9 Protokol TCP (Transmision Control Protocol)

Protokol TCP je spojovanou
službou (connection oriented),
tj. službu která mezi dvěma aplikacemi naváže spojení – vytvoří na dobu
spojení virtuální okruh. Tento okruh je plně duplexní (data se přenášejí
současně na sobě nezávisle oběma směry). Přenášené bajty jsou číslovány.
Ztracená nebo poškozená data jsou znovu vyžádána. Integrita přenášených
dat je zabezpečena kontrolním součtem.
Konce spojení (“odesilatel”
a “adresát”) jsou určeny tzv. číslem portu. Toto číslo je dvojbajtové,
takže může nabývat hodnot 0 až 65535. U čísel portů se často vyjadřuje
okolnost, že se jedná o porty protokolu TCP tím, že se za číslo napíše
lomítko a název protokolu (tcp). Pro protokol UDP je jiná sada portů něž
pro protokol TCP (též 0 až 65535), tj. např. port 53/tcp nemá nic společného
s portem 53/udp.
Cílová aplikace je v Internetu
adresována (jednoznačně určena) IP-adresou, číslem portu a použitým protokolem
(TCP nebo UDP). Protokol IP dopraví IP-datagram na konkrétní počítač. Na
tomto počítači běží jednotlivé aplikace. Podle čísla cílového portu operační
systém pozná které aplikaci má TCP-segment doručit.
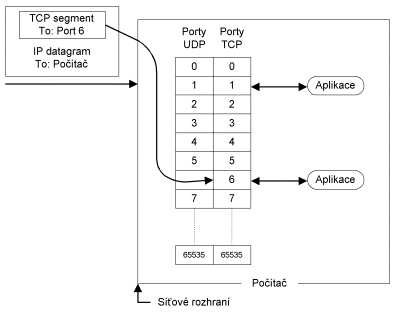
Obr. 9.1 Porty TCP a UDP
Základní jednotkou přenosu
v protokolu TCP je TCP segment.TCP segment se vkládá do IP-datagramu. IP-datagram
se vkládá do linkového rámce. Použije-li se příliš velký TCP-segment, který
se celý vloží do velkého IP-datagramu, který je vetší než maximální velikost
přenášeného linkového rámce (MTU), pak IP protokol musí provést fragmentaci
IP-datagramu (viz obr 9.2).
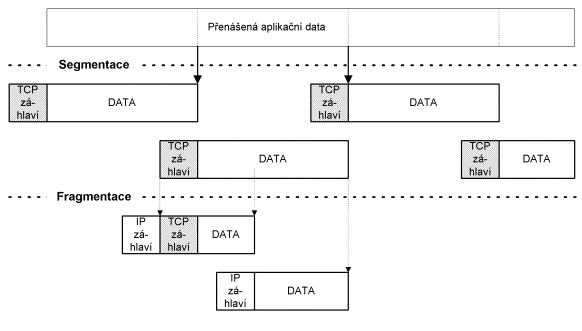
Obr. 9.2 Segmentace a fragmentace
TCP segment
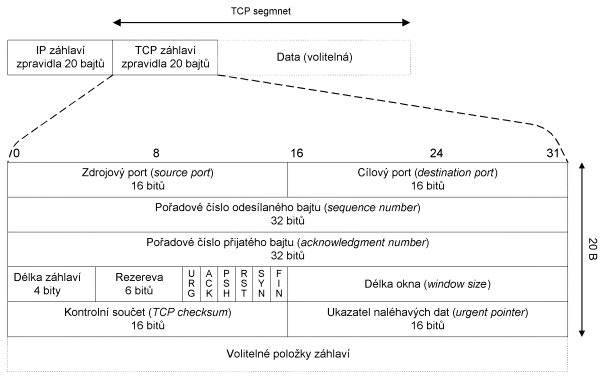
Obr. 9.3 TCP segment
Zdrojový port (source port) je port odesilatele
TCP segmentu, cílový port (destination port) je portem
adresáta TCP segmentu. Pětice: zdrojový port, cílový port, zdrojová IP-adresa,
cílová IP-adresa a protokol (TCP) jednoznačně identifikuje v daném okamžiku
spojení v Internetu.
