6 ASN.1, BER & DER
Definice jazyka ASN.1 a kódování BER jsou poměrně rozsáhlé definice, takže jejich studium je obecně považováno za odtažité téma. Zvolili jsme metodu „středoškolského výkladu“, tj. smysl většiny pojmů vysvětlujeme na příkladech. Je tedy důležité příklady nepřeskakovat.
Cílem tohoto textu je –představit úvod do problematiky tak, aby pak bylo snadnější studovat normy samotné, které jsou vyčerpávající. Bohužel v této oblasti je mnohé normalizováno pomocí doporučení ITU-T (dříve CCITT), takže normy jsou obtížněji dostupné. Lze do nich bezplatně nahlédnout v knihovně.
Kromě příslušných norem vycházíme také z literatury: "A Layman's Guide to a Subset of ASN.1, BER a DER" zveřejněné na http://www.rsasecurity.com.
Jazyk ASN.1 (Abstract Syntax Notation One) zavádí celosvětově jednoznačnou klasifikaci jednotlivých objektů a metody pro definice jejich vlastností v textové i číselné formě. V počítačové komunikaci (např. v síťových protokolech) lze pomocí ASN.1 přesně specifikovat, co má počítač na mysli, když něco chce sdělit svému protějšku.
V ASN.1 se objekty popisují tak, aby popis byl snadno čitelný pro člověka (to bohužel není míněno ironicky).
Při komunikaci dvou počítačů však není nutné, aby se data přenášela ve tvaru čitelném pro člověka. Naopak je nutné zajistit takový tvar, aby byl jednoznačný pro všechny platformy počítačů. Informace se proto převádí z jazyka ASN.1 do kódování BER (Basic Encoding Rules) specifikující jednotlivé bity přenášených bajtů. Informace kódovaná v BER je nejenom pro člověka nečitelná, ale jelikož se jedná o binární data, tak je i nezobrazitelná na displejích. Při výkladu budeme jednotlivé bajty zobrazovat v hexadecimálním tvaru (dvě šestnáctkové číslice). Při komunikaci počítačů může být také na závadu osmibitový přenos. V takovém případě se zpravidla BER-kódované informace ještě kódují Base64 (převádí se do sedmibitového tvaru) a říká se tomu někdy „PEM-formát“, protože Base64 kódování BER-kódovaných dat se poprvé objevilo v dnes již téměř zapomenuté normě PEM.
Zápis v hexadecimálním (šestnáctkovém) tvaru je sice také sedmibitový, ale kódování Base64 je efektivnější, protože prodlouží výsledek jen o třetinu, kdežto hexadecimální zápis prodlouží data na dvojnásobek. (O tomto problému jsme se již zmínili v kapitole o kódování „Quoted Printable“)
DER kódování (Distinguished Encoding Rules) je podmnožinou BER kódování, se
kterou se nejčastěji setkáváme v oblasti certifikátů X.509. Rozdíl mezi BER a
DER lze přirovnat k vyjadřování čísel. Běžně používáme např. číslo 7, ale je
možné napsat i 007. Pro BER jsou přípustné obě varianty (7 i 007), pro DER jen
první (krátká) varianta, tj. 7. DER kódování nepoužívá nedefinovanou délku dat.
Jazyk ASN.1 je definován v doporučeních ITU-T X.680 až X.683.
V programovacích jazycích se definují typy proměnných
(řetězec, celé číslo, číslo v exponenciálním tvaru atd.). ASN.1 definuje typy
dat jako řetězce bitů v paměti počítače.
6.1 Typy a identifikátory
Jazyk ASN.1 nepoužívá slovní spojení „typ proměnné“ nebo spojení „typ dat“, ale pouze slovo „typ“. Typem míníme pojmenovanou množinu hodnot. Např. typ BOOLEAN nabývá hodnoty TRUE nebo FALSE. Typ INTEGER je množinou celých kladných a záporných čísel včetně nuly (pomíjíme problém, že tato množina je prakticky omezená) atd. Hodnotou pak rozumíme jeden prvek z této množiny.
