sun, 20 Apr 1997 16:20:41 +0200
From: Libor Dostalek <dostalek@pvt.cz>
X-Mailer: Mozilla 3.01Gold (WinNT; I)
MIME-Version: 1.0
To: dostalek@pvt.net
Subject: (no subject)
Content-Type: audio/wav
Content-Transfer-Encoding: base64
Content-Disposition: inline; filename="ding.wav"
UklGRkYtAABXQVZFZm10IBAAAAABAAEAIlYAACJWAAABAAgAZGF0YSItAACAgICAgICAgICA
gICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICA
gICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIC
...
12.2 Standardní kódovací mechanismy
Kódovací mechanismus převádí osmibitová data na sedmibitová (tj. data obsahující pouze znaky US-ASCII).
MIME definuje dva kódovací mechanismy: Quoted-printable a Base64. Pro úplnost se zmíníme ještě o mechanismu Radix-64, který používá PGP.
12.2.1 Quoted-printable
Toto kódování je určeno pro data, která z větší části obsahují znaky US-ASCII. Výsledkem kódování je text, který je i bez dekódování z velké části pro člověka čitelný.
Pravidla
kódování
· Bajty s desítkovou hodnotou od 33 do 60 a od 62 do 126 včetně jsou nahrazeny znaky US-ASCII (od ! do < a od > do ~). Jinými slovy: znaky, které jsou US-ASCII, se nekódují, tj. ponechávají se beze změny. Rovněž konce řádků se ponechávají.
· Ostatní bajty se nahrazují znakem "=" následovaným šestnáctkovou hodnotou bajtu. Např. znak „á“ se nahradí „=E1“.
· Bajty s hodnotou 9 a 32 jsou nahrazeny znaky tabulátor a mezera. Nesmí být na konci řádku.
· Konec řádky je vyjádřen CRLF.
· Zakódovaná řádka musí mít maximálně 76 znaků. Pokud je řádka delší použije se měkký konec řádky, tj. vloží se znak „=“ a konec řádky.
Tento způsob kódování není příliš úsporný. V případě, že všechny přenášené znaky jsou ne US-ASCII, pak se přenášená data zvětší na trojnásobek.
Příklad:
Řetězec Václav Vopička bude kódován v quoted-printable jako V=E1clav Vopi=E8ka protože:
· á je šestnáctkově E1
· č je šestnáctkově E8
Tento způsob kódování by v případě, že by všechny znaky byly ne US-ASCII, prodloužil původní text na trojnásobek. Naopak kódování Base64 prodlouží text pouze právě o třetinu.
12.2.2 Base64
Kódování Base64 je určeno pro kódování obecných binárních data, která nemusí být čitelná pro člověka. Kódovaná data jsou pouze o třetinu delší než data původní.
Kódovací
algoritmus je jednoduchý. Používá tabulku base64 o 64 znacích (a znak
"="). Pro kódování 64 znaků je třeba 6 bitů (26=64). Znak
"=" (6510) se používá ke speciálnímu účelu pro označení
výplně na konci textu.Z hlediska kódování se na zprávu nehledí jako na proud
osmic bitů (bajtů), ale jako na proud šestic bitů. Každá šestice se pak kóduje
podle tabulky base64. Viz obr. 3-1.Na začátku kódování se kódovaný text rozdělí
na sekvence 24 bitů (trojice bajtů). Každá trojice bajtů se rozdělí na 4 šestice bitů. Každá šestice
reprezentuje jeden znak v abecedě base64. Kóduje se zleva doprava. Každých 6
bitů je nahrazeno odpovídajícím znakem z tabulky znaků abecedy base64. Tabulka
base64:
Hodnota Kódováno Hodnota Kódováno Hodnota Kódováno Hodnota Kódováno
0 A
17 R
34
i
51 z
1
B 18 S
35 j
52 0
2 C
19
T
36 k
53 1
3
D
20
U 37
l
54 2
4 E
21
V
38
m 55 3
5
F
22
W
39 n
56 4
6
G 23 X
40
o
57 5
7 H
24
Y
41 p 58 6
8
I
25
Z 42 q
59 7
9
J 26 a
43
r
60 8
10 K
27
b
44 s
61 9
11
L
28
c 45 t
62 +
12
M 29 d
46 u
63 /
13
N
30 e 47 v
14
O 31 f 48
w (výplň 002) =
15
P 32 g
49 x
16
Q 33 h 50 y
Výstupní - zakódovaný text musí být uspořádán do řádek maximálně dlouhých 76 znaků.

Obr. 3-1 Kódování Base64
Všechny
znaky pro konec řádky a jiné znaky, které nejsou obsaženy v tabulce base64,
musí být dekódovacím programem ignorovány, mohou indikovat chybu přenosu.
Zbude-li na konci textu po rozdělení méně než 24 bitů, doplní se nulové bity
zprava. Přidání na konec je indikováno znakem "=". Jenže jak je to
přesně s tím „=“. Problém je
v tom, že´délka textu, který se kóduje, nemusí být dělitelná třemi. Rozdělí-li se text vstupující do kódování na
skupiny po třech bajtech, pak poslední skupina:Má rovněž tři bajty. Nedochází k žádné komplikaci
a žádné znaky „=“ se na konec nepřidávají.
Má dva bajty (16 bitů), pak se prvních dvanáct bitů
kóduje normálně dle tabulky Base64. Zbylé 4 bity se doplní dvěma binárními
nulami na 6 bitů a výsledek se rovněž kóduje Base64. Avšak na konec se přidá
jeden znak „=“ signalizující doplnění výplní dlouhou dva bity.
Má jeden bajt (8 bitů), pak se prvních 6 bitů kóduje
normálně dle tabulky Base64. Zbylé dva bity se doplní čtyřmi binárními nulami a
výsledek se kóduje dle tabulky Base64. Na konec se přidají dva znaky „=“
signalizující výplň dlouhou 4 bity.
Nejlépe
se princip pochopí na příkladech:
Příklad:
délka vstupního textu je dělitelná třemi
|
Vstup 8-bit: |
01101101
01001000 01111011 11100011
10101010 11110001 |
|
Vstup 6-bit: |
011011 010100 100001 111011 111000 111010
101011 110001 |
|
Desítkově: |
27
20 33 59 56 58 43
49 |
|
Base64 (výstup): |
b
U h 7 4 6 r x |
Příklad:
poslední skupina má dva bajty
|
Vstup 8-bit: |
01101101
01001000 01111011 11100011
10101010 |
|
Výplň: |
00 |
|
Vstup 6-bit: |
011011 010100 100001 111011 111000 111010
101000 |
|
Desítkově: |
27
20 33 59 56 58 40
|
|
Base64 (výstup): |
b
U h 7 4 6 o
= |
Příklad:
poslední skupina má jeden bajt
|
Vstup 8-bit: |
01101101
01001000 01111011 11100011 |
|
Výplň: |
0000 |
|
Vstup 6-bit: |
011011 010100 100001 111011 111000
110000 |
|
Desítkově: |
27
20 33 59 56 48 |
|
Base64 (výstup): |
b
U h 7 4 w ==
|
12.2.3 Radix-64
Kódování Radix-64 je popsáno v RFC-2440, které specifikuje formát zprávy PGP. Jedná se o rozšíření kódování Base64 o kontrolní součet. Data jsou kódována Base64. Za Base64 kódovanými daty následuje nový řádek (CRLF), znak „=“ a 24 bitů dlouhý kontrolní součet z původních nekódovaných dat počítaný algoritmem CRC-24. Sám kontrolní součet je též kódován Base64. Zdrojový kód algoritmu CRC-24 je uveden v RFC-2440.
Příklad
(RFC-2440):
-----BEGIN PGP MESSAGE-----
Version: OpenPrivacy 0.99
yDgBO22WxBHv7O8X7O/jygAEzol56iUKiXmV+XmpCtmpqQUKiQrFqclFqUDBovzS
vBSFjNSiVHsuAA==
=njUN
-----END PGP MESSAGE-----
V případě, že Váš software nepodporuje kódování Radix-64, pak stačí vypustit poslední řádek a data dekódovat běžným software pro Base64 kódování.
12.3 Znaky v hlavičce, které nejsou ASCII
Znaky, které nejsou ASCII, by se v žádném případě neměly vyskytnout v záhlaví zprávy. Na otázku co se stane, když se tam takový znak vyskytne, není jednoznačná odpověď. Zpráva může dojít příjemci bez problému, zpráva může být nějakým serverem na cestě vrácena nebo se může ztratit.
RFC-2047
řeší otázku, jak do parametrů hlaviček dodat znaky, které nejsou ASCII. I zde
se problém skládá ze dvou částí:
- Co takový znak vyjadřuje? Např. hexadecimálně znak F8 může v jedné abecedě představovat ř a v jiné azbukové š.
- Jak je kódován do ASCII. Např. base64 nebo Quoted-printable.
Syntaxe parametru hlavičky obsahujícího znaky, které nejsou ASCII, je:
=?charset?kódování?řetězec?=
kódování je
buď b pro base64 nebo q pro quoted printable.
Příklad:
Chce-li si odesilatel do hlavičky From zadat své jméno s diakritikou, pak:
From:
=?iso8859-2?q?V=E1clav Vopi=E8ka?= <Vaclav.Vopicka@firma.cz>Je
zpráva od Václava Vopičky, který má poštovní adresu Vaclav.Vopicka@firma.cz,
ale nemá rád své jméno bez háčků a čárek, tak si jej dal alespoň do ignorované
časti hlavičky From:. Václav Vopička použil znakovou zadu iso8859-2.
12.4 Jednoduché typy dat v hlavičce Content-Type
Jednoduché typy v podstatě sdělují, jaký software má příjemcův poštovní klient použít pro zobrazení zprávy adresátovi. Zda-li zprávu má zobrazit textovým editorem, grafickým editorem, přehrávačem zvuku, videa či snad dokonce zobrazit jako virtuální realitu.
12.4.1 Text
Typ
text je určen pro textové zprávy.
Typ
text může mít mj. následující podtypy:
- plain - viz RFC-2646 a RFC-2046,
- richtext – viz RFC-2045 a RFC-2046,
- enriched - viz RFC-1896,
- html – viz RFC-2854,
- sgml - viz RFC-1874,
- c822-headers – viz RFC-1892,
- css - viz RFC-2318,
- xml – viz RFC-2376,
- directory – viz RFC-2425,
- calendar – viz RFC-2445.
- parityfec – viz RFC-3009.
Primární podtyp je plain, který označuje neformátovaný text. Podtypy se používají pro formátované texty. Příkladem je např. podtyp html, kdy text obsahuje příkazy jazyka HTML.
U
typu text je možné
použít parametr charset, který indikuje použitou znakovou sadu. Pro nás jsou
zajímavé zejména sady US-ASCII, ISO-8859-2 („ISO-LATIN2“), Windows-1250 a
případně IBM850.
Příklad:Content-Type:
text/plain; charset=us-ascii Tento typ je implicitní.
Tj. pokud ve zprávě MIME hlavička Content-Type uvedena není, pak se má za to,
že zpráva je typu text/plain a použitá znaková sada je US-ASCII. Příklad:
Content-Type:
text/html; charset=ISO-8859-2
12.4.2 Application
Tento typ je určen pro data, která je třeba zpracovat nějakou aplikací, aby byla čitelná pro uživatele. Jsou definovány podtypy: octet-stream a PostScript. Obecně podtyp bývá jménem aplikace, pro kterou jsou data určena. Uživatel musí být nějakým způsobem informován, jak dotyčná data zpracovat, např. průvodním dopisem. Pouze z hlavičky se o jejich bližším charakteru uživatel nemusí dozvědět všechny informace.
Podtypy:
- Octet-Stream -
indikuje, že tělo obsahuje binární data. Lze uvést parametry:
Type - druh binárních dat (pro informaci uživatele)
Doporučená
akce při obdržení takovéto zprávy je uložit data do souboru bez dekódování a
použít aplikaci.
- PostScript - indikuje, že v těle zprávy je postscriptový dokument.
- Další podtypy jsou mj.:
- sgml – viz RFC-1874
- pgp-sinature, pgp-encrypted a pgp-keys – viz RFC-2015
- pkcs7-mime, pkcs7-signature a pkcs-10 – viz RFC-2311
- xml - viz RFC-2376
- http – viz RFC-2616
- parityfec – viz RFC-3009
- msword – text ve formátu MS Word.
Příkald:
Content-Type: application/msword
Content-Disposition: attachment; filename="soubor.doc"
12.4.3 Image
Typ image specifikuje obrázek, tj. obsahem těla zprávy je obrázek. K jeho prezentaci je třeba odpovídající prohlížeč. Podtypy jsou mj.:
- jpeg – viz RFC-2045 a RFC-2046,
- gif – RFC-2045 a RFC2046,
- tiff – viz RFC2302.
Příklad:
Content-Type:
image/jpeg
Content-Disposition: inline; filename="soubor.jpg"
12.4.4 Audio
Typ audio specifikuje zvuk. K prezentaci je třeba odpovídající
přehrávač. Podtypy jsou mj.:
- basic - mono se
vzorkovacím kmitočtem 8 kHz (implicitní podtyp),
- 32kadpcm - viz RFC-2421 a
RFC2422,
- L16 – viz RFC-2586,
- telephone-event - viz
RFC-2833,
- tone - viz RFC-2833,
- mpeg - viz RFC-3003,
- parityfec – RFC-3009,
- MP4A-LATM – viz RFC-3016.
Příklad:
Content-Type:
audio/wav
12.4.5
Video
Obsahem těla zprávy je video, implicitní podtyp je mpeg.
Příklad:
Content-Type:
video/mpeg
12.4.6 Model
Typ model je určen pro vícedimenzionální struktury (např. pro virtuální realitu). Typem model se zabývá RFC-2077.
12.5 Kompozitní typy v Content-Type
Doposud jsme se zabývali pouze jednoduchými zprávami, tj. zprávami, které se skládaly z jedné části (viz obr. 12-1).
Obr. 12-1 Struktura standardní zprávy dle RFC-822
Nyní
se budeme zabývat zprávami složenými z více jednotlivých zpráv. Každá
jednotlivá zpráva se může opět skládat z dílčích zpráv nebo již může být
jednoduchou zprávou.Zpráva může ve svém těle nést:
- Několik dílčích zpráv, pak je použito hlavičky (Content-Type: multipart).
- Dlouhá zpráva může být transportována jako několik kratších (Content-Type: message).
- Jiným případem je situace, že poštovní server z nějaké příčiny nemůže poštovní zprávu předat dále směrem k adresátovi pro chybu v doručování zprávy. V takovém případě poštovní servery často tuto skutečnost signalizují adresátovi poštovní zprávou, která se skládá ze dvou částí: z části specifikující chybu a části obsahující původní zprávu (nebo alespoň počátek původní zprávy).
12.5.1 Multipart
Tělo zprávy tohoto typu obsahuje několik různých částí - několik dílčích zpráv. Každá část těla celkové zprávy začíná úvodním oddělovačem, pak následují hlavičky této části, prázdný řádek a vlastní tělo dílčí zprávy. Poslední část je ukončena koncovým oddělovačem.
Jednotlivé
dílčí zprávy nejsou interpretovány podle RFC-822. Mohou, ale také nemusí
obsahovat hlavičky (prázdný řádek za záhlavím však musí být vždy uveden). Pokud
nejsou hlavičky u části uvedeny, uplatní se implicitní hlavičky ze záhlaví celé
zprávy. Oddělovač je speciální sekvence znaků, která se nesmí vyskytnout
nikde uvnitř částí. Oddělovač se definuje v záhlaví celé zprávy v hlavičce
Content-Type parametrem boundary.
Parametr
má tvar boundary=řetězec.
Oddělovač je pak řádka, která začíná dvěma pomlčkami "- -", pak
následuje řetězec z parametru. Maximální délka oddělovače je 70 znaků.
|
|
From: Libor Dostalek <dostalek@pvt.cz> |

Obr. 12-2 Zpráva typu multipart/mixed
Příklad:
Content-Type:
multipart/mixed; boundary="gc0p4J:2408t" Tato
hlavička vyjadřuje, že je tělo zprávy složeno z několika částí, přičemž hlavičky jednotlivých částí nemusí
být uvedeny. Každá část začíná řádkou:
- - gc0p4J:2408t
Koncový oddělovač určuje, že již nenásleduje žádná část, a má tvar:
- - gc0p4J:2408t - -
tj. je na konci doplněný ještě dvěma pomlčkami. Podtypy: Multipart/Mixed
- je primárním podtypem. Je určen pro zprávy, které obsahují nezávislé části,
které je potřeba svázat v daném konkrétním pořadí. Klasickým případem podtypu
multipart/mixed je zpráva elektronické
pošty obsahující jeden nebo více příloh.
- Multipart/Alternative
Zpráva tohoto typu obsahuje několik částí, přitom všechny části obsahují
shodné informace, pouze tvar je odlišný. Např. táž zpráva jednou napsaná v
US-ASCII, potom v ISO-8859-2 a nakonec třeba namluvena, tj. audio.
Nejlepší prezentace informací je uváděna jako poslední část. Příjemcův
software musí rozpoznat, které formy je schopen zobrazit, a vybrat z nich
tu nejlepší.
Příklad:
From: andel@pvt.cz
To:
cert@peklo.org
Subject: Pozvani
MIME-Version:
1.0
Content-Type:
multipart/alternative; boundary=boundary42
Pro pripad, ze
Tvuj prohlizec neumi MIME,
tak Te proste
zvu na vylet.
--boundary42
Content-Type:
text/plain; charset=us-ascii
Zvu te i bez
hacku a carek
--boundary42
Content-Type:
text/html; charset=us/ascii
Pridej se
<H1>k nam</H1>
--boundary42
Content-Type:
audio/basic
Content-Transfer-Encoding: base64
UklGRkYtAABXQVZFZm10IBAAAAABAAEAIlYAACJWAAABAAgAZGF0YSItAACAgICAgICAgICA
gICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICA
gICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICA
...
--boundary42--
Software vytvářející zprávu tohoto typu musí řadit části ve vzrůstající kvalitě.
- Multipart/Report. S tímto
podtypem jsme se setkali ve 2. kapitole v části o potvrzování
doručovaných poštovních zpráv.
- Multipart/Parallel.
Klientem mají být všechny části prezentovány uživateli současně. Např.
zvuk na pozadí obrázku.
Následující příklad zprávy se skládá ze tří částí. Třetí část se skládá ze dvou částí, které mají být prezentovány současně.