TCP segment je část z toku
dat tekoucích od odesilatele k příjemci. Pořadové číslo odesílaného
bajtu je pořadové číslo prvního bajtu TCP segmentu v toku dat od odesílatele
k příjemci (TCP segment nese bajty od pořadového čísla odesílaného bajtu
až do délky segmentu). Tok dat v opačném směru má samostatné (jiné) číslování
svých dat. Jelikož pořadové číslo odesílaného bajtu je 32 bitů dlouhé,
tak po dosažení hodnoty 232-1
nabude cyklicky opět hodnoty 0. Číslování obecně nezačíná od nuly (ani
od nějaké určené konstanty), ale číslování by mělo začínat od náhodně zvoleného
čísla. Vždy když je nastaven příznak SYN, tak operační systém odesilatele
začíná znovu číslovat, tj. vygeneruje startovací pořadové číslo odesílaného
bajtu, tzv. ISN (Initial Sequence Number).
Naopak pořadové
číslo přijatého bajtu vyjadřuje číslo následujícího bajtu, který je
příjemce připraven přijmout, tj. příjemce potvrzuje, že správně přijal
vše až do pořadového čísla přijatého bajtu mínus jedna.
Délka záhlaví vyjadřuje
délku záhlaví TCP segmentu v násobcích 32 bitů (4 bajtů) - podobně jako
u IP-záhlaví.
Délka okna vyjadřuje
přírůstek pořadového čísla přijatého bajtu, který bude příjemcem ještě
akceptován (viz kapitola 9.7).
Ukazatel naléhavých dat
může být nastaven pouze v případě, že je nastaven příznak URG. Přičte-li
se tento ukazatel k pořadovému číslu odesílaného bajtu, pak ukazuje na
konec úseku naléhavý dat. Odesilatel si přeje, aby příjemce tato naléhavá
data přednostně zpracoval. Tento mechanismus používá např. protokol Telnet.
V poli příznaků mohou být
nastaveny následující příznaky:
-
URG – TCP segment nese naléhavá data.
-
ACK – TCP segment má
platné pole “Pořadové číslo přijatého bajtu” (nastaven ve všech segmentech,
kromě prvního segmentu, kterým klient navazuje spojení).
-
PSH – Zpravidla se používá
k signalizaci, že TCP segment nese aplikační data, příjemce má tato data
předávat aplikaci. Použití tohoto příznaku není ustáleno.
-
RST – Odmítnutí TCP spojení.
-
SYN – Odesílatel začíná
s novou sekvencí číslování, tj. TCP segment nese pořadové číslo prvního
odesílaného bajtu (ISN).
-
FIN –
odesilatel ukončil odesílání dat. Pokud bychom použili přirovnání k
práci se souborem, pak příznak FIN odpovídá konci souboru (EOF). Přijetí
TCP segmentu s příznakem FIN neznamená, že v opačném směru není dále možný
přenos dat. Jelikož protokol TCP vytváří
plně duplexní spojení, tak příznak FIN způsobí jen uzavření přenosu dat
v jednom směru. V tomto směru už dále nebudou odesílány TCP segmenty obsahující
příznak PSH (nepočítaje v to případné opakovaní přenosu).
V dalším textu budeme kombinaci nastavených
příznaků zapisovat podle prvních písmen z názvu příznaku. Pokud je příznak
nenastaven, pak místo něj napíšeme tečku. Např. skutečnost, že TCP segment
má nastaven příznaky ACK a FIN a ostatní příznaky nenastaveny zapíšeme:
.A…F .