Podobně jako ve vyšších programovacích jazycích máme proměnné pojmenovávající se svými identifikátory, tak v jazyce ASN.1 máme jejich obdobu, která se nazývá identifikátor. Hovorově se asi nesprávně i zde někdy používá místo slova identifikátor slovo proměnná nebo spojení identifikátor proměnné.
Když už jsme použili přirovnání k vyššímu programovacímu
jazyku, tak např. v jazyce C definujeme celočíselnou proměnnou a jako
int a
Tedy nejprve napíšeme typ (integer) a pak
identifikátor proměnné (a). Avšak např. v jazyce COBOL bychom proměnnou a
definovali např.
a PIC S9(4) COMP
Tedy nejprve bychom napsali identifikátor proměnné a pak
teprve typ proměnné (PIC S9(4) COMP). Nyní Vás asi napadlo, proč jsem
použil jako příklad něco tak archaického jako COBOL, ale v jazyce ASN.1 se to
píše slovy podobnými jazyku C, zatímco pořadí je podobné jako v COBOLu, tj.:
a INTEGER
Důležité je, že identifikátory začínáme zásadně malým písmenem, kdežto typy velkým písmenem.
Typy v jazyce ASN.1 rozlišujeme:
· Jednoduchý („vestavěný“) typ, který již dále není strukturován. Např. INTEGER, OCTET STRING, PrintableString, OBJECT IDENTIFIER atd.
· Strukturovaný typ, který se skládá z jednotlivých položek. Každá položka struktury je nějakým typem. Jednotlivé prvky struktury zapisujeme do složených závorek {} a oddělujeme vzájemně čárkou.
· Odvozený typ, který je odvozen od ostatních typů.
· Jiné typy - jedná se zejména o typy CHOICE (výběr) a ANY (vše).
Nové typy definujeme operátorem přiřazení ::= (dvě dvojtečky a rovná se).
Příklad:
Version ::= INTEGER
Příklad definice nového typu Zamestnanec popisujícího kartu
zaměstnance ve firmě kapitalista.cz (karta zaměstnance je tvořena posloupností
o čtyřech prvcích, první dva jsou typy IA5string a druhé dva typu BOOLEAN) :
Zamestnanec ::= SEQUENCE {
prijmeni IA5string,
jmeno IA5string,
pohlavi BOOLEAN,
znamosti BOOLEAN
}
Typy mají své slovní označení (INTEGER, OCTET STRING atd.). Kromě toho je každý typ specifikován číslem, které se anglicky nazývá „Tag Number“, česky asi nesprávně, ale s oblibou používaným slovem tág.
Dva typy jsou stejné, mají-li stejný tág. Z toho je už jasné, že slovní označení je pouze pomocné a podstatný je právě tág. Tág bude základem i pro kódování DER.
Tágy se dělí na třídy:
· Univerzální tágy, které zavádí již norma X.208 (předchůdce norem X.680 a6 X.683) a jsou určeny celosvětově pro všechny aplikace. Např. typ INTEGER má univerzální tág hodnotu 2.
· Aplikační tágy, jejichž hodnota je platná pouze v rámci konkrétní aplikace (aplikací rozumíme např. protokol X.500, protokol SNMP atp.). Např. v protokolu SNMP se používá typ IpAdress, který má tág 40 (šestnáctkově). V jiných aplikacích se typ IpAdress nepoužívá, proto není třeba, aby tento typ byl univerzální.
· Privátní tágy, jejichž platnost je pouze v rámci firmy.
· Specifické tágy závislé na způsobu použití (Context-specific tags). V jedné aplikaci se může používat stejná hodnota tágu pro více typů (v různých strukturách). Z kontextu musí být ale jednoznačně jasné, o jaký typ se jedná. Rozsah platnosti tohoto typu tágu je obvykle pouze v rámci jedné struktury. S tímto typem tágu se setkáme např. u certifikátu či CRL. Certifikát je poměrně složitá struktura skládající se až ze čtyř částí. Přitom poslední tři části jsou nepovinné. První část začíná specifickou nulou, druhá jedničkou, třetí dvojkou a čtvrtá trojkou. Při zpracování certifikátu pak najdeme první část od specifické nuly před specifickou jedničku a třeba poslední čtvrtou část (rozšíření certifikátu) pak začíná od specifické trojky.