MIME-Version:
1.0
From:
To:
Date:
Subject:
Priklad
Content-Type:
multipart/mixed; boundary=unique-boundary-1 Zde
je misto pro text, kterym je mozne objasnit smysl zpravy pro ty,
kteri
nejsou schopni zpravu podle MIME interpretovat. Treti
dilci zprava obsahuje obrazek, na jehoz pozadi se ma spustit hudba. --unique-boundary-1 První
dílčí zpráva
--unique-boundary-1
Content-type:
text/plain; charset=US-ASCII Druha dilci zprava --unique-boundary-1
Content-Type:
multipart/parallel; boundary=unique-boundary-2 --unique-boundary-2
Content-Type:
audio/basic
Content-Transfer-Encoding:
base64 ...
base64-kódované mono se vzorkovacím kmitočtem 8 KHz
--unique-boundary-2
Content-Type:
image/jpeg
Content-Transfer-Encoding:
base64 ...
base64-kódovaný obrázek formátu JPEG
--unique-boundary-2--
--unique-boundary-1—
- Multipart/Signed a Multipart/Encrypted
jsou subtypy definované v RFC1847.
Subtyp Multipart/Signed je určen pro elektronicky podepsanou zprávu; specifikuje zprávu skládající se ze dvou částí: - Zprávy
- Elektronického podpisu této zprávy
Subtyp Multipart/Encrypted specifikuje zprávu v elektronické obálce (šifrovanou zprávu). Skládá se opět ze dvou částí:
- Z informací o použitém způsobu šifrování (např. verzi šifrovacího software).
- Z šifrované zprávy.
Není
definován subtyp pro zprávy elektronicky podepsané a zároveň šifrované. Na
takovýto požadavek je nutné zprávu nejprve elektronicky podepsat a výsledek pak
celý šifrovat.
Příkladem
může být PGP. Pokud nepoužijete MIME,
pak se veškeré informace ukládá do
datové části zprávy. Např.:
Subject: Tajna zprava
Date: Sat,
19 Apr 1997 17:16:27 +0200
From:
Libor Dostalek <dostalek@pvt.cz>
To:
alena@pvt.net
-----BEGIN
PGP MESSAGE-----
Version:
2.6.3i
Takovou
zprávu musíme nejprve uložit do souboru a pak na tento soubor spustit program
PGP. Zejména příjemce musí rozpoznat, že jde o zprávu, kterou má zpracovat
programem PGP.RFC2015 zavádí typy:
· application/pgp-encrypted
· application/pgp-signature
· application/pgp-keys
Takže náš příklad může vypadat např. následovně:
Subject: Tajna zprava
Date: Sat,
19 Apr 1997 17:16:27 +0200
From:
Libor Dostalek <dostalek@pvt.cz>
To:
alena@pvt.net
Mime-Version:
1.0
Content-Type:
multipart/encrypted; boundery=hranice;
protocol=application/pgp-encrypted
--hranice
Contentn-Type:
application/pgp-encrypted Version: 1. --hranice
Content-Type:
application/octet-stream -----BEGIN PGP MESSAGE-----
Version:
2.6.3i hEwDVzIQ/0AACWUBAgCjg7Plko8fm4nrCZOn7LQprCvcMelrF7qr2N5S5adUHujQ
hiUmcIMDK8zx+Cvm52lD68NZxKybexuaAESa+fMgpgAAALFXB4DlbeEWRHe6GwDz
vYMsWPbK7+UFC9ZXeHsKc+c6iPokzMG/NWHf76/OLJXV3iKIKrfRFycA77Pu1G/X
IccoMlAIfC29cqT7Y//q5TvYAwDoqpfIjoVaqz8dIjqy2G/2rf+acb4nyitLEtwL
NE0huVXKsgenm39MqQp9A5W+dWzC8OcB2uHTzdzpQgNzJJ5JYf1/L75XZ0la3jyA
t7HvXV6IPqQPIw0s0uChsEaKDPI=
-----END
PGP MESSAGE-----
--hranice--
Za
povšimnutí stojí, že první část nenese žádné kryptografické údaje - vše je v
druhé části. První část nese pouze informaci o verzi PGP/MIME, tj. je umělá,
aby syntaxe vyhovovala MIME.
12.5.2 Message
Tento typ umožňuje odeslat poštovní zprávu jako tělo jiné poštovní zprávy (message/rfc822), dlouhou zprávu odeslat jako několik kratších (message/partial) nebo namísto těla zprávy odeslat jen informace, že se zpráva nachází na nějakém serveru (message/external-body).
Podtypy
jsou mj.:
- Message/rfc822 specifikuje, že tělo obsahuje vnořenou zprávu, která má syntaxi podle RFC-822. Na rozdíl od zprávy definované v RFC-822 není nutné, aby každé tělo zprávy typu message/rfc822 obsahovalo hlavičky From, Subject a To. Vnořená zpráva může být i MIME zpráva.
- Message/Partial
je definován proto, aby bylo možné posílat dlouhé zprávy jako několik
kratších a příjemcův software je mohl automaticky zobrazit jako jednu
(sloučenou) zprávu.
RFC
2046 uvádí následující příklad. Příjemce obdržel 2 maily:
|
From: Bill@host.com Message-ID: <anotherid@foo.com> |
|
From: Bill@host.com ... druha cast audiomailu ... |
Příjemcův software zjistil, že se jedná o dvě části téže zprávy o identifikaci (id) ABC@host.com. Jednotlivé části jsou číslovány pomocí parametru number. Celkový počet částí (total) je 2. Takže příjemcův software má k dispozici celou zprávu a může ji zobrazit jako:
|
From: Bill@host.com ... prvni cast audiomailu ... |
Jelikož se jedná o Content-Type: audio/basic, tak zpráva není zobrazena jako
textový soubor, ale přehrána jako audio.
- Message/External-Body specifikuje pouze informace o zprávě, která je uložena mimo vlastní zprávu. Místo, kde jsou data zprávy uložena, je specifikováno pomocí parametrů:
- Parametr acces-type specifikuje, o jaký server (protokol) se jedná. Nejčastější typy serverů jsou ftp, anon-ftp (anonymní FTP-server), mail-server (list server) a local-file (soubor na lokálním počítači).
- name - jméno souboru
- site - jméno počítače (serveru se souborem)
- directory - adresář, ve kterém soubor leží
- expiration - čas, do kdy tam soubor bude (do kdy bude aktuální).
Příklad (RFC 2046):
From:
To:
Date:
Subject:
MIME-Version: 1.0
Message-ID:
<id1@host.com>
Content-Type:
multipart/alternative; boundary=42
Content-ID:
<id001@guppylake.bellcore.com> --42
Content-Type:
message/external-body; name="BodyFormats.ps";
site="thumper.bellcore.com"; mode="image";
access-type=ANON-FTP; directory="pub"; expiration="Fri, 14 Jun
1991 19:13:14 -0400 (EDT)" Content-type:
application/postscript
Content-ID:
<id42@guppylake.bellcore.com> --42
Content-Type:
message/external-body; access-type=local-file; name="/u/nsb/writing/rfcs/RFC-MIME.ps";
site="thumper.bellcore.com"; expiration="Fri, 14 Jun 1991
19:13:14 -0400 (EDT)" Content-type:
application/postscript
Content-ID:
<id42@guppylake.bellcore.com> --42
Content-Type:
message/external-body; access-type=mail-server server="listserv@bogus.bitnet";
expiration="Fri, 14 Jun 1991 19:13:14 -0400 (EDT)" Content-type:
application/postscript
Content-ID:
<id42@guppylake.bellcore.com> --42-- V
tomto příkladu odesilatel posílá tři odkazy na stejná data. První kopie dat je
na anonymním FTP-serveru, druhá na lokálním disku a třetí lze získat z archivu
list serveru. Zatímco identifikace celé zprávy je nepovinná (<id1@host.com>), tak
identifikace obsahu dílčí zprávy je povinná (<id42@guppylake.bellcore.com>). Důležité
je si také uvědomit, že obsahem těla dílčí zprávy nejsou data, ale informace o
této zprávě. Hlavičku Content-Type tak máme použitu celkem ve třech různých
významech:
1.
Content-Type:
multipart/alternative; boundary=42
Specifikuje typ zprávy jako celku.
2.
Content-Type:
message/external-body;
Specifikuje, typ dílčí zprávy - jedná se o odkaz.
3.
Content-Type:
application/postscript
Toto v podstatě není hlavička, ale obsah zprávy, kterým se specifikuje typ dat,
na které je odkazováno.
![]()
13 Bezpečná pošta: S/MIME
V Internetu byla publikována celá řada protokolů specifikujících bezpečnou poštu. Zejména se jednalo o protokoly PEM a MOSS, které se však v praxi neujaly (jejich popis je na přiloženém CD). Prosadil se protokol PGP, avšak z dnešního pohledu se jeví jasným favoritem protokol S/MIME.
Normy RFC-2632 až RFC-2634 jsou již třetí verzí protokolu S/MIME (Secure/Multipurpose Internet Mail Extension). Zatímco druhá verze protokolu S/MIME byla orientována na algoritmy RSA a MD-5 a zprávy dle PKCS#7, tak třetí verze tyto algoritmy a formát PKCS#7 podporuje jen pro zachování zpětné komptability a orientuje se na protokol CMS.
Základními kryptografickými protokoly jsou:
- SHA-1 pro výpočet kontrolního součtu.
- DSS pro elektronický podpis.
- Diffie-Hellmanův algoritmus pro šifrování symetrických klíčů.
S/MIME je koncertem několika protokolů. Jádrem je zpráva CMS, která je zabalená v MIME zprávě. Navíc je třeba s certifikáty a CRL pracovat s ohledem na to, že zprávy mohou být zpracovávány bez přístupu na Internet (OffLine). Před tím, než sestavíme S/MIME zprávu, podíváme se na jednotlivé protokoly, které se této hry účastní.
13.1 Zpráva CMS používaná v S/MIME
S/MIME používá formát zprávy
CMS. Přitom podporuje pouze následující typy CMS zpráv: Data, SignedData a EnvelopedData,
tj. nepodporuje např. autentizovaná data popisovaná též v normě CMS.
V případě elektronicky podepisovaných zpráv musí být struktura signerInfo
verze 1. Prakticky to znamená, že v případě elektronického podpisu jsou
podporovány pouze zprávy zcela kompatibilní s normou PKCS#7 (což se ovšem netýká zpráv
v elektronické obálce).
S/MIME doporučuje používat následující tři atributy CMS zpráv (viz kap.
8.9.3). Jedná se o podepisované atributy elektronického podpisu, tj. stuktury signerInfo.
- signingTime
- sMIMECapabilities
- sMIMEEncryptionKeyPreference
Podepisované atributy sMIMECapabilities a sMIMEEncryptionKeyPreference
zavádí přímo norma S/MIME.
První atribut signingTime obsahuje datum a čas podpisu
zprávy. Jeho syntaxi jsme popsali v kap. 8.9.3. Zbývající dva atributy
zavádí přímo norma S/MIME.
Atributem sMIMECapabilities
informuje odesilatel příjemce o kryptografických a jiných algoritmech, které
podporuje (jaké algoritmy má použít ve své případné odpovědi).
Poslední atribut sMIMEEncryptionKeyPreference je důležitý v případě, že odesilatel
používá jiný certifikát pro podepisování a jiný pro šifrování. Častou praxí
totiž je, že odesilatel elektronicky podepíše zprávu a jako součást elektronicky
podepsané zprávy (CMS zprávy) přibalí svůj certifikát. Příjemce pak využije
tento certifikát pro šifrování odpovědi. Potíž je ovšem nastane, nelze-li tento
certifikát použít k šifrování. To je i případ kvalifikovaných certifikátů,
které mají doporučeno, aby v rozšíření „použití klíče“ měly nastaveno, že
se nesmí používat k ničemu jiném než pouze k elektronickému
podepisování. Obdobným případem je, že uživatel používá např. certifikáty
s algoritmem DSS k elektronickému podpisu a Diffie-Hellmanovy certifikáty
pro šifrování.
·
Řešením je, že
se šifrovací certifikát také přibalí do CMS zprávy a jeho identifikace se uvede
v atributu sMIMEEncryptionKeyPreference.
13.2 Certifikáty a CRL
Adresa elektronické pošty podle RFC-822 musí být uvedena
v certifikátu, kterým je dokument podepsán. Jak software odesilatele, tak
software příjemce musí zkontrolovat shodu této adresy uvedené
v certifikátu s adresou v hlavičce „From:“ nebo „Sender:“
elektronické pošty. Tady je prostor pro různé žertíky, protože adresa
v hlavičce „From“ (resp. „Sender“) může obsahovat libovolný řetězec, pokud
je v tomto řetězci uvedena adresa ve špičatých závorkách. MS Outlook však
uživateli zobrazuje právě ten libovolný řetězec (nikoliv korektní adresu ve
špičatých závorkách).
V certifikátu může být uvedena adresa elektronické pošty buď
v předmětu certifikátu (jedinečné jméno „Common Name“) nebo
v rozšíření SubjectAltName.
Obě možnosti jsou podporovány, preferována je však adresa
v rozšíření SubjectAltName. Pokud uživatel totiž používá více poštovních
adres, pak je všechny může do tohoto rozšíření uvést (rozšíření se uvede
vícenásobně).
Jinou otázkou jsou rozšíření certifikátu. S/MIME vyžaduje, aby software
podporoval rozšíření: Basic
Constraints, Key Usage, authorityKeyID, subjectKeyID a subjectAltNames. Ostatní rozšíření podporovat pouze může, tj. ostatní rozšíření nemohou být označena jako kritická, aby bylo zajištěno, že příslušný software pro S/MIME je bude podporovat a neodmítne celý certifikát.
CRL může být součástí zprávy CMS, tj. tím pádem i zprávy S/MIME. Je
pochopitelně pravda, že nejefektivnější je používat On Line zjištění, jak na
tom certifikát je,. např. za využití rozšíření URI Distribution Points
či protokolu OCSP. Avšak mnohdy uživatelé pracují tak, že se připojí
k Internetu, stáhnou si poštu, odpojí se od Internetu a teprve pak si
poštu čtou. V takovém případě On Line komunikace s CA je nemožná a je
dobré vzít za vděk i CRL ze zprávy. Software klienta by měl umožnit i tato CRL
uložit v úložišti CRL počítače pro případné další použití.
13.3 MIME: Multipart/Signed a Multipart/Encrypted
V kapitole 3 jsme popisovali kompozitní typy. Průlom přinesla norma RFC1847, která zavádí kompozitní typy multipart/signed (pro elektronicky podepsané zprávy) a multipart/encrypted (pro zprávy v elektronické obálce), tj. rozšiřuje MIME o hlavičky vhodné pro elektronický podpis a šifrování zprávy. S/MIME pro některé elektronické podpisy používá kompozitní typ multipart/signed, druhý kompozitní typ mulitipart/encrypted S/MIME nepoužívá.
Norma RFC1847 je obecnou normou, tj. specifikuje pouze obecný tvar zprávy, která je elektronicky podepsána nebo šifrována. Kryptografické protokoly jsou tu obecně vyjádřeny pouze řetězcem protocol=typ/subtyp. Algoritmus výpočtu kontrolního součtu pro elektronický podpis se obecně vyjadřuje parametrem micalg=algoritmus.
Následující normy pak rozpracovávají jednotlivé tvary „bezpečných zpráv“, tj. určují konkrétní hodnoty dosazené za typ/subtyp. Např. dnes již téměř zapomenutá norma MOSS používá řetězce application/moss-signature a application/moss-encrypted všude tam, kde je v RFC1847 uveden řetězec typ/subtyp.
Jednotlivé
části se pak skládají ze záhlaví odděleného prázdným řádkem od textu části
zprávy. Záhlaví je tvořeno jednotlivými hlavičkami.
Obrázek 13-1 schématicky znázorňuje tvar elektronicky podepsané zprávy.
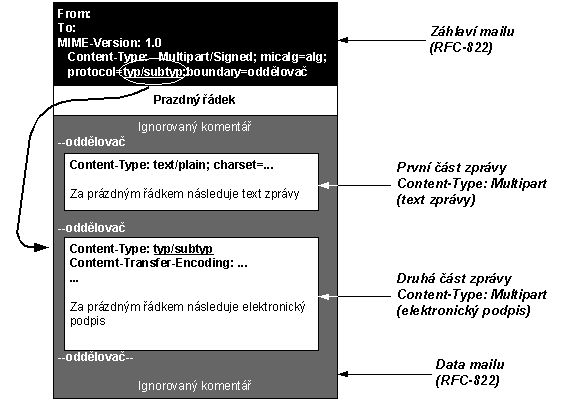
Obr. 13-1 Struktura elektronicky podepsané zprávy elektronické pošty
Zajímavé
je si uvědomit, že hlavička Content-Type se může vyskytnout až třikrát:
- V záhlaví celé zprávy elektronické pošty, tj. v záhlaví SMTP zprávy RFC822 (rozšířené podle MIME). Zde se používá typ Multipart specifikující, že zpráva je složena z více částí. Jako subtyp se zadává informace, zda-li se jedná o zprávu elektronicky podepsanou (Multipart/Signetd) případně šifrovanou (Multipart/Encrypted). V případě elektronického podpisu se parametrem micalg specifikuje algoritmus pro výpočet kontrolního součtu.
- V záhlaví první části zprávy, tj. části nesoucí text zprávy. Zde specifikuje např. typ znakové sady a další parametry (např. text/html).
- V záhlaví části nesoucí elektronický podpis. Zde specifikuje, že se jedná právě o část nesoucí elektronický podpis.