Kontrolní součet
IP-záhlaví se počítá pouze ze samotného IP-záhlaví.
Z hlediska zabezpečení integrity přenášených dat je důležitý kontrolní
součet v záhlaví TCP-segmentu počítaný i z přenášených dat. Tento kontrolní
součet se počítá nejen ze samotného TCP segmentu, ale i z některých
položek IP-záhlaví. Kontrolní součet vyžaduje sudý počet bajtů, proto v
případě lichého počtu se data fiktivně doplní jedním bajtem na konci.
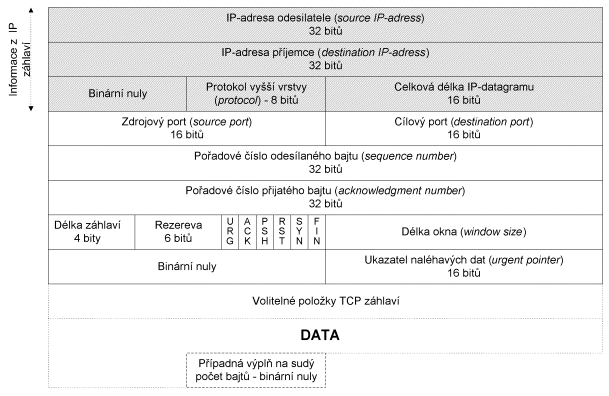
Obr. 9.5 Pole ze kterých
se počítá kontrolní součet TCP záhlaví
Kontrolní součet se počítá
z polí znázorněných na obrázku 9.5. Tato struktura slouží pouze pro výpočet
kontrolního součtu – v každém případě se žádná takováto struktura nepřenáší
Internetem! Někdy se tato struktura označuje jako pseudozáhlaví.
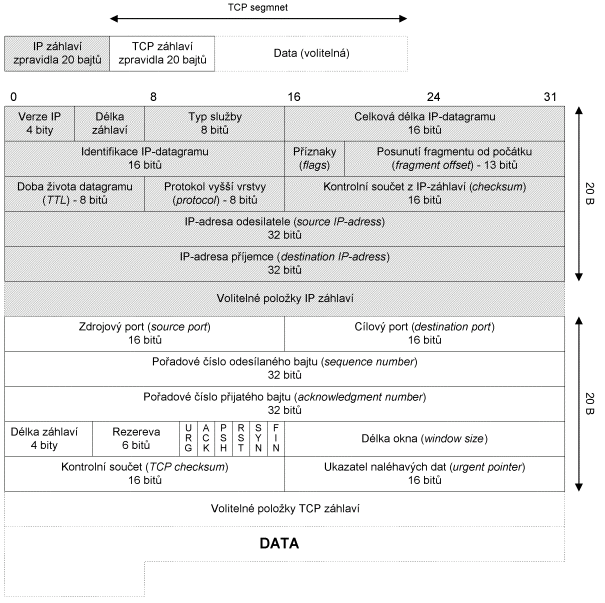
Obr. 9.6 IP a TCP záhlaví
Volitelné položky TCP záhlaví
Povinné položky TCP záhlaví
tvoří 20B. Za povinnými položkami následují volitelné položky.
Volitelná položka se skládá
z typu volitelné položky, délky volitelné položky a hodnoty. Délka TCP
záhlaví musí být dělitelná čtyřmi. V případě, že délka záhlaví by nebyla
dělitelná čtyřmi, pak se záhlaví doplňuje prázdnou volitelnou položkou
– NOP.
Jelikož pole délka záhlaví
je pouze 4 bity dlouhé, tak toto pole může nabývat maximálně hodnoty 11112=
1510. Délka záhlaví se
udává v násobcích čtyř, tudíž záhlaví může být dlouhé maximálně 15x4=60
bajtů. Povinné položky zaberou 20 bajtů, takže na volitelné zbývá nejvýše
40 bajtů.
