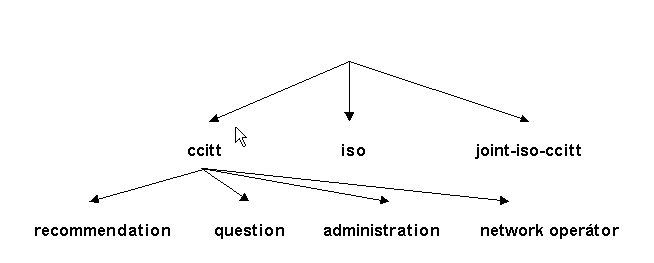
Na vrcholu klasifikačního stromu jsou samy normalizační úřady, protože jestliže se něco klasifikuje, pak nejprve musí být stanoveno kdo klasifikaci provádí. Nejvyššími položkami jsou ccitt, iso a joint-iso-ccitt (společně ISO a CCITT). Pod položkou ccitt jsou podřízené položky, které určuje CCITT, pod položkou iso jsou položky stanovované ISO a pod položkou joint-iso-ccitt jsou položky, které stanovuje ISO ve společně s CCITT.
ISO je tzv. registrační autorita podstromu začínajícího položkou iso, tj. registruje a je zodpovědná za objekty umístěné ve stromové struktuře pod položkou iso.
Registrační autorita (např. ISO) může delegovat pravomoci pro registraci objektů na registrační autoritu nižšší úrovně tak, že ji určí položku, pod kterou může registrovat své objekty. Mechanizmus je podobný mechanizmu přidělování subdomén v DNS.
Poznámka: termín registrační autorita nemá žádnou sovislost s termínem registrační autorita z kapitoly o certifikátech podle doporučení X.509.
Opět slovní vyjádření názvu jednotlivých položek je pouze vhodné pro komunikaci lidí. Norma ISO 8824 zavádí číselné označení jednotlivých položek. Čísla se uvádí v kulatých závorkách za názvem položky:
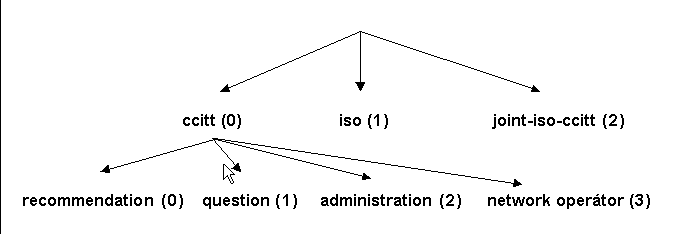
Položka je pak určena čísly všech položek, které vedou od kořene až k položce. Jednotlivé číslice se v textovém zápisu oddělují mezerou nebo tečkou. Např. položku question(1) můžeme zapsat jako {0.1}.
Ve většině případů je strom značně rozvětvený a cesta vede přes mnoho položek. Je možné do složených závorek napsat podstrom celé struktury. Jako první položka se ve složených závorkách pak napíše jméno položky tvořící kořen podstromu následované mezerou s číslem položky nižší úrovně.
Celý mechanizmus je názorně vidět na složitějším případě. Nejprve si však uveďme případ rozsáhlejišho stromu:
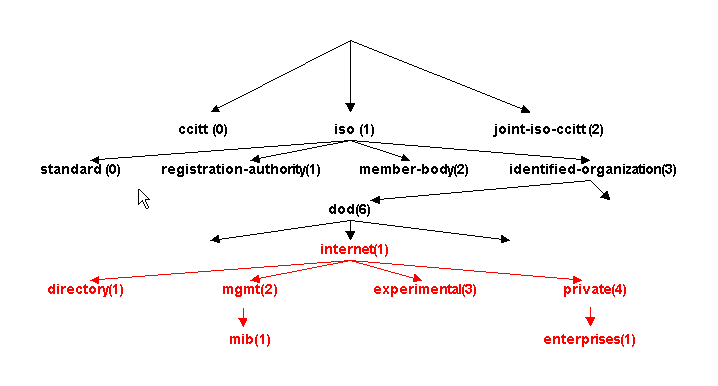
Položka internet(1) lze zapsat jako {iso(1) org(3) dod(6) 1} nebo jako {1.3.6.1}- názvy jsou nadbytečné. Dokonce i na předchozím obrázku je uvedeno identified-organization(3) a v zápisu org(3) a význam je stejný - podstatná je trojka.