Jako příklad si zopakujeme příklad elektronicky podepsané zprávy z kap. 8.9.4, který je příkladem S/MIME zprávy. V tomto případě je protocol="application/x-pkcs7-signature" a micalg=SHA1:
…
Subject: Banka
Date: Wed, 7 Mar 2001.11:32:58 +0100
MIME-Version:.1.0
000c01c0a6f1$fb6c6cd0$c8252fc3@libor
Content-Type: multipart/signed;
protocol="application/x-pkcs7-signature";
micalg=SHA1;
boundary="----=_NextPart_000_0027_01C0A6FA.5C17C3B0"
X-Priority: (Normal)
X-MSMail-Priority: Normal
X-Mailer: Microsoft Outlook CWS, Build
9.0.2416 (9.0.2911.0)
X-MimeOLE: Produced By Microsoft MimeOLE
V5.00.2919.6700
Importance: Normal
Toto
je zpráva ve formátu MIME obsahující více částí
------=_NextPart_000_0027_01C0A6FA.5C17C3B0
Content-Type: text/plain;
charset="iso-8859-2"
Content-Transfer-Encoding: 7bit
Banka
na namesti v 11:00
Sef
------=_NextPart_000_0027_01C0A6FA.5C17C3B0
Content-Type: application/x-pkcs7-signature
*);
name="smime.p7s"
Content-Transfer-Encoding: base64
Content-Disposition: attachment;
filename="smime.p7s"
MIAGCSqGSIb3DQEHAqCAMIACAQExCzAJBgUrDgMCGgUAMIAGCSqGSIb3DQEHAQAAMYICOjCCAjYC
AQEwZDBdMQswCQYDVQQGEwJDWjERMA8GA1UEChMIUFZUIGEucy4xETAPBgNVBAsTCDIwMDAwOTAx
MSgwJgYDVQQDEx9DZXJ0aWZpa2FjbmkgYXV0b3JpdGEgSS5DQSAwMDA5AgMB4BIwCQYFKw4DAhoF
AKCCASwwGAYJKoZIhvcNAQkDMQsGCSqGSIb3DQEHATAcBgkqhkiG9w0BCQUxDxcNMDEwMzA3MTAz
MjU4WjAjBgkqhkiG9w0BCQQxFgQUiTyLOzG09qg6S71Ob5OHiiSyYUgwWAYJKoZIhvcNAQkPMUsw
STAKBggqhkiG9w0DBzAOBggqhkiG9w0DAgICAIAwBwYFKw4DAgcwDQYIKoZIhvcNAwICASgwBwYF
Kw4DAhowCgYIKoZIhvcNAgUwcwYJKwYBBAGCNxAEMWYwZDBdMQswCQYDVQQGEwJDWjERMA8GA1UE
ChMIUFZUIGEucy4xETAPBgNVBAsTCDIwMDAwOTAxMSgwJgYDVQQDEx9DZXJ0aWZpa2FjbmkgYXV0
b3JpdGEgSS5DQSAwMDA5AgMB4BIwDQYJKoZIhvcNAQEBBQAEgYBjQe3gKqprZNG20K3O9bBEPWPx
MiHfiupGBw799nMPFuJThITq8aR/JnPusFw9HJMFF+TrAxxk4f9jlYFaVDm9HdrdjODAGh1tP91x
jZ+1By37iibmNV2C23Px1Vq+aoZON0ZDEIqjqnm0D2ruqqrdCa9rpx/j8Pb4nayRi0d2HQAAAAAA
AA==
------=_NextPart_000_0027_01C0A6FA.5C17C3B0--
Dále
norma RFC1847 specifikuje i zprávu typu Multipart/Encrypted, kterou protokol
S/MIME nevyužívá. Její tvar je analogický tvaru zprávy elektronicky podepsané.
Opět se zpráva skládá ze dvou částí:
- Z informacích o šifrování, tj. informaci o použitých šifrovacích klíčích.
- Z vlastního šifrovaného textu.
Schématicky je tvar takovéto zprávy znázorněn na následujícím obrázku:
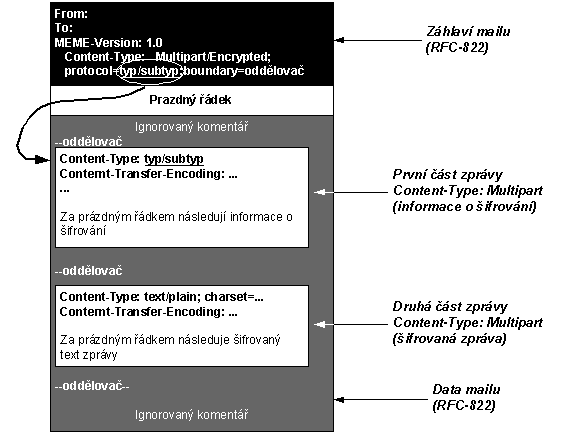
Obr. 13-2 Struktura šifrované zprávy elektronické pošty typu Multipart/Encrypted. S/MIME ji nepoužívá! – S/MIME pro šifrované zprávy používá jednoduchý typ:
„Content-Type: application/x-pkcs7-mime“
13.4 S/MIME
Mechanismus
vytvoření zprávy protokolu S/MIME je znázorněn na obr. 13-3. Zpráva je nejprve
zabezpečena protokolem CMS, pak kódována Base64 do sedmibitového tvaru a
nakonec obalena hlavičkami MIME a SMTP a odeslána elektronickou poštou.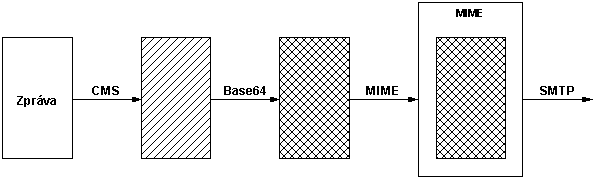
Obr. 13-3 Mechanismus vytvoření zprávy S/MIME
S/MIME
zprávy buďto podepisuje nebo vkládá do elektronické obálky (šifruje). Pokud
chceme provést obě operace, tj. zprávu jak podepsat, tak i šifrovat, tak se
např. elektronicky podepsaná zpráva vkládá do elektronické obálky či naopak.
Tj. vytvoří se elektronicky podepsaná S/MIME zpráva, která se jako data vloží
do elektronické obálky – též S/MIME zprávy. Teoreticky norma připouští i
opačnou možnost, tj. zprávu v elektronické obálce následně podepsat, ale
tato varianta se nedoporučuje. Vždy je totiž lepší podepisovat data
v původní podobě, a pak je případně zašifrovat, než podepisovat už
zašifrovaná data. Vztah mezi podpisem a interpretací dat pak nemusí být zcela
doložitelný (např. u soudu).Vnoření jedné S/MIME zprávy do druhé je
teoreticky možné opakovat i vícekrát. V kapitole o rozšířeném S/MIME
uvidíme, že elektronicky podepsaná S/MIME zpráva se vkládá do elektronické
obálky a výsledek se ještě elektronicky podepisuje, tj. proces vytváření S/MIME
zprávy se provede třikrát.Asi čekáte, že začneme popisovat zprávy Multipart/signed,
ale to je omyl. S/MIME používá kompozitní zprávy skládající se ze dvou částí
jen v dále zmíněném případě. S/MIME používá zejména jednoduché zprávy
využívající typ:
Content-Type: application/pkcs7-mime
A to jak pro
elektronicky podepisované zprávy, tak i pro zprávy šifrované. Klasický případ
S/MIME zprávy proto je:
From:
To:
MIME-Version: 1.0
Content-Type:
application/pkcs7-mime
Content-Transfer-Encoding:
base64
4VQpfyF467GhIGfHfYT6jH77n8HHGghyHhHUujhJh756tbB9HGTrfvbnj
n8HHGTrfvhJhjH776tbB9HG4VQbnj7567GhIGfHfYT6ghyHhHUujpfyF4
7GhIGfHfYT64VQbnj756
. . .
Typ
application/pkcs7-mime může mít
několik volitelných parametrů:Parametrem
name můžeme specifikovat jméno souboru (stejný význam má i parametr filename
v případné hlavičce Content-Disposition). Jméno souboru může mít nejvýše 8 znaků a 3 znaky rozšíření. Jako
jméno souboru se téměř vždy používá „smime“ a rozšíření může být:
.p7m
pro MIME typ „Application/pkcs7-mime“ v případě elektronicky podepsané
zprávy nebo zprávy v elektronické obálce..p7c pro MIME typ
„Application/pkcs7-mime“ v případě, že zpráva obsahuje pouze degenerovanou
CMS zprávu obsahující pouze certifikáty..p7s pro MIME typ „Application/pkcs7-signature“, tj. pro
kompozitní zprávu.Parametr smime-type obsahuje informaci o obsahu
zprávy. Tj. specifikuje, zda-li se jedná o podepsanou či šifrovanou zprávu.
Ano, tato informace se dá poznat z vnitřku zprávy, ale tato hlavička může
usnadnit práci poštovního klienta při zobrazování různých ikonek se symboly
elektronického podpisu či šifrování na Vašem PC, aniž by docházelo ke
komplikovanému rozboru zprávy. Parametr smime-type nabývá hodnot:enveloped-data
pro zprávu v elektronické obálce.signed-data pro elektronicky
podepsaná data.certs-only pro degenerovanou zprávu obsahující pouze
certifikáty.
Příklad (z RFC-2633):
Content-Type: application/pkcs7-mime;
smime-type=enveloped-data;
name=smime.p7m
Content-Transfer-Encoding: base64
Content-Disposition: attachment; filename=smime.p7m
rfvbnj756tbBghyHhHUujhJhjH77n8HHGT9HG4VQpfyF467GhIGfHfYT6
7n8HHGghyHhHUujhJh4VQpfyF467GhIGfHfYGTrfvbnjT6jH7756tbB9H
f8HHGTrfvhJhjH776tbB9HG4VQbnj7567GhIGfHfYT6ghyHhHUujpfyF4
0GhIGfHfQbnj756YT64V
No
a nyní jsme u problému elektronicky podepsané zprávy. Zpráva vytvořená podle
CMS je na první pohled velice těžko čitelná - je to BER kódovaný řetězec. To
nevadí v případě, že zpráva bude přijata a interpretována programem, který ji
dešifruje, verifikuje a výsledek zobrazí uživateli v čitelném tvaru. Ale mnohdy
je třeba zprávy pouze elektronicky podepisovat a rozesílat nejrůznějším
adresátům, přitom jen někteří budou používat pro čtení programy podporující
S/MIME.
Mnohým adresátům by stačilo si zprávu přečíst bez verifikace elektronického podpisu. Avšak formát application/pkcs7-mime je běžnými klienty nečitelný (zobrazí jej ve tvaru „rozsypaný čaj“ s textem někde uprostřed). Proto kromě formátu application/pkcs7-mime nabízí S/MIME pro elektronický podpis druhou možnost, kdy zpráva je rozdělena pomocí multipart/signed na dvě části: na čitelný text a samostatný „nečitelný“ elektronický podpis podle normy CMS. Jelikož elektronický podpis neobsahuje podepisovaná data (položka eContent v CMS zprávě je prázdná), tak se tento elektronický podpis nazývá externím elektronickým podpisem.
S externě
podepsanou elektronickou zprávou jsme se setkali v kap. 2.3, přesto si
její tvar alespoň schématicky zopakujme:
From:
To:
MIME-Version: 1.0
Content-Type:
multipart/signed; protocol=application/pkcs7-signature;
micalg=rsa-md5; boundary=hranice
--hranice
Content-Type:
text/plain
Content-transfer-Encoding:
Text
v čitelné podobě.
V případě, že text zprávy není v ASCII, pak je ještě před podepisováním
kódován Base64 nebo quoted-printable (tato informace se pochopitelně doplní do
hlavičky Content-Transfer-Encoding).
--hranice
Content-Type:
application/pkcs7-signature
Content-Transfer-Encoding:
base64
ghyHhHUujhJhjH77n8HHGTrfvbnj756tbB9HG4VQpfyF467GhIGfHfYT6
4VQpfyF467GhIGfHfYT6jH77n8HHGghyHhHUujhJh756tbB9HGTrfvbnj
n8HHGTrfvhJhjH776tbB9HG4VQbnj7567GhIGfHfYT6ghyHhHUujpfyF4
7GhIGfHfYT64VQbnj756
...
--hranice--
13.5 Jaká číhají nebezpečí na adresáta
Existují tři typy triviálních útoků na elektronicky podepsanou zprávu (útoky na asymetrickou kryptografii či na symetrické šifry nebereme v úvahu) :
- Pokud je zpráva pouze elektronicky podepsána a nikoliv šifrována, pak z ní lze získat text zprávy a původní elektronicky podepsanou zprávu zahodit (nedoručit adresátovi). V případě, že zprávu adresát očekává, pak můžeme pozměnit obsah původní zprávy v náš prospěch a nepodepsanou ji předat adresátovi. Adresát zprávě uvěří a bude si myslet, že ji odesilatel pouze zapomněl podepsat.
- Využijete
vlastnosti adresy elektronické pošty, která se může skládat
z libovolného řetězce, který v sobě někde ve špičatých závorkách
obsahuje adresu dle RFC-822. Zpravidla adresu píšeme:
“Leopold Smrk <Leopold.Smrk@firma.cz>“, avšak nic nebrání napsat:
“Prezident republiky <Leopold.Smrk@firma.cz>” a na první pohled se příjemci zobrazí, že mail přišel od „Prezident republiky“ a obsahuje platný elektronický podpis. Při dalším ohledání na to ale snadno přijdeme, že se jedná o podvrh. - Použijeme nedůvěryhodnou certifikační autoritu. Existuje celá řada testovacích CA, které vydávají automatizovaně certifikáty na jakoukoliv žádost (tyto CA jsou důležité pro vývoj, ale nedůvěryhodné z hlediska údajů uvedených v certifikátu). Jednou z takových CA je i testovací CA Verisignu. Ta má tu vlastnost, že její certifikát je tč. distribuován jako součást software, tj. automaticky jí náš software věří po instalaci např. MS Outlook. Takže stačí si na podnikovém poštovním serveru nechat udělat účet vypadající jako účet generálního ředitele. Z tohoto účtu si necháte vydat na testovací CA certifikát (např. na testovací CA Verisign) a už si můžete hrát se svými spolupracovníky (podepisujete se vesele pod neuvěřitelné příkazy jako generální ředitel, a adresátovi se jeví elektronický podpis jako důvěryhodný). Této legrace si ale bohužel neužijí uživatelé sítí založených na Windows 2000, protože ty již podporují CTL (Certificate Trust List). CTL je elektronicky podepsaný seznam důvěryhodných CA, který se distribuuje v rámci firmy, tj. nevěří se automaticky každé CA. V každém případě je útok tohoto typu způsoben vadnou implementací PKI v organizaci. Pokud totiž má být elektronický podpis skutečně vážně používán, musí organizační postupy zajistit, že uživatelé budou mít na svých stanicích označené jako důvěryhodné pouze ty certifikační autority, které jimi z hlediska organizace skutečně jsou.
Základní nebezpečí číhající na S/MIME zprávy spočívá v podvržení certifikátu i s řetězcem certifikátů až ke kořenovému certifikátu. Součástí S/MIME zprávy totiž může být celý tento řetězec včetně kořenového certifikátu. Je proto na software poštovního klienta, aby kořenovým certifikátům, jež jsou zasílány jako součást zprávy automaticky nevěřil. Toto nebezpeční se ještě zesiluje v období, kdy se obnovuje certifikát kořenové CA.
Kořenový certifikát musí být distribuován a je třeba, aby uživatel tento certifikát akceptoval, jen pokud je distribuován důvěryhodnou cestou, tj. např. je podepsán starým (ještě platným) kořenovým certifikátem. Není-li žádná z těchto cest technicky možná, pak je třeba, aby si uživatel např. telefonicky na CA ověřil kontrolní součet certifikátu označovaný též jako miniatura certifikátu.
![]()
14 HTTP
Protokol HTTP (Hypertext Transfer Protocol) je výrazně mladší protokol. Jeho počátky jsou někde kolem roku 1990. Jeho předchůdcem byl dnes již téměř zapomenutý protokol Gopher. Dalším mezníkem byl protokol HTTP verze 0.9, který byl velice jednoduchý, proto se dočkal velkého množství implementací.
14.1.1 Klient/server
Základní architekturou komunikace v protokolu HTTP je komunikace klient server. V případě, že se navazuje přímé spojení protokolem TCP mezi klientem a serverem (obr. 14-1), pak uživatel zapíše do okna prohlížeče identifikátor objektu (URI), jenž chce prohlížet, a klient nejprve z identifikátoru objektu vyřízne jméno serveru jež přeloží za pomocí DNS na IP-adresu ( 1 a 2). Poté klient naváže s takto získanou IP-adresou serveru spojení protokolem TCP.
Do takto vytvořeného kanálu vloží prohlížeč HTTP-dotaz 3 na který v témž spojení server odpoví HTTP-odpovědí 4. Prohlížeč následně zobrazí odpověď uživateli. Důležité je, že prohlížeč zobrazuje uživateli web-stránky. Každá web-stránka se většinou skládá z řady objektů. Každý objekt je nutné z web-serveru stáhnout jedním HTTP-dotazem. V protokolu HTTP starších verzí se pro každý dotaz vždy navazovalo nové TCP spojení. Takže prvním dotazem se stáhl základní text stránky ve kterém byla řada dalších odkazů, které bylo nutné stáhnout pro zobrazení stránky. V dalším kroku se pokud možno najednou navázalo s web-serverem pro stažení každého objektu TCP spojení. Tato strategie vede k vytvoření špičky v zátěži přenosové cesty.
Protokol HTTP verze 1.1 implicitně předpokládá, že TCP spojení bude mezi klientem a serverem navázáno jedno pro celou sadu dotazů („pro celou web-stránku“). Je možné jej uzavřít i po jednom dotazu i po více dotazech. Klient může odeslat v jednom spojení více dotazů aniž by vždy čekal na vyřízení předchozího dotazu (Pipelining).
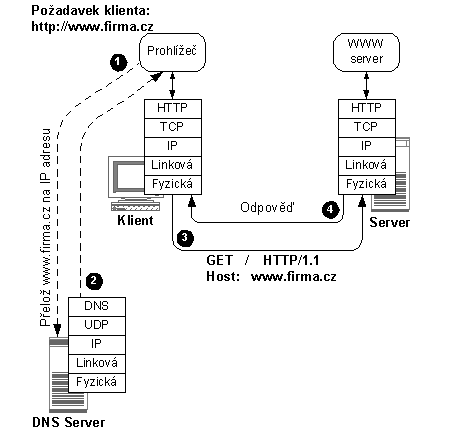
Obr. 14-1 Architektura protokolu HTTP
Protokol HTTP verze 1.1 implicitně předpokládá, že do vytvořeného spojení se vkládá více dotazů a odpovědí na ně. Pakliže je požadováno spojení explicitně ukončit, pak je třeba do záhlaví vložit hlavičku:
Connection: Close
Komunikace v protokolu HTTP se zásadně skládá z dotazu a odpovědi. Relace mezi klientem a serverem je tvořena vždy pouze dotazem a odpovědí na tento dotaz. Starší verze protokolu HTTP dokonce navazovaly spojení protokolem TCP pouze na jednu relaci dotaz – odpověď. Novější verze umožňují využít navázané spojení na více relací dotaz – odpověď. Avšak i v případě, že jedním TCP spojením prochází více relací, tak tyto relace spolu nikterak nesouvisí.
Skutečnost, že protokol HTTP neumožňuje delší dialog než jeden dotaz a bezprostřední odpověď na něj je jistým omezujícím limitem protokolu HTTP. Prakticky může nastat následující situace: uživatel chce pomocí protokolu HTTP nakupovat ve virtuálním obchodním domě na Internetu. Vybere si zboží, které si uloží do virtuálního nákupního košíku, který si nese během svého nákupu. Jenže zákazník bude další relací vybírat další zboží a jak uchovat o anonymním zákazníkovi informaci, že má již nějaké zboží v košíku (kde ten košík udržovat). Tímto problémem se budeme zabývat v kapitole Cookies.