Některé volby TCP záhlaví
včetně jejich struktury jsou uvedeny na obrázku 9.7.
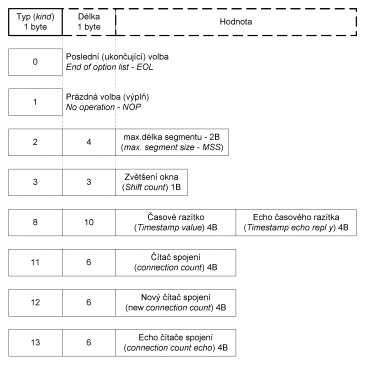
Obr. 9.7 Některé volitelné
položky TCP záhlaví
Navázání a ukončení spojení protokolem
TCP
Jádrem protokolu IP byl
zejména popis IP-datagramu. Jelikož je protokol IP datagramovou (nespojovanou
službou), tak se protokol IP příliš nepotřeboval zatěžovat případy, kdy
IP-datagram není doručen. IP protokol takové stavy může nanejvýš signalizovat
protokolem ICMP. Signalizace protokolem ICMP je pouze dobrou vůlí protokolu
IP. V praxi se setkáváme s mnoha případy, kdy signalizace pomocí protokolu
ICMP je potlačována, protože je nežádoucí - např. z bezpečnostních
důvodů.
Protokol TCP využívá k transportu
dat Internetem protokol IP, avšak nad tímto protokolem zřizuje spojovanou
službu. Musí řešit problémy navázání a ukončení spojení, potvrzování přijatých
dat, vyžádání ztracených dat, ale také problémy průchodnosti přenosové
cesty. Popis TCP segmentu je tedy jen malou částí TCP protokolu, podstatně
rozsáhlejší částí je popis výměny TCP segmentů (handshaking)
mezi oběma konci TCP spojení.
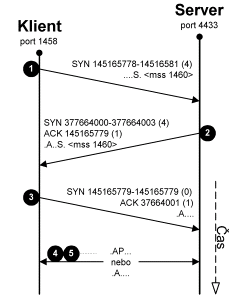
Obr. 9.8 Navazování spojení
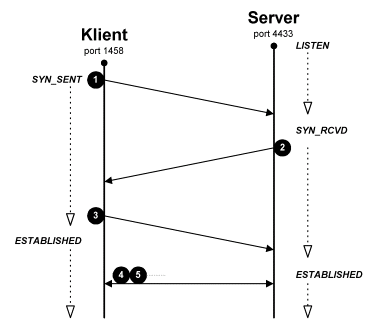
Obr. 9.9 Stavy při navazování
spojení
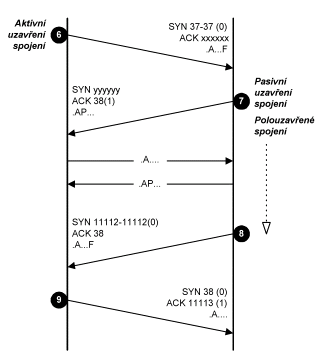
Obr. 9.10 Ukončování
spojení
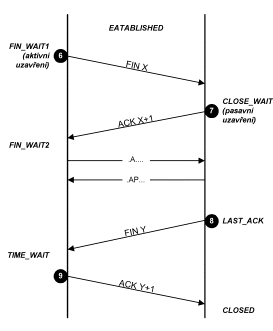
Obr. 9.11 Stavy při uzavírání
spojení
Technika zpoždění odpovědi
Interaktivní aplikace jako telnet
či příkazový kanál FTP jsou komplikované tím, že jsou interaktivní. Tzn.,
že zmačknete-li na klávesnici klávesu A, znak A se zabalí do TCP segmentu
(20+1=21 B), TCP segment se vloží do IP-datagramu (20+21=41 B) a tento
IP-datagram pak putuje Internetem jako segment (1) na obr. 9.12 až doputuje
na server (vše se pochopitelně ještě vkládá do linkových rámců od směrovače
ke směrovači). Server:
-
Jednak potvrdí příjem znaku,
tj. pokud nemá žádná data k odeslání, ta vyšle nedatový segment
(40 B) – segment (2).