Nové objekty se definují pomocí operátoru ::= . Např. objekt internet se definuje:
internet OBJECT IDENTIFIER ::= {iso org(3) dod(6) 1}
nebo jednodušeji:
internet OBJECT IDENTIFIER ::= {1.3.6.1}.
Další objekty lze definovat už i za využití podstromu. Např.:
directory OBJECT IDENTIFIER ::= {internet 1}
mgmt OBJECT IDENTIFIER ::= {internet 2}
mib OBJECT IDENTIFIER ::= {mgmt 1}
atd.
Cvičení: Nakreselete si strom pro položky:
pkcs-7 OBJECT IDENTIFIER ::= {iso(1) member-body(2) US(840) rsadsi(113549)
pkcs(1) 7}
signedData OBJECT IDENTIFIER ::= {pkcs-7 2}
envelopedData OBJECT IDENTIFIER ::= {pkcs-7 3}
Identifikace objektu rsadsi vyjádřená ve složených závorkách je tedy {1.2.840.1135949}. Při konverzi do BER se jiným způsobem konvertují první dvě čísla jiným ostatní:
Příklad: Číslo 1135949:
113549 = 06 x 1282 + 7716 x 1281+
0D16 x 1280 což by se dalo zapsat jako 06 77
0D jenže k prvním a druhému bajtu nesmíme zapomenou připočíst šestnáctkově
80, protože to nejsou poslední bajty čísla. Takže výsledek 86
F7 0D.
Příklad: Vyjádřete v BER identifikátor objektu {1 2 840 1135949}:
Cvičení: Vyjádřete v BER identifikátor
objektu {1.3.6.1.2.1.1.1}, tj. objekt sysDescr používaný protokolem SNMP.
(je to jednoduché protože není třeba nic počítat modulo 128) Výsledek se
opět prověřte konvertorem. Dostanete:
OBJECT
:1 3 6 1 2 1 1 1
06 07 2b 06 01 02 01 01 01
Poznámka: Identifikátor objektu identifikuje objekt, tj. např. identifikátor sysDescr identifikuje objekt "popis počítače". Jenže konkrétní počítač má své jméno např. "AlphaServer ...". V praxi je tedy třeba svázat objekt s nějakým typem, který naplní objekt obsahem. I hovorově řekneme: "počítač: AlphaServer".
V ASN.1 se pro svázání objektu s jeho obsahem zpravidla používá typ
SEQUENCE. Např.
SEQUENCE {
sysDescr OBJECT IDENTIFIER,
popis
OCTED STRING}
V kódování BER si odvoďte popis pro tuto sekvenci jako cvičení (výsledek
jsem si oveřil v konvertoru):
SEQUENCE
30 16
OBJECT
:1 3 6 1 2 1 1 1
06 07 2b 06 01 02 01
01 01
OCTET STRING
:AlphaServer
04 0b 41 6c 70 68 61
53 65 72 76 65 72
Na následujících příkladech ukážeme jak se nové typy odvozují.
Příklad A: Určete typy pro šířku, výšku a hloubku tak,
aby byly platné v rámci vaší firmy (tj. zavádíme privátní typ). Jako tágy
si zvolte čísla 1 (výška), 2 (šířka) a 3 (hloubka).
Takže jedná se o privátní typy (+ C016) jednoduché dále
nestrukturované typy (+ 0) plus příslušný tág, takže dostaneme C1, C2 a
C3.
Příklad B: V kódování BER zapište podle předchozího příkladu předmět vyskoký 1, šíroký 2 a hluboký 1.
Výsledkem bude 30 09 c1 01 01 c2 01 02 c3 01 01 (ověřeno konvertorem):
SEQUENCE
30 09
priv [ 1 ]
c1 01 01
priv [ 2 ]
c2 01 02
priv [ 3 ]
c3 01 01
Zápis priv [1] znamená, že se jedná o typ třídy PRIVATE s tágem 1.
U takto definovaných typů musí příjemce vědět, že typ C1 je odvozen od typu INTEGER (nikde uvnitř nově zavedeného typu není původní typ INTEGER nikterak zakódován). Takto definové typy se nazývají implicitně odvozené typy.