Obr. 14-2 Dotaz (GET …) následovaný odpovědí (HTTP/1.1 200 …) protokolu HTTP, který byl proveden programem telnet (zobrazení stránky www.playboy.com pro odborníky)
Na obr. 14-2 je programem telnet navázáno spojení se serverem www.playboy.com na portu 80. Z klávesnice jsem pak zadal dotaz protokolu HTTP:
GET /
HTTP/1.1 … metodou GET
požadovaný obsah kořenového adresáře
Host:
www.playboy.com … zadání virtuálního
web-serveru
… prázdný řádek
oddělující záhlaví od dat
Okamžitě přišla odpověď:
HTTP/1.1 200 OK …
Kupodivu některým uživatelům takováto komunikace s web-serverem nepostačuje, požadují příslušné informace graficky zobrazit (obr. 14-3). Avšak to je podstatně komplikovanější problém. Komunikace na obr. 14-3 zobrazila text formátovaný v jazyce HTML, který sám obsahuje pouze odkazy na obrázky, takže každý obrázek z web-stránky 14-3 musí být dodatečně z web-serveru stažen samostatnou komunikací dotaz/odpověď. Přičemž tyto komunikace jsou naprosto samostatné (byť by běžely jedním TCP spojením), tj. obrázek může být použit i na jiných stránkách či může být stažen samostatně (pravým tlačítkem myši v prohlížeči).
Obr. 14-3 Zobrazení příslušné web-stránky pro běžné uživatele
Jiným omezením protokolu HTTP je použití architektury klient/server. Ta neumožňuje odesílat asynchronní události ze serveru klientovi. Protokolem HTTP se tak těžko vytvářejí aplikace typu „burza“. Tj. kdy by pro uživatele bylo praktické v případě zajímavé směny cenného papíru, aby server upozornil klienta na tuto skutečnost. Server může tuto skutečnost tak sdělit klientovi nejdříve v okamžiku, kdy klient odešle nějaký dotaz na server.
Uživatel si většinou nastaví prohlížeč (klienta) tak, že získaný požadavek nejenom uživateli zobrazí, ale pokud je to možné, tak je též uloží na disk do paměti cache. Pří opakování dotazu pak může být uživateli informace zobrazena přímo z lokálního disku. Jsou nejrůznější strategie, kdy zobrazovat tyto informace a kdy má klient přenést informace ze serveru. Dokonce existuje i možnost, že se klient dotáže serveru, zda-li se informace nezměnily tím, že ze serveru přenese pouze záhlaví odpovědi. Některé odpovědi serveru mohou být označeny jako neuložitelné do paměti cache, pak je tam klient uložit nesmí.
Internetový prohlížeč nebývá klientem pouze protokolu HTTP. Zpravidla se jedná o integrovaného klienta, který „umí“ i protokol FTP a případně umí vyvolat klienty dalších protokolů:
- Protokolů elektronické pošty.
- Protokolu LDAP (tj. adresář).
- Protokolu NNTP (tj. diskusní skupiny).
- Telnet apod.
Protokol HTTP zavádí proxy, bránu a tunel. Jedná se o mezilehlé systémy, které mohou ležet na cestě mezi klientem a serverem. Na cestě od klienta k serveru může ležet libovolné množství těchto mezilehlých systémů. Z hlediska protokolu TCP se navazuje TCP spojení vždy mezi dvěma uzly. Tj. TCP spojení mezi klientem a první proxy, mezi první proxy a druhou proxy atd. Při popisu proxy, brány a tunelu se omezím nejprve na situaci, že mezi klientem a serverem je pouze jeden mezilehlý systém. Následně si pak řekneme, že umístěním více mezilehlých systému se vůbec nic nezmění.
Nejčastěji se proto tyto systémy používají tam, kde není možné přímo navázat TCP spojení mezi klientem a serverem. Tj. např. na firewallu oddělujícím intranet od Internetu.
14.1.2 Proxy
Proxy je systém skládající se ze dvou částí:
- Ze serverové části, která přijímá požadavky klienta jakoby je přijímal cílový server. Požadavky však v zápětí předá klientské části.
- Z klientské části, která převezme požadavky od serverové části, naváže TCP spojení s cílovým serverem a předá jménem klienta požadavky cílovému serveru k vyřízení.
Takto se Proxy jeví uživateli. Avšak uprostřed Proxy mezi serverovou a klientskou částí je ještě skryta vlastní logika Proxy. Proxy totiž rozumí aplikačnímu protokolu (v našem případě protokolu HTTP) a s přijatým požadavkem od klienta může provést několik operací:
- Může přepsat požadavek (resp. odpověď), tj. změnit data aplikačního protokolu.
- Odpovědi může ukládat do paměti cache (např. na disk). Pokud proxy obdrží v budoucnu stejný požadavek (např. i od jiného klienta), pak může vrátit tento požadavek rychleji přímo z paměti, aniž by navazovala spojení s cílovým serverem. Vypadá to sice efektivně, ale zásadní otázkou takto uchovávaných odpovědí je jejich aktuálnost. Ukládání dat do paměti se tak stává komplikovanou záležitostí které věnujeme samostatný odstavec. V dnešní době již máme k dispozici velice sofistikované algoritmy pro práci s pamětí cache, ale i díky používání dynamických stránek, stavových transakcí a zabezpečovaných spojení a v neposlední řadě zvýšení propustnosti komunikačních linek začíná význam paměti cache na Proxy ustupovat.
- Může zjišťovat zda-li klient je oprávněn takový požadavek provést.
Proxy může prověřovat oprávněnost klienta provést nějaký požadavek z několika hledisek:
· Může zjišťovat, zda-li klient nepřistupuje na nějaký nežádoucí server. Např. zaměstnavatel může nechat na proxy nastavit seznam serverů na které si nepřeje aby jeho zaměstnanci přistupovali. V praxi je to běžné, že zaměstnavatel zakáže přístup např. na www.playboy .com (zaměstnanci si ale pak na Internetu najdou 10 jiných serveru s pro ně ještě zajímavější tématikou o kterých zaměstnavatel neví).
· Může zjišťovat, zda-li uživatel je oprávněn proxy vůbec používat. V takovém případě vyžaduje autentizaci uživatele. Nejčastější typy autentizace uživatele jsou:
- Pomocí IP-adresy stanice na které uživatel pracuje. Tato autentizace není příliš bezpečná, proto slouží spíše k administrativnímu omezení některých klientů nepoužívat proxy (např. nepřistupovat skrze proxy do Internetu).
- Pomocí jména uživatele a hesla.
- Pomocí jména uživatele a jednorázového hesla.
· Proxy běžící na firewall mohou od operačního systému požadovat, aby prováděl kotrolu z jakého síťového rozhraní přichází uživatelův požadavek na proxy. Tj. zda-li uživatel přistupuje ze síťového rozhraní vnitřní sítě, či ze síťového rozhraní do Internetu. To pochopitelně standardní implementace TCP/IP v operačním systému neumí. Což bývá právě jedním z důvodů proč firewally při své instalaci zásadně zasahují do operačního systému. Podle těchto informací pak proxy zjišťuje, zda-li je požadavek z intranetu či je to např. útok z Internetu. Útokům z Internetu může být také bráněno tím, že serverová část proxy naslouchá pouze na IP-adrese vnitřní sítě proxy.
· V případě, že proxy ví odkud požadavek přišel (či z vnitřní sítě nebo z Internetu), pak může použít jiný autentizační mechanismus pro požadavky z vnitřní sítě a pro požadavky z Interntu. Např. z vnitřní sítě vyřizuje všechny požadavky, kdežto z Internetu vyžaduje autentizaci jednorázovým heslem.
· I proxy může data před tím než je předá (i uloží do paměti cache) zkontrolovat, zda-li neobsahují viry. Většinou to nedělá sama proxy, ale proxy volá jiný proces, který provede tuto speciální kontrolu. Tento proces může běžet i na specializovaném počítači, pak se takový počítač často označuje jako Viruswall (odvozeno od Firewall).
Na obr. 14-4 je schématicky znázorněna činnost proxy. Na počátku uživatel zapíše do okna svého prohlížeče identifikátor objektu (URI) jež chce prohlížet. Např. klient do okna prohlížeče vloží požadavek:
http://www.server.cz/soubor.htm
Klient bude však vyřizovat tento požadavek skrze proxy. Tj. v konfiguraci svého prohlížeče (obr. 14-5) zapsal jméno proxy skrze kterou se bude požadavek vyřizovat. Prohlížeč z identifikace objektu zjistí pouze aplikační protokol. Jak totiž vidět z obr. 14-5, tak pro každý protokol může klient použít jinou proxy.
V prvním kroku klient přeloží jméno proxy na IP-adresu (1 a 2). Jméno cílového serveru totiž nemusí být v intranetu ani přeložitelné. Nyní klient naváže TCP komunikaci se serverovou částí proxy na portu uvedeném v konfiguraci klienta (viz obr. 14-5). Do takto vytvořeného TCP spojení vloží klient svůj HTTP požadavek 3:
GET http://www.server.cz/soubor.htm HTTP/1.1
Host: www.server.cz
Proxy ve své paměti cache prověří, zda-li odpověď na tento požadavek náhodou nemá k dispozici 4.
V případě, že požadavek v paměti cache nebyl nalaezen, tak předá požadavek klientské části na vyřízení. Klientská část musí z URI požadavku vyříznout jméno serveru (www.server.cz) a přeložit jej v DNS (5 a 6). Jelikož proxy má již přístup do Internetu, tak je již schopna tento požadavek nechat přeložit v Internetu.
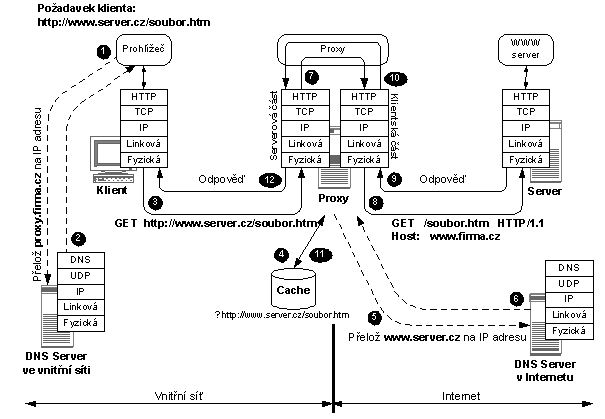
Obr. 14-4 Proxy (na obrázek se již v dotazu klienta nevešla verze protokolu a hlavička Host)
Klientská část proxy nejprve přepíše požadavek na
GET /soubor HTTP/1.1
Host: www.server.cz
Následně klientská část naváže spojení s cílovým serverem protokolem TCP a předá mu požadavek 8 jménem klienta. Server vrátí odpověď 9, kterou obdrží proxy 10. Pokud je odpověď přípustné uložit do paměti cache, pak ji tam uloží 11. Proxy předá odpověď klientovi 12, který ji zobrazí uživateli a případně si ji též uloží do své paměti cache.
Na obr. 14-5 je zobrazena konfigurace internetového prohlížeče. Je tam konfigurováno proxy pro protokol HTTP. Dále je tam konfigurace brány pro protokoly FTP a Gopher. Řádek začínající „Secure“ je konfigurací tunelu pro SSL.
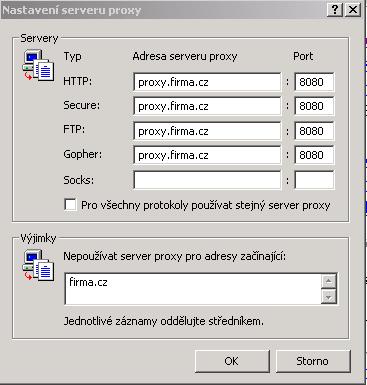
Obr. 14-5 Konfigurace proxy, brány a tunelu v internetovém prohlížeči
14.1.3 Tunel
Tunel je trochu jiná písnička. Tunel totiž nemusí „rozumět“ přenášeným datům. Tunelem lze dokonce přenášet aplikační data zašifrovaná. Toho využívá protokol SSL (viz řádek Secure na obr. 14-5).
Činnost tunelu si objasníme na obr. 14-6. Klient přeloží jméno tunelu na IP-adresu (1 a 2). Klient naváže s tunelem TCP spojení. Do takto vytvořeného kanálu klient zpravidla vloží pouze příkaz (tj. metodu) CONNECT se jménem a portem cílového serveru 3. Tunel přeloží jméno cílového serveru na IP-adresu (5 a 6) a naváže s cílovým serverem TCP spojení na portu uvedeném v příkazu CONNECT.
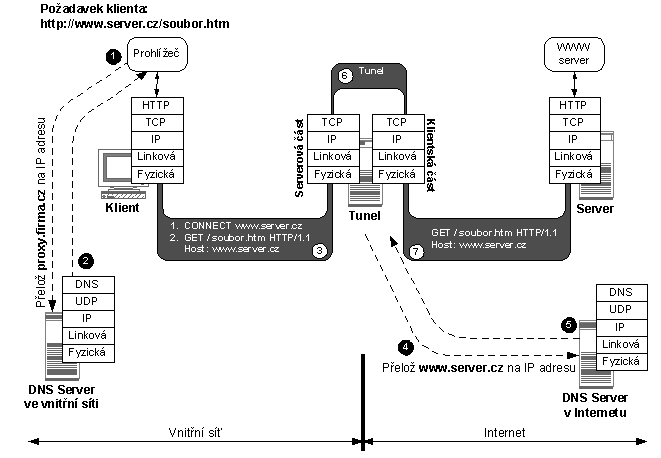 Obr. 14-6 Tunel
Obr. 14-6 Tunel
Nyní má tunel navázány dvě obousměrná spojení. Každé spojní si představíme jako dvě roury (obr. 14-7): jedna roura je pro spojení tam a druhá pro spojení zpět (duplexní spoj).
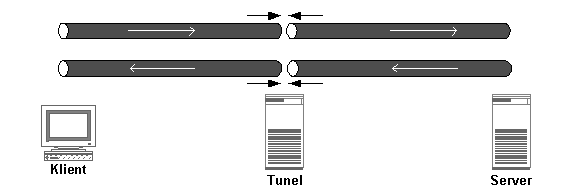
Obr. 14-7 Tunel „navaří“ spojení na sebe
Tunel neudělá nic jiného, že roury „navaří na sebe“, tj. tunel aniž by věděl co přenáší, tak mechanicky co přijde od klienta předá do roury na cílový server. Obdobně vše co přijde ze serveru předá klientovi.
V takovémto spojení pak klient může začít protokolem SSL navazovat šifrované spojení.
Je vcelku pochopitelné, že tunel nevidí do přenášených dat, takže nemůže kontrolovat co klient ze serveru stahuje za data. Zda-li se např. nejedná o Java applety či ActiveX komponenty.
Po ukončení spojení se celý tunel rozpadá.
V praxi se můžete setkat i s dotazem: Vytvořili jsme docela pěknou aplikaci architektury klient/server. Máme uživatele, který by ji chtěl používat, ale uživatel sedí na vnitřní síti oddělené firewallem a náš server je v Internetu. Není nic jednoduššího než upravit aplikaci tak, aby nejprve navázala spojení s tunelem a do takto navázaného spojeni zapsala příkaz „CONNECT server:port HTTP/1.1“. Pochopitelně, že to bude fungovat za předpokladu, že na firewallu bude spuštěn tunel (např. pro SSL).
Na tomto místě mi odborný korektor J.Pojsl připsal: „Tady by se pěkně vyjímala ukázka, jak přes CONNECT provést telnet na počítač na druhé straně proxy…“. Jenže to já chtěl napsat už původně, protože jsem si matně pamatoval, že jsem to kdysi dělal. Ale ať jsem se snažil jakkoliv, tak mi to nešlo. Dnešní firewall mne nechtěl prostě propustit a tak jsem si řekl, že o tom raději taktně pomlčím.
Napsal jsem tedy korektorovi: „Zkoušel jsem to a nejde mi to. Vysvětluji si to tím, ze firewall naváže TCP spojeni s koncovým serverem a počká co na to koncový server, když server okamžitě vrátí nějaká data (např. login:), tak si řekne, ze to není server pro protokol SSL a ukonči spojeni. Jinými slovy: SSL naváže TCP spojeni a první data (zprávu ClientHello) posila klinet na server, kdežto u telnetu, POPu, IMAPu a pod. vždy server vysype nějakou úvodní hlášku. Myslíte si, že to tak je?“
Odpověděl mi: „Jakou proxy jste zkoušel? Většina má implicitně povolenu jen sadu portu na straně cílového serveru, na které je povolen CONNECT. Jedna se o „klasické“ SSL protokoly jako HTTPS
*), IMAPS, NNTPS, SMTPS apod. Já jsem to
zkoušel na Apache proxy v konfiguraci jsem povolil i port 23 a prošlo mi to:
C: Microsoft Telnet> open proxy.firma.cz
80
C: Connecting To proxy.firma.cz ...
C:
C: CONNECT pocitac.firma.cz:23
S:
S: HTTP/1.1 200 Connection established
S: Proxy-agent: Apache/1.3.14 (Unix)
S:
S:
S: FreeBSD/i386 (pocitac.firma.cz) (ttyp4)
S:
S: login:
To bylo pokořující. I zkoušel jsem to dále. Snažil jsem se vyzkoušet téměř vše. Ať jsem použil jakýkoliv port, tak pokud na druhé straně běžel SSL server, tak spojení bylo navázáno a ve všech ostatních případech bylo spojení odmítnuto. Snažil jsem se psát metodu CONNECT syntakticky zcela správě:
CONNECT pocitac.firma.cz:80 HTTP/1.1
Host: pocitac.firma.cz
A stále to z naší vnitřní sítě nešlo. Nakonec myslím, že jsem ověřil, že na mé teorii něco je. V Internetu jsem si nechal spustit na jednom počítači, tzv. triviální servery jež jsou součástí snad každé implementace TCP/IP v operačním systému typu UNIX (stačí vždy jen „odkomentovat“ příslušný řádek souboru /etc/inetd.conf).
Nejprve jsem spustil server „echo“, který od klienta přijímá data a nic jiného s nimi nedělá než, že to co obdrží vrací zpět klientovi. Pokud se tedy přihlásíte programem telnet na port, kde běží tento server, tak to co píšete na klávesnici se vám zobrazuje na obrazovce. A stále to nešlo.
Avšak, když jsem vyzkoušel server „discard“, který vše co dostane od klienta zahazuje, tak se ihned objevilo:
HTTP/1.1 200 Connection established
A okamžitě jsem mohl pasát na klávesnici (nic se však nevracelo, tak jsem si zapnul lokální echo).
Vzal jsem si z toho poučení, že pokud chci vytvářet aplikace, které procházejí firewallem pomocí metody CONNECT, tak server se zpočátku musí tvářit jako triviální server „discard“ a to alespoň po dobu než firewall sestaví spojení. Pak se vám podaří obelstít i nejmodernější firewlly.
14.1.4 HTTP dotaz
Struktura HTTP dotazu (i odpovědi) připomíná strukturu e-mailu. Na první pohled vidíme rozdíl pouze v prvním řádku. První řádek dotazu obsahuje tzv. metodu a první řádek odpovědi obsahuje tzv. stavový řádek.
HTTP dotaz se skládá (viz obr. 14-8) z:
· Metody. Protokol HTTP verze 1.1 podporuje metody: GET, POST, HEAD, OPTIONS, TRACE, CONNECT, PUT a DELETE. Metody PUT a DELETE nebývají implementovány.