-
Jednak předá znak A ke zpracování
serveru, server musí vyslat znak A zpět – segment (3), aby klientův software
zobrazil znak A na obrazovce klienta (provedl echo). Echo je nutné právě
pro subjektivní pocit interaktivnosti aplikace. Klient příjme echo (znak
A) a
-
zobrazí jej na obrazovce
-
potvrdí příjem echa serveru
segmentem (4). Pokud nemá žádná další data k odeslání, pak potvrzení provede
nedatovým TCP segmentem.
Pokud by takto aplikace pracovala, pak
zmáčknutí jedné klávesy znamená přenést 81 B v každém směru (nezapočítávaje
režii linkové vrstvy). 81 B se skládá z 41 B při odeslání znaku a 40 B
při jejich potvrzení. Na následujícím obrázku je tato situace vyznačena
pro stisk kláves A a H (začátek řetězce AHOJ).
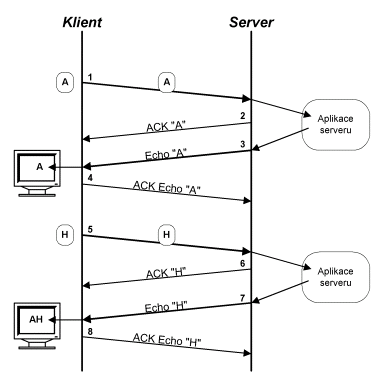
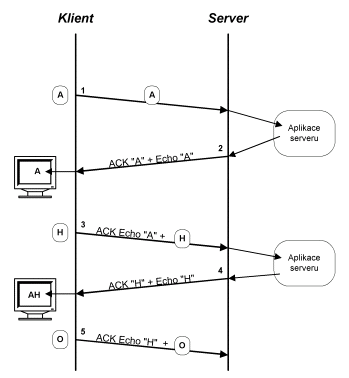
Obr. 9.12 Stisk kláves A a H
Je vcelku pochopitelné, že
je snaha objem přenášených dat zmenšit, čímž se snažíme zabránit ucpání
přenosových cest. Myšlenka spočívá v tom, že potvrzování přijatých dat
nebude probíhat okamžitě, ale se zpožděním. Během tohoto zpoždění se pak
mohou objevit i další data k přenosu.
Princip spočívá v tom, že
operační systém spustí pro tento účel hodiny zpravidla s tikem 200 ms (délka
tiku musí být pod 500 ms). Po každém tiku systém zkontroluje, zda-li není
něco k odeslání (potvrzení přijatých dat či odeslání dat). Pokud je třeba
něco odeslat, pak vše odešle najednou.
Na obrázku 9.13 server přijal
znak A – segment (1), ale bude odpovídat až s dalším 200 ms tikem. Do té
doby aplikace stihne i připravit data k odeslání (echo A). Operační systém
jedním TCP segmentem (segment (2)) provede potvrzení znaku A a zároveň
odešle echo A.
Jenže je již málo pravděpodobné,
že klient stiskne další klávesu H tak aby software klienta byl schopen
znak H odeslat společně s potvrzením přijetí echa klávesy A. Proto jak
je z následujícího obrázku patrné klient provede potvrzení echa klávesy
A pomocí segmentu (3) a stisk klávesy H způsobí vyslání dalšího TCP segmentu
(4).