U expicitně odvozených typů je navíc uvedeno z jakého typu je odvozen. Jedná se tedy o složený (konstruovaný) typ obsahující jednu položku, ale ta se skládá z pole typu, pole délky a pole dat.
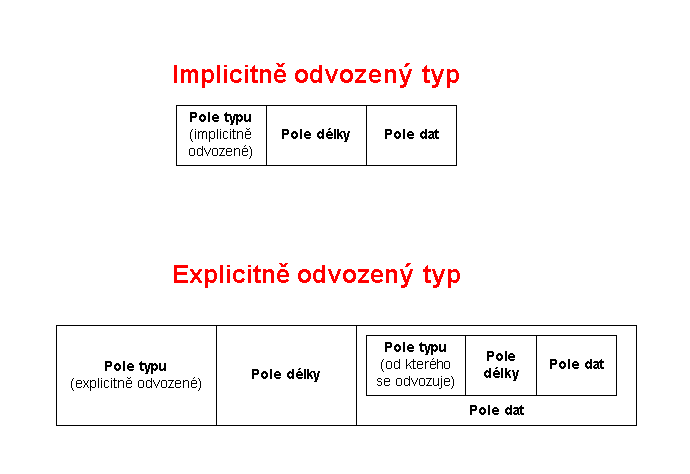
Příklad A (obdoba pro explicitně odvozené typy): Jelikož
explicitně odvozený typ je typem konstruovaným, tak nesmíme zapomenou přičíst
šestnáctkově 20.
Výška bude mít typ C016 (privátní třída) plus 2016
(konstruovaný typ) plus 1 (výška), tedy E1. Obdobně šířka E2 a hloubka
E3.
Příklad B (obdoba pro explicitně odvozený typ): Nyní musíme každý rozměr popsat samostatně. Např. výška:
Výsledek (ověřeno konvertorem):
SEQUENCE
30 0f
priv [ 1 ]
e1 03
INTEGER
:01
02 01 01
priv [ 2 ]
e2 03
INTEGER
:02
02 01 02
priv [ 3 ]
e3 03
INTEGER
:01
02 01 01
V ASN.1 je syntaxe odvozených typů vyjádřena následujícím přiřazením:
ImplicitniOdvozenyTyp ::= [třída tág] IMPLICIT typ
resp.
ExplicitniOdvozenyTyp ::= [třída tág] EXPLICIT typ
Je třeba si uvědomit, že dvojice třída flág se kóduje do jednoho bajtu (třída je v prvních dvou bitech). V případě, že není třída specifikována, pak se myslí třída content-specific.
Přímo v doporučení X.209 je velice pěkný příklad, na kterém je pěkně
ilustrována syntaxe:
| Mějme definovány následující typy:
Type1 ::= VisibleString
Hodnota řetězce je: "Jones" (4A6F6E657316) V BER dostaneme: Type1:
|
Např. v normě PKCS#7 se zavádí struktura
ExtendedCertificateOrCertificate :== CHOICE {
certificate Certificate,
extendedCertificate [0] IMPLICIT ExtendedCertificate
}
Tím se chce říci, že struktura ExtendedCertificateOrCertificate
je
buď
certificate Certificate
nebo
extendedCertificate [0] IMPLICIT ExtendedCertificate
(buď certifikát podle X.509 verze 1 nebo podle X.509 verze 3). Jenže
příjemci je nutné sdělit, jaký typ certifikátu je mu posílán, takže v případě
certifikátu verze 1 je poslán samotný certifikát a v případě rozšířeného
certifikátu (verze 3) je rozšířený certifikát předcházen nulou (třída content-specific,
tág nula, tj. "80 délka datové_pole", kde datové_pole je certifikát
verze 3).
Z hlediska kódování BER, ANY se CHOICE nikterak nekóduje, protože se
vždy kóduje pouze alternativa, která je vybrána.
Příklad opět z certifikátu X.509:
AlgorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
parametrs ANY DEFINED BY algorithm OPTIIONAL}
V příkladu se chce vyjádřit, že identifikátor parametrs může
nabývat jakýchkoliv typů. Ovšem ne zcela jakýchkoliv, ale jen těch, které
jsou definovány při definici identifikátoru algorithm. Slovo OPTIONAL
specifikuje, že některé algoritmy nemusí mít parametr žádný, tj. identifikátor
parametrs
pak nabývá typu NULL.