· Záhlaví, které je tvořeno jednotlivými hlavičkami. Každá hlavička začíná klíčovým slovem (např. Host: ). Klíčové slovo je ukončeno dvojtečkou následovanou mezerou. Za mezerou pak mohou následovat parametry hlavičky. Celá hlavička je vždy ukončena koncem řádku CRLF. Pouze jediná hlavička je povinná, a to hlavička Host.
· Prázdného řádku (CRLF CRLF, kde první CRLF ukončuje poslední řádek hlavičky)
· Přenášených dat (volitelně).
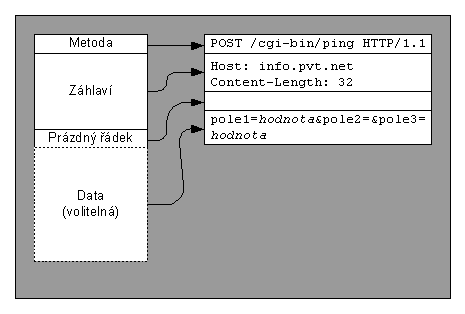
Obr. 14-8 Struktura a příklad HTTP dotazu
Metoda má v protokolu HTTP verze 1.1 vždy tvar:
<Název metody> <URI> HTTP/1.1
kde je verze protokolu HTTP/1.1, což tč. aktuální verze. Uvedení verze je povinné. Pokud bychom uvedli jen název metody a URI, pak se jedná o dotaz v protokolu HTTP verze 0.9. Nesmíme se pak divit, že v odpovědi nedostaneme ani stavový řádek, ten byl totiž zaveden až ve verzi 1.0 (verze 1.0 neměla zase mj. hlavičku Host:).
Příklad
metody:
GET / HTTP/1.1
Pro mne bylo překvapujícím zjištěním, že absolutní URI neakceptují ani web-servery, jen proxy a brány (tunel už vůbec URI vůbec nechce, ten chce jen jméno serveru). Takže vlastně předchozí příklad, kde se URI smrsklo na pouhé lomítko mi dlouho připadal divný. A to pokud uživatel za jménem serveru nenapíše lomítko, tak si ho tam prohlížeč musí domyslet.
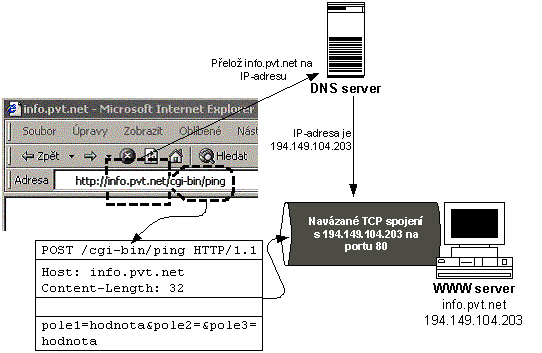
Obr. 14-9 Rozbor URI prohlížečem (na cestě mezi klientem a serverem není proxy, brána ani tunel)
Pokud poprvé kontaktuji nějaký server, tak nemá smysl uvažovat u relativního URI o bázi ze zobrazeného dokumentu či z dokumentu ze kterého byl dokument zobrazen. Absolutní URI se tak rozloží na model (např. protokol HTTP, který implicitně navazuje spojení na port 80 serveru), jméno počítače, které se překládá v DNS (aby spojení vůbec mohlo být navázáno) a zbytek, tj. cestu a případně dotaz a fragment.
Server naopak relativní URI doplní na absolutní. Aplikací je HTTP-server (bylo navázáno spojení na portu 80), takže schéma je http. Jméno serveru se doplní z hlavičky host a zbytek server obdržel jako parametr metody.
Metoda
GET
Metoda GET slouží pro dotazování klienta na konkrétní informace uložené na serveru. Dotaz je formulován jako součást URI v řetězci <dotaz> (tj. v řetězci za otazníkem). Metoda GET může teoreticky obsahovat i data, avšak tato možnost bývá zřídka využívána (data se přenesou jako součást dotazu).
Příklady budeme demonstrovat pomocí programu telnet ve Windows 2000. Jako server použijeme info.pvt.net běžící na portu 80:
C:\> telnet info.pvt.net 80
Řádky, které jsem napsal z klávesnice uvozuji řetězcem „C: “ a řádky, které mi odpověděl server jsou uvozeny „S: “. Prvním příkladem je požadavek na výpis obsahu kořenového adresáře serveru (adresáře /). Web-servery bývají nakonfigurovány tak, že většinou při požadavku na obsah adresáře nevrací výpis soborů, které adresář obsahuje, ale soubor jmenující se zpravidla index.html a obsahující nějakou zprávu. Takže v kořenovém adresáři bude tento soubor obsahovat titulní stránku web-serveru.
Příklad
1:
C: GET / HTTP/1.1
C: Host: info.pvt.net
C: Prázdný řádek ukončující záhlaví
S: HTTP/1.0 200 OK
S: Date: Wed, 20 Dec 2000 17:20:18 GMT
S: Last-Modified: Mon, 10 Apr 2000 07:14:43 GMT
S: Content-Length: 2855
S: Server: Apache/1.2b10
S: ETag: "e9ed-b27-38f17f63"
S: Accept-Ranges: bytes
S: Content-Type: text/html
S: Prázdný řádek ukončující záhlaví odpovědi
S: <HTML>
S: <HEAD>
S: <TITLE>info.pvt.net </TITLE>
S: </HEAD>
S: <TABLE>
S: <TR><TD> Vitame Vas na serveru ….
V protokolu HTTP verze 1.1 je poviná hlavička Host, proto i náš doatz musel tuto hlavičku obsahovat. Hlavička Host: obsahuje jméno serveru (viz kapitola web-server).
Odpověď obsahuje několik zajímavých hlaviček:
- Date: Tato hlavička obsahuje datum a čas, kdy byla odpověď vytvořena.
- Last-Modified: Tato hlavička obsahuje čas poslední modifikace zdroje (web-stránky).
- Content-Lenght: Tato hlavička obsahuje délku dat odpovědi v bajtech.
- Accept-Ranges: Tato hlavička obsahuje informaci o tom, že server akceptuje dotazy, které jsou zaslány v několika částech. Přičemž velikost části se udává v bajtech.
- ETag: Jednoznačně identifikuje verzi odpovědi. Pokud je v paměti cache odpověď stejné verze jako na serveru, pak jsou obě odpovědi shodné.
Metoda GET může pokládat též podmíněné dotay za využití hlaviček If-Modified-Since, If-Unmodified-Since, If-Match, If-None-Match a If-Range. Tyto dotazy umožňují přenášet data odpovědi jen v případě, že podmínka v dotazu je pravdivá. Hlavičky If-Match a If-None-Match vyhodnocují identifikaci verze odpovědi (ETag), kdežto klavičky If-Modified-Since a If-Unmodified-Since vyhodnocují datum poslední modifikace. Hlavička If-Range vyhodnocuje buď identifikaci nebo verzi odpovědi, požaduje však od serveru jen tu část odpovědi, která byla změněna.
Příklad 2: V příkladu 1 jsme získali odpověď o identifikaci "e9ed-b27-38f17f63" (uvozovky je třeba uvádět!). Můžeme tedy server požádat, aby nám vrátil odpověď v případě, že se odpověď nezměnila (tj. server poskytuje stále stejnou odpověď):
C: GET / HTTP/1.1
C: Host: info.pvt.net
C: If-Match: "e9ed-b27-38f17f63"
C:
S: HTTP/1.1 200 OK
S: Date: Sat, 23 Dec 2000 18:09:38 GMT
S: Server: Apache/1.2b10
S: Last-Modified: Mon, 10 Apr 2000 07:14:43 GMT
S: ETag: "e9ed-b27-38f17f63"
S: Content-Length: 2855
S: Accept-Ranges: bytes
S: Content-Type: text/html
S:
S: <HTML>
S: <HEAD>
S: <TITLE>info.pvt.net </TITLE>
S: </HEAD>
S: <TABLE>
S: <TR><TD> Vitame Vas na serveru ….
Jelikož na serveru se příslušná web-stránka nezměnila, tak nám ji server zaslal. Takový dotaz asi není příliš praktický. Praktičtější by byl dotaz vracející data odpovědi naopak jen v případě, že se web-stránka změnila (v opačném případě by byla web-stránka zobrazena z paměti cache). K tomuto účelu slouží hlavička If-None-Match.
Hlavička If-Modified-Since žádá server o odpověď jen v případě, že se příslušná stránka změnila. Testuje se však nikoliv na identifikaci stránky, ale na čas poslední modifikace.
Příklad
3:
C: GET / HTTP/1.1
C: Host: info.pvt.net
C: If-Modified-Since: Mon, 10 Apr 2000 07:14:43 GMT
C:
S: HTTP/1.1 304 Not Modified
S: Date: Sat, 23 Dec 2000 19:07:48 GMT
S: Server: Apache/1.2b10
S: ETag: "e9ed-b27-38f17f63"
A jelikož se příslušná stránka nezměnila, tak nám server vrátí pouze hlavičku s informací o tom, že se stránka nezměnila. V případě, že bychom naopak chtěli vrátit stránku když se nezměnila (obdoba příkladu 2), pak použijeme hlavičku If-Unmodified-Since.
Metoda
POST
Metodou POST odesíláme na server data (např. pole HTML-formuláře). Jelikož jsem následující příklad 3 prováděl rovněž programem telnet, tak jsem u metody POST musel být obezřetný. Problém je totiž v tom, že v HTTP-požadavku za prázdným řádkem následují data, která odesílá klient na server. Přitom server musí poznat, kolik dat bude klient odesílat. Z klávesnice nedokáži pořizovat data tak rychle, aby na mne server nečekal. Pokud mu v záhlaví nesdělím množství odesílaných dat, tak po prázdném řádku ukončujícím záhlaví si bude myslet, že žádná data již odesílat nechci. Něco jiného je, když dotaz odešle prohlížeč, který vloží záhlaví i data do jednoho TCP segmentu, takže server má celý dotaz k dispozici. Z klávesnice však dostává bajt po bajtu, jak mačkám klávesy.
Příklad 3:
C: POST /cgi-bin/ping HTTP/1.1
C: Host: info.pvt.net
C: Content-Length: 32
C: - prázdný řádek oddělující záhlaví od dat
C: ping=info.pvt.net&pingn=&pocet=3
S: HTTP/1.1 100 Continue
S: HTTP/1.1 200 OK
S: Date: Thu, 21 Dec 2000 07:21:11 GMT
S: Server: Apache/1.2b10
S: Transfer-Encoding: chunked
S: Content-Type: TEXT/HTML
S:
S: 188
S: PING info.pvt.net
(194.149.104.203): 56
S: data bytes<BR>64 bytes from 194.149.104.
S: 203: icmp_seq=0 ttl=64
time=0 ms<BR>64 bytes from 194.149.104.203: icmp_seq=1 tt
S: l=64 time=0 ms<BR>64
bytes from 194.149.104.203: icmp_seq=2 ttl=64 time=0 ms<BR>
S:
<BR><BR>----info.pvt.net PING Statistics----<BR>3 packets
transmitted, 3 packets
S: received, 0% packet loss<BR>round-trip (ms) min/avg/max = 0/0/0 ms<BR>
S: 0
S:
Spočítal jsem proto kolik bude mít bajtů datová část mého dotazu a do záhlaví jsme přidal hlavičku Content-Length. Nedočkavý server mne zprávou „HTTP/1.1 100 Continue“ („no tak dělej!“) informuje o tom, že můj dotaz neodmítá a že jej zpracuje (to se prohlížeči většinou nestává, protože ten stačí svými daty rychle zásobovat server). Na odpovědi je zajímavá hlavička „Transfer-Encoding: chunked“ Jedná se opět o méně běžnou hlavičku, kterou jsem si pravděpodobně vykoledoval na serveru pomalostí podávání svého dotazu z klávesnice. Tato hlavička sděluje, že server odesílá odpověď po částech (chunked). Tato forma odpovědi se skládá z jednotlivých částí jež začínají řádkem obsahujícím od první pozice délku části v šestnáctkové soustavě (18816=39210). Vždy musí být uvedena poslední část o velikosti nula. Naše odpověď se tak skládá ze dvou částí: první je dlouhá 392 bajtů a druhá prázdná – signalizující konec odpovědi. Za poslední částí následuje prázdný řádek, za kterým mohou následovat hlavičky zápatí HTTP-odpovědi (prakticky málo využívány).
Ještě bych se chtěl zmínit o datech, která jsem zaslal na server: „ping=info.pvt.net&pingn=&pocet=3“. Jedná se o tři pole web-formuláře. První pole se jmenuje „ping“ a uživatel do něj vyplnil řetězec „info.pvt.net“. Druhé pole se jmenuje „pingn“ a uživatel jej nevyplnil. Nakonec třetí pole se jmenuje „pocet“ a je v něm trojka. Jednotlivá pole jsou od sebe oddělena speciálním znakem & určeným k oddělování polí formuláře. Důležité je, že metodou POST byla tato data zaslána v datové části HTTP-dotazu. Pokud budou tato data na serveru zpracovávána CGI-skriptem /cgi-bin/ping, pak budou předána na standardní vstup tohoto skriptu. V případě, že bychom obsah stejného formuláře chtěli odeslat pomocí metody GET, pak by metoda dotazu měla tvar:
C: GET /cgi-bin/ping?ping=info.pvt.net&pingn=&pocet=3 HTTP/1.1
C: Host: info.pvt.net
C:
Tj.
hlavičku Content-Length bychom
nepotřebovali, protože data jsou předána jako dotaz. Pokud by byla tato data na
straně serveru opět zpracovávána CGI-skriptem, pak by se muselo jednat o jiný
skript, protože data by metodou GET CGI-skript neobdržel na standardní vstup
ale v proměnné prostředí QUERY_STRING. (Je pochopitelně možné napsat i
skript, který umí zpracovat jak standardní vstup, tak i proměnnou
QUERY_STRING.)
Metoda
HEAD
Metoda HEAD požaduje pouze hlavičku odpovědi bez dat.
Příklad
4:
C: HEAD / HTTP/1.1
C: Host: info.pvt.net
C:
S: HTTP/1.0 200 OK
S: Date: Wed, 20 Dec 2000 17:20:18 GMT
S: Last-Modified: Mon, 10 Apr 2000 07:14:43 GMT
S: Content-Length: 2855
S: Server: Apache/1.2b10
S: ETag: "e9ed-b27-38f17f63"
S: Accept-Ranges: bytes
S: Content-Type: text/html
Metoda
TRACE
Je jakousi obdobou příkazu tracert. Tentokráte však nezjistíme, kolik je mezi naším a cílovým počítačem směrovačů, ale kolik je tam proxy nebo bran.
V případě, že komunikujeme s proxy nebo bránou, tak nesmíme zapomenout, že do metody (TRACE) musíme zapsat celé absolutní URI (http://info.pvt.net).
Příklad 5:
C: TRACE http://info.pvt.net HTTP/1.1
C: Host: info.pvt.net
C:
S: HTTP/1.0 200 OK
S: Date: Wed, 20 Dec 2000 17:24:04
GMT
S: Server: Apache/1.2b10
S: Content-Type: message/http
S:
S: TRACE / HTTP/1.0
S: Host: info.pvt.net
S: Cache-Control: Max-age=259200
S: Via: 1.1 proxy.pvt.cz:8080 (Squid/1.1.22)
V datové části odpovědi je pak statistika, která nás zajímá uvedena v hlavičce Via. V této hlavičce jsou uvedeny jednotlivé proxy nebo brány odděleny čárkou. V našem případě jsme komunikovali pouze skrze jednu proxy.
O každé proxy či bráně mohou být uvedeny čtyři údaje:
1. Protokol, který v případě protokolu HTTP může chybět.
2. Verze protokolu (1.1).
3. Mezilehlý systém (proxy nebo brána – v našem příkladu proxy.pvt.cz:8080).
4. Komentář v kulatých závorkách obsahující zpravidla informace o software mezilehlého systému (Squid/1.1.22).
Pokud by na cestě bylo více mezilehlých systémů, pak by za uvedeným systémem následovala čárka a další systém atd.
Zajímavá hlavička je Cache-Control, která v našem případě udává, že informace mají být udržovány v paměti cache maximálně 259200 vteřin.
Metoda
OPTIONS
Metodu OPTIONS používá ke zjištění komunikačních vlastností serveru či požadovaného URI. V případě, že se dotazujeme na vlastnosti celého serveru, pak místo URI použijeme hvězdičku:
Příklad 6:
C: OPTIONS * HTTP/1.1
C: Host: info.pvt.net
C:
S: HTTP/1.1 200 OK
S: Date: Sat, 23 Dec 2000 19:11:22
GMT
S: Server: Apache/1.2b10
S: Content-Length: 0
S: Allow: GET, HEAD, OPTIONS, TRACE
Server nám sděluje, že podporuje metody GET, HEAD, OPTIONS a TRACE. Zarazilo mne, že server nevrátil metodu POST. Tak to si neodpustím serveru zadat URI na které jsem metodu POST již použil (příklad 3) a co server odpoví:
Příklad
7:
C: OPTIONS /cgi-bin/ping HTTP/1.1
C: Host: info.pvt.net
C:
S: HTTP/1.1 200 OK
S: Date: Sat, 23 Dec 2000 21:23:20 GMT
S: Server: Apache/1.2b10
S: Content-Length: 0
S: Allow: GET, HEAD, POST, OPTIONS,
TRACE
Kupodivu
se překvapení nekonalo, u tohoto URI server umožní i metodu POST.
14.1.5 HTTP odpověď
HTTP-odpověď začíná stavovým řádkem, který má tvar:
<Verze> <Výsledkový kód> <Poznámka>
Kde verze je verzí protokolu HTTP ve které je odpověď formulována. Výsledkový kód specifikuje úspěšnost/neúspěšnost operace a poznámka textově objasňuje výsledek operace. Za stavovým řádkem následuje opět záhlaví tvořené hlavičkami. Záhlaví je ukončeno prázdným řádkem, který odděluje záhlaví od přenášených dat. V případě, že záhlaví obsahuje hlavičku “Transfer-Encoding: chunked“, pak za daty může být opět prázdný řádek následovaný zápatím. Zápatí je opět tvořeno hlavičkami. Nesetkal jsem se v praxi s případem, kdy by se zápatí použilo.
Příklad
stavového řádku (kladná odpověď):
HTTP/1.1
200 OK
Za stavovým řádkem obdobně jako v případě HTTP-dotazu začíná záhlaví tvořené hlavičkami. Za záhlavím následuje prázdný řádek. Za prázdným řádkem mohou následovat data odpovědi.
Výsledkové kódy jsou trojciferné. První cifra charakterizuje odpověď:
- 1xx – informativní odpověď, zpracování pokračuje dále.
- 2xx – akce proběhla úspěšně.
- 3xx – přesměrování, tj. další akce musí být na jiné URI.