Dále se dozvíme, že číslo identifikující typ je součtem tágu, třídy a skutečnosti, jedná-li se o strukturovaný nebo jednoduchý typ.
6.2 BER kódování
BER je specifikováno v doporučeních X.690 a X.691.
Cílem BER kódování je převést zápis z jazyka ASN.1, tj. z podoby dobře čitelné pro člověka, do podoby (kódování) vhodné pro komunikaci mezi počítači.
Problémem každého kódování je interpretace jednotlivých bitů v každém bajtu. BER specifikuje pořadí, v jakém se interpretují jednotlivé bity v každém bajtu tak, že nejvýznamnější bit je vlevo:
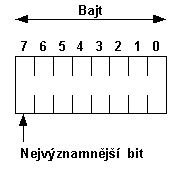
Obr. 6-1 Nejvýznamnější bit je v BER kódování zcela vlevo (obdobně jako v paketech protokolů TCP/IP)
Data se v BER kódují vždy ve struktuře tří polí: typ dat, délka a hodnota:
![]()
Obr. 6-2 Jakýkoliv údaj se v BER kódování skládá ze tří polí (posední pole data je nepovinné)
6.2.1 Pole typu dat
Pole typu dat je pro tágy menší než 31 jednobajtové. Pro větší tágy je vícebajtové. V praxi je snaha používat v maximální míře tato pole jednobajtová.
Pole typu dat v sobě nese součet tří hodnot, ze kterých je složeno (obr. 6-3):
· Třídy (první 2 bity zleva).
· Informace zdali se jedná o konstruovaný (strukturovaný) nebo jednoduchý typ (třetí bit zleva).
· Tág (zbylé bity - zprava).
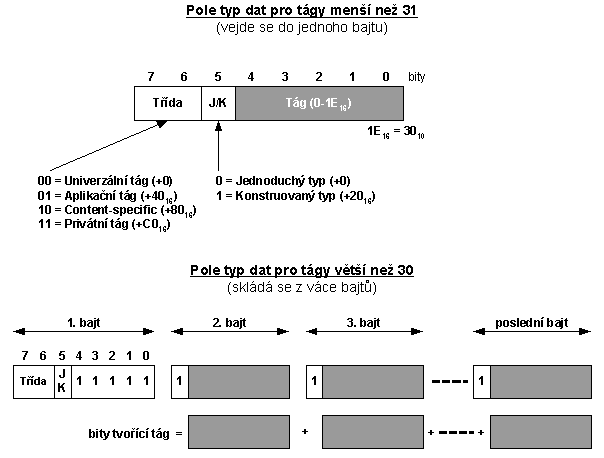
Obr. 6-3 Pole typ dat
Univerzální typy začínají od nuly, aplikační od 64 (šestnáctkově 40), specifické od 128 (8016) a privátní od 192 (C016). Není-li typ jednoduchý, tj. je-li strukturovaný, pak se musí přičíst ještě bit J/K, tj. přičte se 32 desítkově, resp. 20 šestnáctkově.