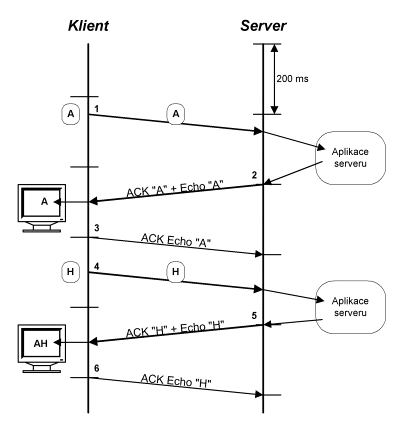
Obr. 9.13 Zpoždění 200
ms
V ideálním případě dojde
k redukci přenášených TCP segmentů ze čtyřech na tři. Ještě větší úspory
přinese použití Nagleova algoritmu znázorněného na obrázku 9.14.
Obr. 9.14 Nagleův algoritmus
V tomto případě software
klienta nečeká na další tik (200 ms), ale čeká až dojdou nějaká data od
protější strany. Tento algoritmus vyrovnává dobu odezvy vůči kapacitě přenosové
linky (řídí tok dat). Tj. je-li linka více zatížena, pak je na ní delší
odezva a odpověď se také pozdrží.
Technika okna
Nyní je naším problémem
případ, kdy klient potřebuje odeslat velké množství dat. Klient (resp.
Server) může odesílat data druhé straně aniž by jejich příjem měl potvrzen
až do tzv. okna (Window – zkratkou WIN).
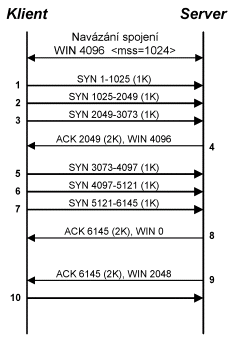
Představme si (obr. 9.15),
že klient se serverem navázal spojení a vzájemně se dohodli na maximální
velikosti segmentu (MSS) o velikosti 1K (tj. 1024 B) a vzájemné velikosti
okna 4K (tj. 4096B).
Obr. 9.15 Technika okna
Klient začne s odesíláním
dat, odešle segmenty 1, 2 a 3. Poté obdrží od serveru potvrzení (4), které
potvrzuje segmenty 1 a 2. Klient v zápětí odesílá segmenty 5, 6 a 7. Jenže
server data mezitím nedokázal zpracovat a data mu zaplnila vyrovnávací
paměť, proto segmentem 8 sice potvrdí příjem segmentů 3, 5, 6 a 7, ale
zároveň klientovi uzavře okno, tj. klient nemůže s odesíláním dat pokračovat.
Poté co server zpracuje část dat (2 KB), tak umožní klientovi pokračovat
v odesílání, ale neotevře mu segmentem
9 okno celé – pouze 2KB, protože všechna data ve vyrovnávací paměti ještě
nezpracoval a pro více dat nemá místo.
Obr. 9.16 Okno
Zahlcení sítě
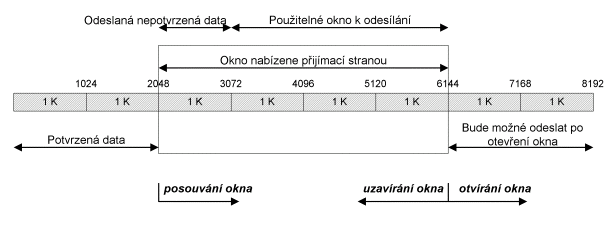
Okno je množství dat, které
je schopen přijmout příjemce. Okno je také příjemcem inzerováno. Problém
je však také na straně odesilatele. Pokud je odesilatel na rychlé síti
a příjemce na pomalé síti, tak by odesilatel mohl doslova nacpat do sítě
data až do velikosti okna (předpokládáme, že velikost okna by byla
shodou okolností značně velká). Jelikož síť by nebyla schopna toto velké
množství dat přenést, tak by došlo k zahlcení sítě a data, která síť není
schopna přenést zahodí. Směrovače ukládají IP-datagramy do vyrovnávací
paměti, ale i ta je omezená.
Obr. 9.17 Zahlcení
Ztráta dat je vždy nepříjemná.