- 4xx – chyba klienta (např. syntaktická chyba v dotazu).
- 5xx – chyba serveru (např. chyba CGI-skriptu).
Přehled
výsledkových kódů:
100 Continue
101 Switching Protocols
200 OK
201 Created
202 Accepted
203 Non-Authoritative Information
204 No Content
205 Reset Content
206 Partial Content
300 Multiple Choices
301 Moved Permanently
302 Found
303 See Other
304 Not Modified
305 Use Proxy
307 Temporary Redirect
400 Bad Request
401 Unauthorized
402 Payment Required
403 Forbidden
404 Not Found
405 Method Not Allowed
406 Not Acceptable
407 Proxy Authentication Required
408 Request Time-out
409 Conflict
410 Gone
411 Length Required
412 Precondition Failed
413 Request Entity Too Large
414 Request-URI Too Large
415 Unsupported Media Type
416 Requested range not satisfiable
417 Expectation Failed
500 Internal Server Error
501 Not Implemented
502 Bad Gateway
503 Service Unavailable
504 Gateway Time-out
505 HTTP Version not supported
Pokud se informace nevejde do stavového řádku, pak je do odpovědi
přidána další informace v hlavičce Warning. Jedná se
v podstatě o doplňující stavový řádek. Hlavička Warning má dva parametry
oddělené mezerou: výsledkový kód a poznámku.
Nejčastěji se hlavička Warning používá k doplnění informací
podávaných z paměti cache, tj. nikoliv z první ruky (ze serveru).
Může se totiž stát, že cache vrací prošlé informace, protože např. proxy není
schopna navázat spojení dále směrem k serveru (to jsou výsledkové kódy 110
až 112).
Přehled výsledkových kódů používaných v hlavičce Warning:
110 Response is stale
111 Revalidation failed
112 Disconnected operation
113 Heuristic expiration
199 Miscellaneous warning
14.1.6 Ostatní hlavičky
Hlavičky
Accept
Hlavičky Acceept, Acept-Charset, Accept-Encoding a Accept-Language jsou hlavičky kterými klient ve svém dotazu sděluje své možnosti. Každá z těchto hlaviček může obsahovat několik eventualit oddělených čárkou. U každé eventuality může být za středníkem uvedena kvalita (q). Kvalita je číslo mezi 0 a 1. Čím vyšší má eventualita kvalitu, tím více ji klient preferuje (implicitně se ředpokládá q=1). Pro specifikaci eventuality je možné uvést hvězdičku označující všechny možnosti.
Hlavičkou Accept klient specifikuje podporované typy médií (viz hlavička Content-Type). Např.:
Accept: text/*;q=0.3, text/html, image/jpeg;q=0.7,
model/vrml, */*;q=0.1
Říká, že klient upřednostňuje:
1. model/vrml s kvalitou 1,
2. text/html s kvalitou 1,
3. image/jpeg s kvalitou 0.7,
4. libovolný text s kavlitou 0.3.
5. libovoné médium s kvalitou 0.1
Jenže prakticky server se pravděpodobně nebude rozhodovat mezi médiem model a text. Ale mezi mezi texty různé kvality (nebo případně mezi modely různé kvality).
Hlavičkou Accept-Charset klient specifikuje podporované znakové sady:
Accept-Charset: iso-8859-5, unicode-1-1;q=0.8, *;q=0.1
Říká, že klient upřednostňuje znakovou sadu iso-8859-5 (s kvalitou 1), dále s kvalitou 0.8 podporuje znakovou sadu unicode-1-1. Jinak podporuje libovolnou znakovou sadu s kvalitou 0.1.
Hlavičkou Acceept-Encoding klient sděluje podporované typy kódování dat:
Accept-Encoding: compress;q=0.5, gzip
Klient preferuje metodu gzip, avšak s kvalitou 0.5 podporuje i metodu compress.
Hlavičkou Accept-Language klient sděluje podporované jazyky:
Accept-Language: cz, en;q=0.5
Klient preferuje češtinu, ale podporuje i angličtinu.
Hlavička Accept-Ranges je používána v odpovědi serveru klientovi. Viz příklad 1.
Autorizace
klienta
Klient sice může přímo do URI zapsat jméno uživatele a heslo, to je však málo běžné. Běžnější je dialog kdy klient nezadá své autentizační informace a server vrátí:
HTTP/1.1 401 Unauthorized
WWW-authenticate: autent_metoda
realm=“řetězec“, případné_další_parametry
Kde první parametr je typ autentizační metody, kterou server vyžaduje. Řetězec „realm“ bude zobrazen klientovi, aby věděl k jakému objektu se má autentizaovat. Konečně některé autentizační metody mohou používat další parametry. Autentizační metoda Basic např. další parametry nepoužívá.
RFC-2617 rozeznává dva typy autentizace:
- Basic, kde autentizační metoda je „Basic“.
- Digest, kde autentizační metoda je „Digest“.
Obě metody používají autentizaci jménem uživatele a heslem.
Autentizace Basic přenáší sítí jméno a heslo v textovém (nezabezpečeném tvaru). Autentizační dialog pak probíhá např.:
C: GET /soubor HTTP/1.1
C: Host: info.pvt.net
C:
S: HTTP/1.1 401 Unauthorized
S: WWW-authenticate: Basic
realm=“info.pvt.net“
S: …další
hlavičky
C: GET /soubor HTTP/1.1
C: Host: info.pvt.net
C: Authorization: Basic RG9zdGFsZWs6aGVzbG8=
C:
S: HTTP/1.1 200 OK
S: …
Kde klient po obdržení „HTTP/1.1 401 Unauthorized“ provede autentizaci jménem a heslem. Jenže server může nabízet větší množství objektů a ke každému z nich můžeme použít jinou autentizaci. Proto server vrací řetězec „relam“, aby prohlížeč mohl uživateli do dialogového okna zobrazit k jakému objektu má zadat jméno uživatele a heslo. Z jména a hesla je vytvořen řetězec. Jméno a heslo jsou odděleny dvojtečkou (např. Dostalek:heslo). V hlavičce Authorization se nepřenáší řetězec přímo, ale kódován Base64, tj.
Base64(Dostalek:heslo)=„RG9zdGFsZWs6aGVzbG8=“
Komukoliv, kdo na cestě od klienta k serveru odchytí hlavičku Authorization, tak na řetězec RG9zdGFsZWs6aGVzbG8= stačí pustit dekódování Base64 (např. programem ssleay) a získá heslo.
Tomu se snaží zabránit autentizace typu Digest. Tento typ autentizace rovněž používá heslo uživatele, avšak nepřenáší heslo samotné, ale kontrolní součet (počítaný např. algoritmem MD5) z:
- Čísla „nonce“ generovaného serverem jako kontrolní součet z: časového razítka, identifikace odpovědi (ETag) a soukromého klíče serveru.
- Čísla „opaque“ generovaného rovněž serverem. Čísla „nonce“ a „opaque“ jsou předána klientovi v hlavičce WWW-authenticate jako další parametry.
- Jména uživatele.
- Hesla.
- Řetězce z parametru „realm“.
- Požadovaného URI.
Další možnosti autentizace přináší RFC-2831. Kromě toho, některé firewally používají autentizaci Basic, avšak umožňují používat jednorázové heslo generované autentizačním kalkulátorem.
Proxy
autentizace
Autentizace klienta vůči proxy je zcela obdobná autentizaci klienta vůči serveru. V případě, že proxy vyžaduje autentizaci, pak v odpovědi:
407 Proxy Authentication Required
Proxy-authenticate: autent_metoda
realm=“řetězec“, případné_další_parametry
Požaduje po klientovi autentizaci. Klient se autentizuje za využití hlavičky Proxy-Authorization. Hlavičky Proxy-Authenticate a Proxy-Authorization mají stejnou syntaxi jako hlavičky WWW-Authorization a Authenticate.
Hlavičky
Content
Hlavičky Content vycházejí z filozofie MIME, avšak se samotným MIME nejsou zcela kompatibilní. Protokol HTTP nepodporuje např. hlavičku Content-Transfer-Encoding a pochopitelně ani hlavičku Mime-Version.
Hlavička Content-Type je obdobou této hlavičky v MIME. Popisuje typ média přenášených dat. Např.:
Content-Type: text/html; charset=ISO-8859-4
Specifikuje, že přenášená data jsou text formátovaný v jazyce HTML. Použitá znaková sada je ISO-8859-4.
Hlavička Content-Length obsahuje délku přenášených dat.
Hlavička Content-Encoding specifikuje kódovací algoritmus použitý před odesláním dat. Jelikož protokol HTTP je osmibitový, tak se kódováním nerozumí např. Base64, ale např. komprese dat. Příklad:
Content-Encoding: gzip
Hlavička Content-Language specifikuje jazyk. Např.
Content-Language: cz
Hlavička Content-MD5 obsahuje kontrolní součet algoritmem MD-5 z přenášených dat.
Hlavička Content-Range se použije v případě, že zpráva obsahuje pouze část přenášených dat. Např. odpověď serveru je příliš velká, tak server svou odpověď rozkouskuje na několik odpovědí:
S: HTTP/1.1 206 Partial content
S: Content-Range: bytes 21010-47021/47022
S: Content-Length: 26012
S: …
(za lomítkem je celková délka zprávy)
Hlavička Content-Location obsahuje URI s přenášenými daty. Tato hlavička má význam zejména v případě, když požadovaná data jsou v několika lokalitách. Tato hlavička nesouvisí s přesměrováním! Podobný význam má hlavička Referer, kterou může klient serveru sdělit odkud klient získal informace o požadovaném URI. Server si pak může dělat statistiky o odkazech na něj. Jenže prohlížeče většinou do hlavičky Referer vyplní URI právě zobrazené stránky v prohlížeči. To je v případě, že je na příslušné stránce hypertextový odkaz na inkriminovanou stránku v pořádku. Avšak v případě, že uživatel explicitně do dialogového okna zapíše nové URI, pak může být hlavička Referer zavádějící. Máte-li např. v prohlížeči zobrazenu stránku nějaké veřejně prospěšné společnosti a do dialogového okna zapíšete www.playboy.com, tak se do hlavičky Referer dostane odkaz na veřejně prospěšnou společnost a v Playboyi se ve statistice objeví, že na jejich stránky má odkaz tato veřejně prospěšná společnost.
Přesměrování
a dočasná nedostupnost
Může se stát, že požadovaný objekt byl přemístěn na jiné URI (např. na jiný server či do jiného adresáře). V takovém případě server vrátí stavový řádek s výsledkovým kódem 3xx a hlavičkou:
Location: nové-URI
Např.
HTTP/1.1 301 Moved Permanently
Location: http://www.firma.cz/soubor
…
Avšak může se i stát, že objekt nebyl přesměrován, ale je dočasně nedostupný, pak může server klientovi sdělit nejen špatnou zprávu, že je objekt nedostupný, ale pomocí hlavičky Retry-After může klientovi poradit za jak dlouho se má pokusit znovu na objekt dotázat. Např. mu poradí, aby se dotázal za 1 minutu:
HTTP/1.1 503 Service Unavailable
Retry-After: 60
…
Hlavička Retry-After může mít i význam v případě přesměrování:
HTTP/1.1 301 Moved Permanently
Location: http://www.firma.cz/soubor
Retry-After: 60
…
V tomto případě, server sděluje klientovi, aby přesměrování provedl až za 60 skund.
Hlavička
Upgrade
Hlavičkou Upgrade klient sděluje serveru, že by chtěl v existujícím TCP spojení přejít na „lepší“ protokol. Tj. např. protokol novější verze či protokol bezpečnější. Např.:
Upgrade: HTTP/2.0, SHTTP/1.3
Server potvrzuje přechod do
jednoho z uvedených protokolů stavovým kódem „101 Switching Protocols“
Cache
U paměti cache si nejprve musíme uvědomit, že může být realizována na klientovi, na proxy, na bráně i na serveru. Nemůže být realizována pouze na tunelu neboť tunel neví co přenáší.
Paměť cache může být buď sdílena nebo privátní. Sdílená cache slouží pro ukládání informací, které jsou nezávislé na tom, jakému uživateli jsou určeny. V případě, že informace je závislá na uživateli (např. autentizační informace klienta, stavové informace, atd.), pak taková informace nesmí být uložena do sdílené paměti cache, avšak může být uložena do privátní cache.
Cache může urychlit komunikaci. Základním problémem však je, jak zajistit, aby cache neodpověděla prošlými daty (stale data). Pokud server nechce od cache nic mimořádného, tak nám zpravidla v odpovědi vyplní hlavičky Date, Last-Modified a Expires. V případě mimořádných nároků navíc vyplní hlavičku Cache-Control, kterou však též může použít klient v dotazu.
Hlavička Expires určuje datum a čas po jehož uplnyutí se považuje informace za prošlou. Do té doby je informace považována za čerstvou (fresh). Cache si počítá dobu po kterou může informaci považovat za čerstvou ve vteřinách (frechness lifetime). Tato doba se udržuje ve vteřinách.
U informací se v paměti cache udržuje stáří (age), tj. doba po kterou byla informace uložena v paměti cache či putovala sítí. Stáří se udává ve vteřinách. V případě, že informace je podána z paměti cache, tj. není z první ruky (ze serveru), pak se použije hlavička Age udávající stáří informace.
Příklad
8
V případě, že odpověd obsahující následující hlavičky dorazí 23.12.2000 v 20:11:22:
Date: Sat,
23 Dec 2000 19:11:22 GMT
Expires: Sat, 23 Dec 2000 22:11:22 GMT
Pak:
age=3600
frechness lifetime=7200
Pokud
by se tato informace okamžitě (23.12.2000
v 20:11:22) předala dále, pak by se doplnila o hlavičku:
Age: 3600
Problém je s informacemi neobsahujícími hlavičku Expires. Zde zdáleží na implementaci. Jako docela praktická se jeví úvaha o použití hlaviček Date a Last-Modified. Rozdíl hodnot uvedených v hlavičce Date a Last-Modified vyjadřuje dobu po kterou leží informace nezměněna se serveru. Jako rozumné se pak může jevit udržovat tuto informaci v paměti cache např. po 10% tohoto rozdílu.
![]()
15 SSL a TLS
Protokol
SSL (Secure Sockets Layer) vytvořila firma Netscape. Firma Microsoft vytvořila
obdobný protokol PCT. V praxi se ujal protokol SSL verze 3. Oficiálním
protokolem Internetu se však stal protokol TLS (RFC-2246: Transport Layer
Security protocol) vycházející z protokolu SSL verze 3 (z popisu
protokolu pochopíte, že se jedná o SSL verze 3.1). Protokol SSL verze 3 a
protokol TLS jsou si velice blízké, avšak klient TLS se nedomluví se serverem
SSL a opačně. Jak klient, tak server musí být konfigurovány buď pro podporu
protokolu SSL nebo protokolu TLS.Oba protokoly SSL i TLS používají architekturu
klient/server.Pro zajímavost stojí ještě uvést, že existuje obdoba protokolu
TLS pro technologii WAP mobilních telefonů označovaná jako WTLS (Wireless TLS). WTLS je přímo odvozeno od TLS, takže veškeré
principy popsané v této kapitole většinou platí též pro WTLS. Protokol
WTLS má i některá rozšíření. Např. může běžet i nad protokolem UDP.
Protokol
S/MIME řeší zabezpečení elektronické pošty na aplikační vrstvě. Protokoly
TCP/IP původně nikterak neřešily problematiku zabezpečení přenášených dat.
Klasický model protokolu TCP/IP v sobě nezahrnuje žádnou vrstvu, která by se
touto problematikou zabývala. Na obr. 15-1 je znázorněno vložení vrstvy SSL
(resp.TLS) do modelu protokolů TCP/IP. 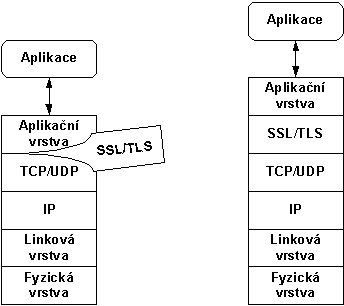
Obr. 15-1 Vrstva SSL (resp. TLS) se vkládá mezi aplikační vrstvu a protokol TCP
Vrstva
SSL (resp. TLS) řeší zabezpečení
přenášených dat; je vložena mezi aplikační protokol a protokol TCP. Vrstva SSL nikterak nezkoumá data, která
jsou jí zasílána aplikační vrstvou – prostě je zabezpečí a předá protokolu TCP.
Tj. vrstva SSL nerozpozná, zda-li zabezpečovaná data se skládají
z nějakých aplikačních relací.Vrstva SSL proto ani nemůže provádět
zabezpečení na úrovni aplikačních relací např. pomocí elektronického podpisu.
Prostě přebírá od aplikační vrstvy paket po paketu a zabezpečuje jednotlivé
pakety. U každého paketu je vrstva SSL schopna zajistit jeho privátnost
(šifrování), integritu dat a autorizaci dat (nikoliv elektronický podpis).
Autorizace dat se provádí na základě kontrolního součtu počítaného z dat a
sdíleného tajemství.Při navazování spojení vrstva SSL (resp. TLS) vždy provádí
autentizaci serveru. Autentizace klienta je volitelná. Jen pro zajímavost:
protokol WTLS umožňuje teoreticky navázat spojení i bez autentizace serveru (i
klienta).Komunikace protokolem SSL/TLS mezi klientem a serverem je plně
duplexní, tj. skládá se z komunikace od klienta na server a v opačném
směru ze serveru na klienta. To není nic překvapujícího, to je běžná vlastnost
protokolu TCP. Zajímavé je, že SSL/TLS používá pro každý směr komunikace jiné
symetrické šifrovací klíče a jiné tajemství pro výpočet kontrolního součtu.
Další zvláštností protokolů SSL/TLS je formát dat. Ten není ASCII (jedná se o
šifrovaná data), ale nejedná se ani o BER či DER kódování. Data protokolů jsou
v podstatě pevného formátu a popisují se jakýmsi intuitivním jazykem
vytvořeným jen pro účely těchto protokolů. My se nebudeme zabývat definicí
tohoto popisu, ale využijeme intuitivnost tohoto jazyka. Tj. je vcelku jasné,
co norma míní, pokud bychom však potřebovali danou informaci znát naprosto
přesně, pak je nutné sáhnout k RFC-2246. Tento intuitivní jazyk připomíná
jazyk C. Pro mne jediným zádrhelem bylo, že některé proměnné mohou mít proměnou
délku. Typickým případem je proměnná obsahující certifikát. V takovém
případě se na počátek přidává pole obsahující délku proměnné. Tj.
v případě certifikátu se certifikát kóduje do dvou polí: pole délky a
vlastní DER kódovaný certifikát, který v DER kódování opět obsahuje délku
(hned za typem)! Pole délka je tak dlouhé, jak nejdelší může být příslušná
položka. Prakticky např. pro certifikát 3 B. Další zajímavostí je termín
„elektronický podpis“, který zde není míněn ve smyslu zákona o elektronickém
podpisu; tímto termínem se zde míní:V případě
algoritmu RSA soukromým klíčem šifrovaná 36bitová struktura vzniklá ze dvou
kontrolních součtů podepisovaných dat. První kontrolní součet je pomocí
algoritmu SHA a druhý kontrolní součet je algoritmem MD-5.