Některé hodnoty univerzálních tágů jsou uvedeny v
následující tabulce:
|
Typ |
Tág
desítkově |
Tág
šestnáctkově |
Význam |
|
END OF CONTENS (EOC) |
0 |
0 |
Konec pole dat v kódování BER pro případ, že data jsou nedefinované délky. Kódování DER EOC nepoužívá, protože DER nepoužívá nedefinovanou délku. |
|
BOOLEAN |
1 |
1 |
Nabývá hodnot TRUE a FALSE |
|
INTEGER |
2 |
2 |
Celá kladná i záporná čísla a nula |
|
BIT STRING |
3 |
3 |
Řetězec bitů - může být zadán
binárně nebo hexadecimálně. |
|
OCTET STRING |
4 |
4 |
Řetězec bajtů (blíže nespecifikovaný) |
|
NULL |
5 |
5 |
Prázdný typ |
|
OBJECT IDENTIFIER |
6 |
6 |
Identifikátor objektu (viz samostatná kapitola) |
|
REAL |
9 |
6 |
{Mantisa,Base,Exponent} = M x BE |
|
ENUMERATED |
10 |
A |
Výčet hodnot (nemusí být uspořádaný) |
|
UTF8String |
12 |
C |
Viz kap. 6.7 |
|
SEQUENCE a SEQUENCE OF |
16 |
10 |
Uspořádaná posloupnost prvků. SEQUENCE OF může být i prázdná. |
|
SET a SET OF |
17 |
11 |
Množina prvků (neuspořádaná). SET OF může být i prázdná. |
|
NumericString |
18 |
12 |
|
|
PrintableString |
19 |
13 |
0-9 a-z A-Z mezera ' ( ) + , - . / : = ? |
|
T61String |
20 |
14 |
TeleText podle doporučení T.61 Kromě PrintableString
obsahuje: |
|
VideotexString |
21 |
15 |
|
|
IA5String |
22 |
16 |
ASCII, tj. kromě znaků PrintableString obsahuje: SPACE DELETE |
|
UTCTime |
23 |
17 |
Čas ve formatu UTC. |
|
Graphicstring |
25 |
19 |
|
|
VisibleString |
26 |
1A |
|
|
GeneralString |
27 |
1B |
|
|
UniversalString |
28 |
1C |
|
|
BMPString |
30 |
1E |
|
Prostě pro znakové řetězce jsou určeny tágy 18-22 a 25-30 a pro časové typy jsou určeny tágy 23 a 24.
Příklad:
SEQUENCE má hodnotu tágu šestnáctkově 10, ale sekvence není jednoduchý
typ (skládá se z prvků tvořící sekvenci), tj. je strukturovaným typem
(připočítáváme tedy 2016), takže výsledná hodnota pole typu je:
1016 + 2016 = 3016.
Názvy typů začínají velkým písmenem. Názvy typů, které jsou tvořeny pouze velkými písmeny (všechna písmena jsou velká jako např. INTEGER) jsou klíčovými slovy jazyka ASN.1 a nesmí se použít v jiném významu.
6.2.2 Pole délka dat
Délku je možné principiálně vyjádřit dvěma způsoby:
· Explicitně definujeme, z kolika bajtů se datové pole skládá.
· Explicitně nespecifikujeme, z kolika bajtů se datové pole skládá (nedefinovaná délka). V tomto případě se pole délka skládá z jednoho bajtu o šestnáctkové hodnotě 80. Pole dat pak ukončíme dvěma znaky, které mají šestnáctkově hodnotu 00 00, tj. EOC.
Při explicitní definici délky datového pole rozlišujeme opět dva případy:
· Datové pole se skládá z 0 až 127 bajtů, pak pole délky je jednobajtové (tzv. krátká forma pole délka).
· Datové pole je delší než 127 bajtů (tzv. dlouhá forma pole délka). V tomto případě je v prvním bajtu specifikováno, z kolika dalších bajtů se pole délka skládá.
Pro případ explicitní definice délky je význam jednotlivých bitů v poli délky znázorněn na obrázku 6-4.
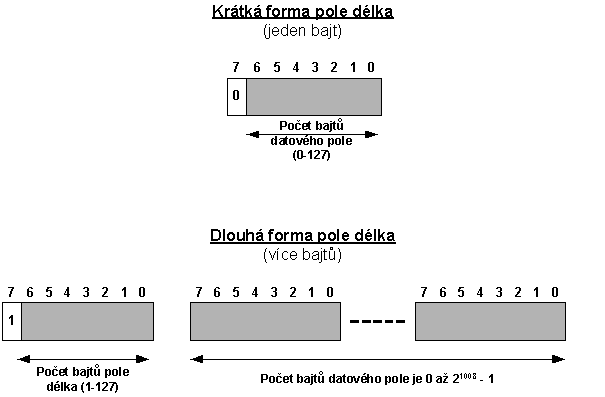
Obr. 6-4 Pole délka (126x8=1008)
Příklad: Datové pole je dlouhé 2 bajty, pak v poli délka může být (šestnáctkově):
· 02 (jediná přípustná hodnota pro DER)
· 81 02 (protože 100000012 = 8116)
· 82 00 02
· Atd.
· Ale také můžeme použít nedefinovanou délku, tj. 80 02 00 00
6.2.3 Pole data
Pole data pak obsahuje vlastní data.