Snahou je se ztrátě dat vyhnout. Na straně odesilatele se proto také zavádí
okno. Toto okno se snaží specifikovat, kolik může odesilatel odeslat nepotvrzených
dat aniž by došlo k zahlcení sítě. Toto okno na straně odesilatele se anglicky
nazývá Congestion Window (zkratkou
CWND). Odesilatel postupně zvyšuje CWND. CWND však nelze zvyšovat neomezeně.
Hranice za kterou už je větší pravděpodobnost zahlcení se označuje SSTHRESH.
Internet však budeme chtít využívat maximálně, tj. budeme chtít najít největší
použitelné CWND (to bude někde nad SSTHRESH). SSHTRESH má smysl udržovat
pouze v násobcích velikosti odesílaného segmentu (MSS).
Odesilatel odesílá vždy jen
takové množství nepotvrzených dat, které nepřevyšuje okno inzerované příjemcem
(WINDOW) ani nepřevyšuje CWND, tj. odesílá jen nejvýše min(WINDOW,CWND)
nepotvrzených dat.
Pomalý start
Otázkou je jak určit maximální
možné CWND. To odesilatel určuje dynamicky. Nejprve odešle jeden segment
a vyčká na jeho potvrzení. Pokud potvrzení obdrží, pak vyšle dva segmenty.
Pokud potvrzení obdrží, pak odešle čtyři atd. Jedná se o řadu 2n(která
je exponenciální).

Obr. 9.18 Pomalý start
Pochopitelně, že po několika
krocích se odesilatel dostane do situace, kdy síť zahltí a potvrzení nedostane,
tj. musí opakovat odesílání segmentů, protože se segment ztratil. V takovém
okamžiku se CWND zmenší na polovinu a tato hodnota se také nastaví do veličiny
SSTHRESH (pokud by SSTRESH mělo být menší než dva segmenty, pak se nastaví
na velikost dvou segmentů).
Je třeba rozlišovat jakým
způsobem byl zjištěn stav, že segment nebyl potvrzen. Nyní jsme předpokládali,
že se segment po cestě k příjemci ztratil. Příjemce segment nedostal a
tak stále potvrzuje předchozí (přijatý) segment. Po třech zopakovaných
potvrzeních předchozího přijatého segmentu se segment považuje za ztracený
a odesilatel jej opakuje. Může však nastat situace, že odesilatel ve stanoveném
časovém intervalu nedostane vůbec žádné potvrzení (ani žádného předchozího
segmentu). V takovém případě se CWND
nastaví na velikost jednoho segmentu (MSS) a SSTHRESH na dvojnásobek velikosti
segmentu (2x MSS) a začne se s pomalým startem od počátku.
Vyhýbání se zahlcení
Odesilatel udržuje pro každé
spojení aktuální hodnoty proměnných MSS, WINDOW, CWND i SSTHRESH. MSS je
určeno příjemcem v okamžiku navazování spojení (segment s touto volbou
má příznak SYN). WINDOW určuje příjemce dynamicky během spojení – specifikuje
množství dat, která se mu vejdou do vyrovnávací paměti.
Odesilatel v okamžiku odesílání
segmentu nemůže meditovat nad tím co má udělat, ale musí se rozhodnout
rychle na základě udržovaných proměnných:
-
Když je CWND menší nebo rovno
SSTHRESH, pak se jedná o pomalý start. Je tedy možné se pokusit o odeslání
dvojnásobku dat.
-
V případě, že CWND je již větší
než SSTHRESH, pak odeslání dvojnásobku by již pravděpodobně způsobilo zahlcení.
V tomto případě se CWND zvyšuje pouze o (MSSxMSS/CWND + MSS/8) počítáno
v celočíselné aritmetice.Toto “drobné zvětšování” CWND se nazývá algoritmus
vyhýbání se zahlcení (Congestion Avoidance Algorithm).