V případě
algoritmu DSS se použije pouze kontrolní součet algoritmem SHA (20 bajtů).Přehled
vlastností SSL/TLS:
- SSL/TLS provádí autentizaci serveru zpravidla na základě certifikátu serveru.
- SSL/TLS může provést autentizaci klienta též na základě certifikátu klienta. Autentizace se neprovádí při komunikaci klienta s anonymním SSL/TLS serverem.
- Autentizace (autentizační dialog) se provádí za využití asymetrické kryptografie.
- Součástí úvodního dialogu je výměna dat, ze kterých se odvodí tzv. sdílené tajemství. Sdílené tajemství je blok čísel, který znají pouze účastníci komunikace (klient a server) a všem ostatním je utajen. Od sdíleného tajemství se odvozují symetrické šifrovací klíče a tzv. tajemství pro výpočet kontrolního součtu.
- SSL/TLS může šifrovat přenos dat mezi oběma účastníky komunikace. Pro šifrování se používá symetrická šifra, jejíž šifrovací klíč je odvozen od sdíleného tajemství.
- Jednotlivé přenášené fragmenty dat se doplňují o kontrolní součet zabezpečující integritu přenášených dat. Jelikož se kontrolní součet nepočítá pouze z fragmentu přenášených dat, ale fragment se pro výpočet kontrolního součtu zřetězí s tajemstvím pro výpočet kontrolního součtu, tak je velice obtížné poopravit přenášená data během přenosu. Tj. je zabezpečena integrita přenášených dat.
- SSL nevidí do aplikačních dat (SSL je nižší vrstva) v tom smyslu, že by SSL dokázalo rozeznávat v aplikačních datech jednotlivé transakce.
- SSL neprovádí elektronické podepisování jednotlivých přenášený fragmentů či transakcí. SSL tedy nelze využít pro aplikace vyžadující takovéto zabezpečení.
- SSL je možné použít pro všechny aplikace, které nevyžadují elektronické podepisování přenášených transakcí.
Často se setkáváme se zabezpečením protokolu HTTP pomocí vrstvy SSL, takového řešení se označuje jako protokol HTTPS (nezaměňovat s protokolem S-HTTP, což je jiný, dodnes málo běžný typ zabezpečení protokolu HTTP!).
Pro
pochopení funkce SSL je třeba se na tuto vrstvu podívat podrobněji. SSL se
skládá ze 4 dílčích protokolů:
- Protokol Record
Layer Protocol (RLP), který je z pohledu aplikačních protokolů
onou „vrstvou SSL“ (na obrázku 11-2 jsou jako aplikační protokoly uvedeny
protokoly LDAP a HTTP). Protokol RLP bere data od aplikačních protokolů,
šifruje je a počítá z přenášených fragmentů kontrolní součet. Druhý
účastník spojení protokolem RLP ověřuje kontrolní součet, dešifruje data a
předává je aplikačnímu protokolu.
Protokol RLP se nezabývá problémy jako je typ použitého šifrovacího algoritmu, stanovení šifrovacího klíče atd. Vše má připraveno protokolem HP v tzv. aktuální protokolové svitě a dalších parametrech zpracování. - Handshake protocol (HP) se z hlediska protokolu RLP tváří jako další aplikační protokol. Jeho pakety se balí do protokolu RLP. Protokolem HP si oba účastnící připraví protokolovou svitu (typ šifrovacího protokolu a protokol pro výpočet kontrolního součtu), dohodnou se na komprimačním algoritmu a vymění si data pro výpočet hlavního tajemství. Z hlavního tajemství se pak odvodí symetrické šifrovací klíče a sdílené tajemství pro výpočet kontrolního součtu (MAC secret). Protokol HP všechny tyto informace připraví nikoliv do aktuální svity, ale do tzv. připravované svity.
- Protokol Change Cipher Specification Protocol (CCSP) je velice jednoduchý protokol. Poté, co protokol HP připraví novou protokolovou svitu a všechna potřebná data pro činnost protokolu RLP, je třeba zkopírovat připravené parametry zpracování na aktuální parametry zpracování a začít šifrovat podle nových parametrů. Protokol CSP se skládá pouze z jediné zprávy „zkopíroval jsem připravovanou svitu na aktuální - nyní je šifrováno podle nové svity“.
- Dojde-li k jakémukoliv zádrhelu v komunikaci, pak je tu k dispozici Alert Protocol (AP), kterým jedna strana může signalizovat závadu druhé straně. AP lze s trochou nadsázky přirovnat k protokolu ICMP na vrstvě IP.
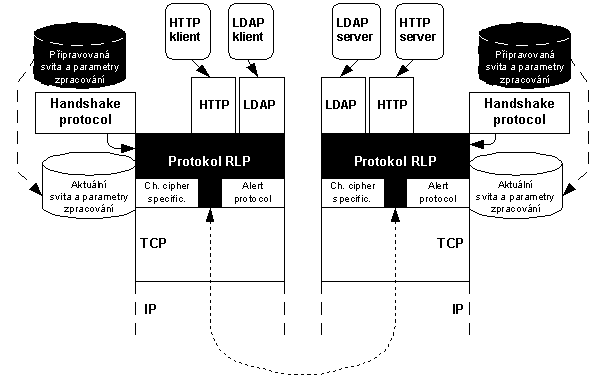
Obr. 15-2 Soustava protokolů SSL (resp. TLS)
Každá
strana komunikace (klient i server) tedy udržuje dvakrát některé parametry
komunikace ve svých datových strukturách. Jednou udržuje aktuální data
používaná protokolem RLP a podruhé připravovaná data protokolem HP. Klient se
serverem pro komunikaci zřizují tzv. relaci (session), relace může
zahrnovat jedno nebo více spojení (connection). Pro úplnost je třeba
ještě dodat, že mezi dvěma počítači může být současně zřízeno i více relací.
Klient i server ve svých strukturách udržují následující informace:
- Pro relaci:
- Identifikační číslo relace (session identifier) - až 32 bajtů dlouhé číslo jednoznačně identifikující relaci.
- Certifikát druhé strany (peer certificate).
- Komprimační algoritmus (compression metod) pro kompresi dat.
- Protokolovou svitu (cipher spec) specifikující symetrický šifrovací algoritmus a algoritmus pro výpočet kontrolního součtu.
- Sdílené tajemství (master secret), 48 bajtů známých pouze oběma účastníkům komunikace a utajované před ostatními uživateli sítě.
- Příznak, je-li možné relaci obnovovat (is resumable) nebo je nutné pokaždé navazovat novou relaci.
- Pro jednotlivá spojení:
- Náhodné číslo generované klientem (ClientRandom).
- Náhodné číslo vygenerované serverem (ServerRandom). Obě náhodná čísla jsou na počátku přenášena nezabezpečeně.
- Tajemství pro výpočet kontrolního součtu používané serverem (server write MAC secret).
- Tajemství pro výpočet kontrolního součtu používané klientem (client write MAC secret).
- Symetrický šifrovací klíč, kterým šifruje server (server write key).
- Symetrický šifrovací klíč, kterým šifruje klient (client write key).
- Inicializační vektory (IV) používané pro blokové šifry.
- Číslo přijaté a číslo odeslané zprávy.
Otázka je, jak se tajemství pro výpočet kontrolního součtu a symetrické šifrovací klíče stanoví. Přesný postup je popsán v příslušné normě. Zjednodušeně se postupuje tak, že se vytvoří blok klíčů (obr. 11-3) a z něj se postupně odsekává:
- sdílené tajemství pro výpočet kontrolního součtu pro komunikaci od klienta na server (client_write_MAC_secret),
- sdílené tajemství pro výpočet kontrolního součtu pro komunikaci ze serveru na klienta (server_write_MAC_secret),
- symetrický šifrovací klíč pro směr od klienta na server (client_write_key)
- symetrický šifrovací klíč pro směr ze serveru na klienta (server_write_key)
- inicializační vektory (clent_write_IV a server_write_IV).
Pokud se používá tzv. exportní software, který neumožňuje používat plnou délku šifrovacích klíčů, pak před použitím klíčů se použije procedura, která provede zmrzačení příslušných klíčů na požadovanou délku.
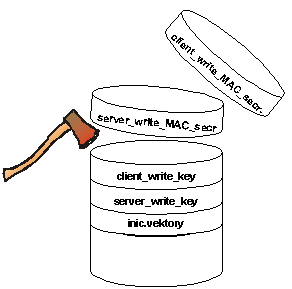
Obr. 15-3 Z bloku klíčů se postupně odsekávají sdílená tajemství pro výpočet kontrolního součtu, symetrické šifrovací klíče a případně inicializační vektory
Blok klíčů se vytvoří pseudonáhodnou funkcí, do které vstupuje:
- Tzv. hlavní tajemství.
- Náhodné číslo client_random generované klientem při navazování komunikace a přenášené sítí ve zprávě ClientHello v nezabezpečeném tvaru.
- Náhodné číslo server_random generované serverem při navazování komunikace a přenášené sítí ve zprávě ServerHello v nezabezpečeném tvaru.
Jádrem toho, že je blok klíčů znám pouze klientovi a serveru a nikomu jinému, je hlavní tajemství (master_secret), které se počítá pomocí pseudonáhodné funkce z tzv. předběžného tajemství (PreMasterSecret) a opět z náhodných čísel ClientHello a ServerHello.
Pseudonáhodná funkce je podrobně popsána v normách popisujících protokoly SSL a TLS. Je nutné upozornit, že pseudonáhodná funkce pro protokol TLS je mírně odlišná od pseudonáhodné funkce používané protokolem SSL. Pseudonáhodná funkce je použita proto, aby bylo obtížné předpovědět výsledek. Jedná se však o pseudonáhodnou funkci a nikoliv náhodnou funkci, protože ji klient i server aplikují na sobě nezávisle na stejná data a musí dospět k shodnému výsledku – jinak by nebyli schopni dešifrovat data druhé strany.
Opět bych mohl napsat, že jádrem tajemství je předběžné tajemství (PreMasterSecret). Předběžné tajemství generuje klient do zprávy ClientKeyExchangeMessage. Jeho generace závisí na použité asymetrické šifře. Existuje varianta jak jej určit v případě, že server používá certifikát s veřejným klíčem algoritmu RSA i pro případ, že server i klient používají Diffie-Hellmannův algoritmus (prakticky jsem se však s Diffie-Hellmannovým algoritmem při této komunikaci nesetkal).
V případě algoritmu RSA se to provede jednoduše. Klient vygeneruje dostatečně dlouhé náhodné číslo, které šifruje veřejným klíčem z certifikátu serveru, a výsledek (PreMasterSecret) předá serveru ve zprávě ClientKeyExchangeMessage.
Jinými slovy do výpočtu bloku klíčů vstupuje: veřejným klíčem serveru šifrované předběžné tajemství a náhodná čísla ClientHello a ServerHello, která jsou přenášena nezabezpečeně. Pokud je použit algoritmus RSA, pak stačí mít k dispozici pouze certifikát serveru, z něhož se využije veřejný klíč pro přenos zprávy ClientKeyExchangeMessage. V případě algoritmu RSA pro vybudování bezpečného kanálu, který zajišťuje privátnost i integritu přenášených dat není třeba certifikát uživatele. V případě, že se použije certifikát uživatele, pak se využije pouze k autentizaci uživatele vůči serveru a k ničemu jinému.
V případě, že se nevyužívá certifikát klienta, tak klient přistupuje na SSL/TLS server jako anonymní uživatel. Hovoříme pak o anonymním SSL/TLS serveru. Anonymní SSL/TLS server se vždy autentizuje klientovi za využití certifikátu serveru. Klient si je tedy jist, s jakým serverem komunikuje, kdežto z hlediska serveru se jedná o anonymního uživatele.
Když se použije anonymní SSL (resp. TLS) server, tak to ještě neznamená, že aplikační server využívající SSL/TLS komunikaci je anonymní. V anonymním SSL/TLS kanálu mezi klientem a serverem je možné provozovat na aplikační vrstvě např. HTTP (či POP3, IMAP4, LDAP apod.) server s autentizací pomocí jména uživatele a hesla. V tomto případě se jméno i heslo již přenáší zabezpečeným kanálem a padají veškeré možnosti odchycení hesla popsané v kapitole 3.
15.1
Record Layer protocol
Record layer protocol přebírá data od aplikačních protokolů a před tím, než je sám předá vrstvě TCP, tak provede:
- Rozsekání dat na fragmenty o délce menší než 214 B.
- Komprimaci dat, dohodli-li se na ní klient se serverem (pomocí HP protokolu).
- Výpočet kontrolního součtu algoritmem, na kterém se dohodli klient a server protokolem HP.
- Doplnění fragmentu o výplň na délku, která je násobkem délky šifrovacího bloku.
- Šifrování fragmentu (fragment mohl být před šifrováním komprimován).
- Doplnění hlavičky RLP protokolu před datový fragment.
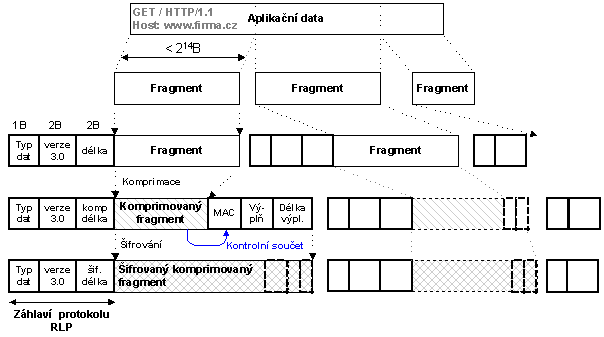
Obr. 15-4 SSL Record Layer Protocol (MAC = kontrolní součet)
Kontrolní
součet se nepočítá pouze z fragmentu (resp. komprimovaného fragmentu), ale
fragment se pro výpočet kontrolního součtu zřetězí s tajemstvím pro výpočet
kontrolního součtu (write_MAC_secret), které je utajované
podobně jako jsou utajovány symetrické šifrovací klíče. Chtěl-li by útočník
pozměnit obsah přenášeného fragmentu, pak k změněnému fragmentu není schopen
vypočítat (a podvrhnout) kontrolní součet neboť nezná tajemství pro
výpočet kontrolního součtu. Záhlaví RLP se skládá ze tří položek.
- Typu přenášených dat specifikujícího, jedná-li se o data aplikačního protokolu (např. HTTP) nebo o služební data vrstvy TLS/SSL, tj. data některého ze služebních protokolů tvořícího vrstvu SSL/TLS, tj. z protokolů HP, AP či CCSP. Typ dat je dlouhý 1 B.
- Verze, která se skládá ze dvou bajtů. V první bajt obsahuje verzi a druhý nějaké jemnější dělení. Prakticky se však můžeme setkat s hodnotami: 2.0 pro SSL verze 2; 3.0 pro SSL verze 3. a 3.1 pro TLS verze 1.
- Délky fragmentu, po jeho případné komprimaci a šifrování. Pole délka fragmentu je dlouhá 2 B (= 16 b). Tj. fragment by teoreticky mohl být dlouhý až 216 B. Ježe díky kompresi se fragment může teoreticky i prodloužit, tak je třeba jistá rezerva.
15.2 Handshake protocol (HP)
Protokol HP je jádrem SSL. HP zabezpečuje:
- Autentizaci serveru.
- Autentizaci klienta, ta je však obecně nepovinná. Při komunikaci s anonymním serverem (např. anonymním HTTPS serverem) se autentizace klienta neprovádí.
- Výměnu náhodných čísel a dat vedoucích k výpočtu sdíleného tajemství. Z nich se pak sestavuje špalek dat, ze kterého se odkrajují šifrovací klíče.
Komunikace v HP protokolu se skládá z tzv. zpráv. Rozeznávají se dva základní případy komunikace protokolem HP:
- Navazování nové relace, tj. server přiděluje nový identifikátor relace.
- Obnovení relace (použije se původní identifikátor relace). Tento případ je v podstatě zjednodušením předchozího případu,. tj. používají se jen některé zprávy.
Nadále se omezíme na popis podmnožiny protokolů SSL/TLS využívající k autentizaci certifikáty dle PKI s veřejnými klíči pro algoritmus RSA.
15.2.1 Zřízení nové relace
Zřízení nové relace (obr. 15-9) je proces, kdy dochází k autentizaci účastníků i k výměně všech dat potřebných pro výpočet hlavního tajemství.
Autentizace
serveru se provádí vždy. Autentizace klienta se provádí pouze v případě, že
server není anonymní. Zpráva ClientHello obsahuje nevyplněné identifikační
číslo relace. Identifikační číslo relace přiděluje server ve zprávě
ServerHello. Zprávy ClientHello a ServerHello obsahují náhodná čísla
ClientRandom a ServerRandom vstupující do procesu výpočtu sdíleného tajemství.
Dále klient nabídne podporované kryptografické algoritmy a server si ve zprávě
ServerHello z nich vybere. Server posílá klientovi svůj certifikát ve zprávě
Certificate (resp. může poslat řetězec certifikátů až ke kořenovému
certifikátu). Server může odeslat zprávu CerificateRequest, kterou žádá klienta
o jeho certifikát. Nakonec server odešle prázdnou zprávou ServerHelloDone,
kterou signalizuje klientu, že nyní je řada na něm, tj. očekává reakci klienta.
Klient v případě, že chce na server přistupovat neanonymně, odesílá serveru
svůj certifikát (resp. řetězec certifikátů). Dále následuje zcela klíčová
zpráva ClientKeyExchange. Tato zpráva obsahuje veřejným klíčem z certifikátu
serveru šifrované předběžné tajemství (PreMasterSecret), ze kterého se počítá
hlavní tajemství (master secret). Tím se také provede autentizace serveru. Podvržený
server, který k veřejnému klíči nevlastní odpovídající soukromý klíč, nemůže
získat správné PreMasterSecret (nedokáže jej dešifrovat). 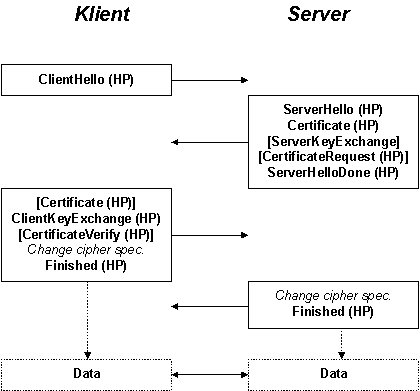
Obr. 15-9 Zřízení nové relace protokolem HP
Při
zjednodušeném výkladu principu SSL se často říká, že SSL používá pro šifrování
zpráv symetrickou šifru. Šifrovací klíč pro symetrickou šifru generuje klient.
Proto aby symetrický šifrovací klíč mohl klient bezpečně předat serveru po
nezabezpečeném Internetu, tak jej šifruje veřejným klíčem z certifikátu
serveru, tj. asymetrickou širou, a odešle serveru. Skutečnost
je ale taková, že takto vznikne pouze PreMasterSecret, ze kterého se spočítá
master_secret. Z master secret, ClientRandom a ServerRandom se spočte špalek
dat, ze kterého se teprve odsekávají šifrovací klíče. Takže nyní jak
klient, tak i server vzájemně znají své symetrické šifrovací klíče i tajemství
pro výpočet kontrolního součtu. Jak klient tak server používají každý své (tj.
každý jiné) šifrovací klíče i tajemství pro výpočet kontrolního součtu. V
případě, že klient přistupuje neanonymně na server, pak musí prokázat svou
totožnost, tj. identifikovat se. Klient prokazuje svou totožnost ve zprávě
CertificateVerify. Nejprve vytvoří kontrolní součet počítaný mj.
z hlavního tajemství (master_secret) a z obsahu všech zpráv od zprávy
ClientHello. Tento kontrolní součet je schopen vytvořit jen klient a server
(jen ti znají sdílené tajemství). Klient ve zprávě CertificateVerify odesílá
elektronický podpis z tohoto řetězce. Server si pak ověří totožnost klienta na
základě ověření (verifikace) tohoto elektronického podpisu. Závěr je pak již
zcela obdobný jako u obnovování spojení, tj. protokolem Change cipher
specification se signalizuje „přechod na nové šifrovací klíče“ a zpráva
Finished navazování spojení končí. Dále již běží přenos vlastních aplikačních
dat, který je šifrován. Každý RLP fragment obsahuje též kontrolní součet
zabezpečující integritu přenášených dat (už zprávy Finished byly
šifrovány).
15.2.2 Obnovení relace
Jednodušším případem komunikace mezi klientem a serverem je obnovení již dříve existující relace (obr. 15-10). Kdy se s takovým případem setkáváme? Obnovením se většinou nemyslí (i když se to nevylučuje) obnovení spojení např. po závadě na komunikačních linkách - to je záležitost nižšího protokolu, v našem případě protokolu TCP. Spíše se zde bude jednat o trochu jiný případ. Představte si, že si prohlížíte webové stránky na HTTPS serveru. Při vydání požadavku na stažení webové stránky musí být navázána relace. První stránka se skládala z celé řady objektů (textů, obrázků či zvuků), pro stažení každého z těchto objektu v protokolu HTTP/1.0 se navazuje samostatné spojení protokolem TCP. Po stažení všech objektů stránky se všechna TCP spojení uzavřou. (Pro úplnost dodejme, že v protokolu HTTP/1.1 je běžnější všechny objekty téže stránky stahovat jedním spojením.)
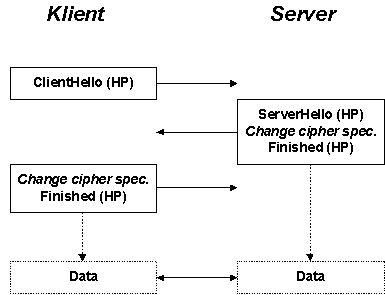
Obr. 15-10 Obnovení relace protokolem HP
Poté
si staženou webovou stránku prohlížíme na obrazovce. Během prohlížení není
navázáno žádné spojení - není ani jasné, zda-li budeme další informace
požadovat z téhož nebo jiného HTTPS serveru. V případě, že požadujeme další
stránku z téhož serveru, pak se pro stažení nových objektů navazují nová TCP
spojení a protokolem SSL (resp. TLS) se
tentokráte relace obnovuje. O tom, zda-li bude relace obnovována, rozhoduje
nastavení klienta (obnovuje se zpravidla pouze tehdy, pokud byl klientův
program ukončen a znovu nastartován - to lze však pravděpodobně změnit v
konfiguraci klienta). Při obnovování spojení klient odešle serveru zprávu
ClientHello. Zpráva ClientHello obsahuje náhodné číslo ClientRandom vstupující
do výpočtu sdíleného tajemství. Zejména však zpráva ClientHello obsahuje
identifikátor obnovované relace. Dále zpráva ClientHello obsahuje seznam kryptografických
algoritmů podporovaných klientem. Server odpovídá zprávou ServerHello
obsahující náhodné číslo ServerHello vstupující též do výpočtu sdíleného
tajemství. Zpráva ServerHello obsahuje opět identifikátor obnovované relace a
zejména kryptografické algoritmy, které si server vybral z těch, které klient
podporuje. V případě, že server zamítne obnovit relaci či si nevybere z
nabízených kryptografických algoritmů, pak server neodpoví zprávou ServerHello,
ale protokolem Alert a uzavře TCP-spojení. V případě, že server spojení
neuzavře, odešle protokolem Change cipher specification informaci, že „přešel
na nové šifrovací klíče“ a pošle zprávu Finished obsahující kontrolní součet ze
všech zpráv od zprávy ClinetHello. Klient už jen pošle potvrzující zprávu Change
cipher specification a Finished, kterými výměnu zpráv potvrdí. Dále již běží
přenos vlastních aplikačních dat, který je šifrován. Každý RLP fragment
obsahuje též kontrolní součet zabezpečující integritu přenášených dat (už
zprávy Finished byly šifrovány).
Nyní
si rozebereme jednotlivé zprávy podrobněji. Pro ilustraci použijeme zprávy,
které jsem opět odchytil na LAN pomocí MS Network Monitoru (nebudu však uvádět
již kompletní výpis z MS Network Monitoru).
15.3 SGC
Dnes, kdy pominula exportní omezení, tak SGC (Server Gated Cryptgraphy) ztrácí na významu. Jednalo se o to, že mimo území USA se exportoval pouze software, který byl kryptograficky zmrzačen tak, aby bylo možné tímto software využívat pouze šifry s omezenou délkou klíče. Použití delších klíčů bylo v tomto „exportním“ software zablokováno.
Odblokování je pak možné na základě speciálního certifikátu serveru. Princip pak spočívá v tom, že klient naváže komunikaci zprávou ClientHello a nabízí pouze zmrzačené šifry. Server odpoví zprávou ServerHello a zejména zprávou Certificate, kde uvede svůj certifikát (další zprávy až po ServerHelloDone jsou z našeho pohledu bezvýznamné). Klient si prohlédne certifikát a zjistí, že se serverem, kterému byl vydán takovýto certifikát, může komunikovat nezmrzačenými šiframi.
15.4 HTTPS (bezpečný web)
Pro aplikační protokol HTTP provozovaný přes SSL/TLS používáme URI schéma HTTPS. Je třeba si uvědomit, že se jedná o dvě vrstvy: SSL/TLS a aplikační vrstvu reprezentovanou protokolem HTTP. Na obou vrstvách se přitom provádí autentizace. Vrstva SSL/TLS provádí autentizaci za využití certifikátů, kdežto protokol HTTP provádí základní autentizaci např. jménem a heslem. Jelikož se jedná o dvě nezávislé vrstvy, tak může jednotlivé autentizace kombinovat
|
|
HTTP |
||
|
HTTPS |
|
Anonymní HTTP |
Jméno/heslo (neanonymní HTTP) |
|
Jen certifikát serveru (Anonymní HTTPS) |
Anonymní uživatel si je jist, s jakým serverem komunikuje. Hodí se např. pro distribuci software, ceníků, kurzovních lístků apod. |
Jméno a heslo je přenášeno bezpečným kanálem. Hodí se pro většinu komerčních aplikací, které používají neanonymní klienty a nechtějí klienty obtěžovat vydáváním certifikátů |
|
|
I certifikát
klienta (Neanonymní HTTPS) |
Hodí se pro nejnáročnější aplikace (např. v oblastí domácího bankovnictví). Snad jediným nedostatkem je, že SSL/TLS neprovádí elektronický podpis. |
Nesmyslná kombinace, protože bezpečnost na úrovni certifikátů se již použitím hesel nezvýší. |
|
Pokud provozujeme HTTPS server, pak máme dvě možnosti:
- Provozovat HTTPS server na samostatném portu TCP (nejčastěji 443/tcp). Klient se přímo hlásí na tento port SSL/TLS komunikací (komunikace protokolem HTTP je odmítnuta). Tento případ specifikuje RFC-2818. Důležité je, že webový server musí mít vydán příslušný certifikát serveru. Tento certifikát serveru je zvláštní v tom, že DNS jméno webového serveru se musí shodovat se jménem dNSName rozšíření certifikátu „Alternativní jméno předmětu“, nebo pokud bychom chtěli používat IP-adresu, pak ve stejném rozšíření musíme použít jméno iPAddress. Důležité je, že v jednom certifikátu těchto jmen může být více či může být použit znak hromadného výběru hvězdička (*); v takovém případě stačí, aby se shodovalo alespoň jedno jméno uvedené v certifikátu shodovalo s DNS jménem webového serveru. RFC-2818 vyzývá CA, aby upustily od používání DNS jména v předmětu certifikátu v relativním jedinečném jméně COMMON NAME. Prakticky však dnešní software podporuje „Alternativní jméno předmětu“ jen výjimečně a více alternativních jmen nebo snad hvězdičku nepodporuje vůbec.
- Provozovat např. na portu 80 HTTP server a v případě potřeby provést „protocol upgrade“ na použití vrstvy TLS. V tomto případě není potřeba ani speciální URI pro použití vrstvy TLS. Zajímavé je, že se v tomto případě ani nepřerušuje spojení protokolem TCP. Tento případ specifikuje RFC-2817. Dosud jsem se však nesetkal se software, který by „protocol upgrade“ podporoval.
![]()
17 Aplikace PKI v elektronickém bankovnictví přes Internet
Elektronické bankovnictví je již aplikací. Avšak velice významnou aplikací, která využívá protokoly popsané v této publikaci, ale i protokoly nové jako je protokol SET určený pro karetní operace přes Internet.
Elektronické bankovnictví je velice zajímavou aplikací proto, že je u nás prvním typem masově rozšířené aplikace využívající bezpečnou komunikaci přes Internet (resp. GSM).
17.1 HomeBanking, InternetBanking apod.
Cílem těchto úloh je poskytnout služby běžně poskytované na pobočkách bank blíže k uživateli. Tj. dotáhnout banku až domů, na pracoviště či dokonce mít svou bankou s sebou na cestách.
Právě pro tyto účely se jeví výhodný Internet jako přenosové médium. Obdobně se však používá i síť GSM pro GSMbanking či WAPbanking. Říkáme, že banka buduje jednotlivé kanály pro své elektronické bankovnictví (obr. 17-1). Internetový kanál pak zpravidla obsahuje HomeBanking a InternetBanking. GSM kanál obsahuje GSMbanking, WAPbanking a SMSbanking.
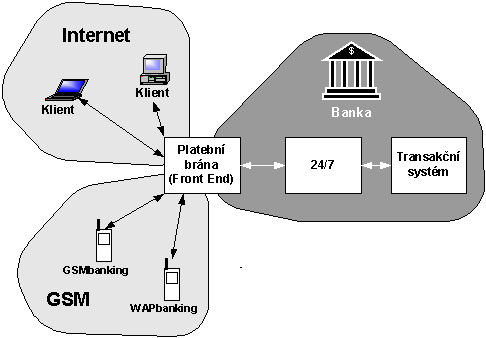
Obr. 17-1 Kanály elektronického bankovnictví
Rozdíl mezi InternetBankingem a HomeBankingem (někdy nazývaným též PCbankingem) je zpravidla v tom, že InternetBanking se výhradně orientuje na webový prohlížeč, kdežto HomeBanking využívá i vlastní aplikaci, ve které si klient může připravovat a archivovat své příkazy bance.
Obdobně rozdíl mezi a SMSbankingem je v tom, že GSMbanking používá šifrované SMS zprávy dle normy GSM 03.48, kdežto SMSbanking používá nešifrované (obyčejné) SMS zprávy, kde se autentizace klienta (resp. autorizace příkazu) provede např. pomocí jednorázového hesla generovaného autentizačním kalkulátorem.
Obdobně i WAPbanking není jednoznačným termínem, může se jednat o ne příliš bezpečný WAP bez použití WTLS, pak se zpravidla přistupuje přes Internet, či se použije bezpečný WAP; tj. WAP přes WTLS a pak by server měl běžet přímo na platební bráně.
Z našeho pohledu se ani příliš nemusíme zabývat jednotlivými bankovními aplikacemi jako takovými. Nemusíme se tedy zajímat, jak pracuje platební příkaz nebo jak pracují kapitálové či finanční trhy. Naším cílem je stávající aplikace banky modifikovat tak, aby byly alespoň částečně k dispozici klientovi v jeho prostředí.
Musíme vždy řešit dva problémy:
· Prvním problémem je, aby naše aplikace byla bezpečná, tj. aby neohrožovala samotnou banku. Bezpečnost se rozpadá na dva problémy:
o Bezpečnost propojení bankovních systémů s Internetem. Pro tyto účely je nejvhodnější Internetový FrontEnd, kterým jsme se zabývali v kap. 5. Použití firewallu je bezpečnostně přípustné pouze v případě, že banka neposkytuje OnLine služby, tj. bankovní systém vystavuje informace na server v DMZ; případně si z tohoto serveru bere dávky dat, které zpracovává, a výsledky opět vystavuje na server v DMZ.
o Bezpečnost komunikace klient-banka. Zde se řeší věčné dilema, zda použít pouze internetový prohlížeč, protože je to pro uživatele velice příjemné, či použít nějakou jinou aplikaci, která umožňuje elektronický podpis.
· Dalším problémem je, aby aplikace byla k dispozici 24 hodin denně, protože Internet (resp. GSM) se na rozdíl od poboček bank večer nezavírá. Klasické bankovní transakční systémy však většinou nejsou koncipovány pro nepřetržitý provoz, protože po pracovní době provádějí zúčtování banky. Proto se tyto systémy doplňují o nerůznější moduly 24/7, které pro kanály elektronického bankovnictví simulují činnost banky po pracovní době. Moderní bankovní transakční systémy (např. systém Phoenix) provádí již vše zcela OnLine, takže žádné dodatečné moduly již nepotřebují.
Jádrem práce, kterou musí vývojář takovéto aplikace odvést, je komunikace mezi klientem a bankou a zejména její zabezpečení. Má v podstatě k dispozici dvě možnosti (dva protokoly):
- Protokol HTTPS, tj. webový prohlížeč. Ten má však základní nevýhodu v tom, že sám nedokáže elektronicky podepisovat příkazy.
- Protokol CMS (resp. S/MIME), který se používá pro bezpečnou elektronickou poštu. Ten umí jak šifrovat, tak i elektronicky podepisovat. Je však určen pro elektronickou poštu či pro zabezpečení souboru např. na disketě. Tyto možnosti se používají zejména jako náhradní řešení pro případ, kdy není možná OnLine komunikace.
Výsledkem je zpravidla zkřížení obou možností. Provede se vždy na počátku analýza bankovních operací, jejímž cílem je zjistit, pro které operace je dostatečný protokol HTTPS a pro které už nikoliv – pro ty se pak musí použít elektronický podpis, tj. příkazy balit do zpráv CMS.
Může se provést i analýza rizik operací prováděných přes Internet, ze které s největší pravděpodobností vyjde, že např. zůstatky na účtu je možné provozovat přes HTTPS (přes prohlížeč) a platební příkazy jen do jisté výše.
Zbývá jediná věc, a to jak provést elektronický podpis příkazů, u kterých z analýzy vyšlo, že podepsány být musí. Zde jdou dvě řešení:
· Jít cestou samostatné aplikace (tj. nejít cestou webového prohlížeče). Tato aplikace vloží příkazy do CMS zprávy a odešle do banky. Toto řešení má výhodu v tom, že když už se taková aplikace vytváří, tak se doplní o další funkčnosti jako je příprava příkazů, import příkazů z podnikového informačního systému, export výpisů účtů do podnikového systému, různé tisky, rozbory apod. Výsledkem je pak HomeBanking (resp. PCbanking)
· Druhou cestou je použití webového prohlížeče a komponent (viz kap. 13) na bázi elektronicky podepsaných Java appletů či ActiveX komponent, které provedou elektronický podpis „přímo v prohlížeči“ před odesláním příkazu do banky. Výsledkem je pak InternetBanking.
Dalším problémem je, jakou zvolit autentizaci uživatele. Nabízí se nám několik možností:
- Použít osobní certifikát uživatele, což vyžaduje od uživatele jistou námahu spojenou s vystavením certifikátu, která může být klientovi kompenzována např. tím, že certifikát bude moci použít i např. v elektronické poště.
- Použít osobní certifikát na čipové kartě. Zde platí totéž co v předchozím bodu s tím, že je třeba navíc počítat s náklady na kartu a čtečku.
- Použít typy autentizace popsané v kap. 4. Zejména použití jednorázových hesel je sice pro uživatele pracnější než použití osobních certifikátů, ale má jednu nespornou výhodu: Lze jej využít i v případě, že klient chce spouštět bankovní aplikaci v prostředí kontrolovaném třetí stranou (např. v i-kavárně), kde použití osobního certifikátu (byť na kartě) je velice rizikové.
Jelikož banky mají nerůznější klienty, tak většinou časem dospějí k nabídce pokrývající všechny zmíněné možnosti. Osobně se mi jeví optimální volby např.:
- Jako primární možnost zvolit osobní certifikát a jako doplňkovou možnost jednorázová hesla zasílaná např. přes mobilní telefon.
- Nebo naopak primárně použít autentizační kalkulátory a osobní certifikáty jen pro klienty, kteří posílají větší objemy dat.
Aplikace HomeBanking, InternetBanking apod. lze použít nejenom pro komunikaci s bankou, ale také pro platbu ve virtuálních obchodních domech. Princip je jednoduchý: V okamžiku, kdy se dostavíte do pokladny virtuálního obchodního domu, tak si zvolíte jako platební metodu váš oblíbený *banking (použil jsem hvězdičku, abych popisoval všechny podobné aplikace najednou a nikoho neurazil). Pokladna vašemu webovému prohlížeči vrátí zprávu s hlavičkou:
Content-Type:
application/*banking
Kde řetězec „application/*banking“ si váš *banking asociuje se svou aplikací. Přijetím zprávy s touto hlavičkou dojde k aktivaci (probuzení) vašeho *bankingu, ve kterém vyplníte platební příkaz ve prospěch virtuálního obchodního domu za váš nákup.
Toto řešení není špatné, ale má však jednu nevýhodu – není univerzální. Pro každou banku musí mít pokladna virtuálního obchodního domu zvláštní ikonu (tedy ve skutečnosti naprogramovanou bránu). Pokud v pokladně nenajdete ikonu vašeho *bankingu, pak v něm nezaplatíte.
![]()
18 m-PKI
+ Sing Text
WAP
2.x – TCP* Profile
Mobilní
telefon nahrazující autentizační kalkulátor