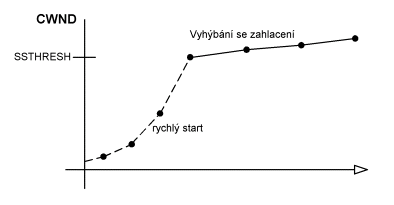
Obr. 9.19 Vyhýbání se zahlcení
-
Ztráta segmentu
Ztrátě TCP segmentu nezamezí
ani uvedený algoritmus. Ke ztrátě může dojít i změnou situace na přenosových
cestách, poruchou přenosové cesty atd.
V případě, že CWND je značně
velké (může být řádově i MB či dokonce GB), pak opakování celého nepotvrzeného
okna v případě ztráty jednoho segmentu by bylo velice nepříjemné, protože
by enormně zvyšovalo režii. Je proto snaha využít tzv. algoritmus rychlého
zopakování.
Jak však odesilatel zjistí,
že došlo ke ztrátě TCP segmentu? (Nyní se již nebude zmiňovat o případu,
že odesilatel nedostává od příjemce potvrzováno vůbec nic.) Příjemce zjistí,
že došlo ke ztrátě segmentu tím, že dostává další segmenty (a ztracený
segment stále nedochází). Tj. chybí mu data v posloupnosti přijímaných
dat. Přicházejí mu tedy segmenty mimo pořadí. Příjemce je povinen v případě
přijetí segmentu mimo pořadí zopakovat (duplikovat) potvrzení posledního
správně přijatého segmentu.
Jenže TCP segmenty jsou zabaleny
do IP-datagramu. Každý IP-datagram putuje Internetem samostatně a teoreticky
jinou cestou. Některé cesty jsou rychlejší a jiné pomalejší. Může se stát,
že segment putoval pomalejší cestou a přirozeně dorazil později než následující
segment. Mezitím však příjemce již provedl odeslání duplikovaného potvrzení.
Přijetí jedné duplikované
odpovědi je proto bráno vcelku za běžnou záležitost. Jiná je situace, když
se segment opravdu ztratil. Příjemce pak segment nedostal a dostal následující
segment. Provedl duplikaci potvrzení posledního správně přijatého segmentu.
Poté však dostane ještě následující segment, ten je však také mimo pořadí,
protože příjemce ještě neobdržel ztracený segment. Opět provede duplikaci.
Příjemce obdrží opět další segment,
který je rovněž mimo pořadí – zopakuje duplikaci atd.
Odesilatel pak od příjemce
postupně dostává první duplikát, druhý duplikát a stále si říká, že to
je vcelku normální. Po obdržení třetího duplikátu si však řekne: “To už
se opravdu muselo něco stát, zopakuji mu segment o kterém se příjemce domnívá,
že je ztracen” a provede zopakování ztraceného segmentu. Příjemce obdrží
ztracený segment. Avšak jelikož příjemce nezahodil žádný z následujících
segmentů (původně přijatých mimo pořadí), tak potvrdí přijetí všech přijatých
segmentů.
Tento algoritmus rychlého
zopakování umožňuje zopakovat pouze ztracený segment a nikoliv nutnost
opakování všech nepotvrzených dat. Opakování všech nepotvrzených dat je
nutné pouze v případě, že se algoritmus rychlého opakování nestihne v zadaném
časovém intervalu.
Jak je to v případě rychlého
zopakování s proměnnýcmi CWND a SSTHRESH?
-
Když příjemce obdrží třetí duplikát,
pak:
-
nastaví SSHTRESH na CWND/2,
-
zopakuje odeslání TCP segmentu,
-
nastaví CWND na SSHTRESH+3xMSS.
-
Po přijetí čtvrtého a dalšího
duplikátu odesilatel vždy pokaždé zvětší CWND o velikost segmentu (MSS).
-
V případě, že ztracený segment
je konečně potvrzen příjemcem, pak odesilatel nastaví CWND na hodnostu
SSTHRESH.