6.2.4 Příklady
Příklad 1: Vyjádřete celé číslo 13 v kódování
BER.
Celé číslo je univerzálního typu INTEGER, který je nestrukturovaný. Určeme
hodnotu jednotlivých polí:
· Pole typu má hodnotu 0 (univerzální tág) plus 0 (jednoduchý typ) plus 2 (INTEGER), což je dohromady 2.
· Pole délka vyjadřující délku dat musí specifikovat hodnotu 1 (třináctka se vejde do jednoho bajtu). V kódování BER je tedy přípustné, aby v poli délka bylo 01 nebo 81 01 nebo 82 00 01 atd.
· Pole data nese vlastní hodnotu 13, tj. šestnáctkově 0D.
Výsledek je 02 01 0D nebo 02 81 01 0D atd. (V Kódování DER
je přípustné pouze 02 01 0D). Řetězec 02010D se pak přenáší počítačovou sítí a
každý ví (i hacker), že se jedná o třináctku.
Příklad 2: Nyní můžeme přistoupit ke
složitějšímu příkladu. V kódování BER vyjádřete jednu položku z kartotéky
zaměstnanců firmy kapitalista.cz. Tato firma má každého zaměstnance popsaného
na kartě skládající se ze čtyř položek:
|
příjmení |
IA5String |
|
jméno |
IA5String |
|
pohlavi |
BOOLEAN |
|
známosti |
BOOLEAN |
Jenže každá karta je v sekvencí těchto položek. Vyjádřeno
tabulkou
|
|
Což v ASN.1 vyjádříme: } |
V ASN.1 se v praxi zápis Typu Zamestnanec píše elegantněji:
Zamestnanec ::= SEQUENCE {
prijmeni Prijmeni,
jmeno Jmeno,
pohlavi
Pohlavi,
znamosti Znamosti
}
Kde
Prijmeni ::=
IA5string,
Jmeno ::= IA5string,
Pohlavi ::= BOOLEAN,
Znamosti ::= BOOLEAN}
Místo typu SEQUENCE by se asi měl použít typ SEQUENCE OF,
protože kartotéka může být i prázdná (když všechny zaměstnance propustíme).
Takže kartu v kódování BER pro zaměstnance: Bobek Bob TRUE (Pohlavi) FALSE (Znamosti) bychom v BER konstruovali zevnitř (od jednoduchých typů):
· Bobek bude 16 05 42 6F 62 65 6B (16 je tág pro IA5STRING; řetězec je dlouhý 05 znaků)
· Bob bude 16 03 42 6F 62
· TRUE bude 01 01 FF
· FALSE bude 01 01 00
· Celkově je vnitřek 16 05 42 6F 62 65 6B 16 03 42 6F 62 01 01 FF 01 01 00, tj je dlouhý 18 bajtů, tj. šestnáctkově 12.
·
Nyní specifikujeme posloupnost (vnějšek). U SEQUENCE už
víme, že má hodnotu šestnáctkově 30 (10+20) a je dlouhá 1216, takže
výsledek:
30 12 16 05 42 6F 62 65 6B 16 03 42 6F 62 01 01 FF 01 01 00
Výsledek si zapíšeme ve tvaru, kde pod každým řádkem ASN.1 jsou přímo BER-kódovaná data. Tento tvar budu používat v celé publikaci:
SEQUENCE
30 12
IA5STRING :Bobek
16 05 42 6f 62 65 6b
IA5STRING :Bob
16 03 42 6f 62
BOOLEAN :FF
01 01 FF
BOOLEAN :0
01 01 00
6.2.5 Jak je v BER-kódování kódován prázdný typ?
05 00 (jediné přípustné v DER)
05 81 00
atd.
6.2.6 Jak je kódován typ BOOLEAN?
Pravda se kóduje: 01 01 FF
Nepravda se kóduje: 01 01 00
6.2.7 Jak je to s kódováním typu INTEGER?
Typ INTEGER se kóduje binárně tak, jak je to běžné, tj. nejvýznamnější bit nastavený na 1 signalizuje záporné číslo.
Příklady kódování celých čísel:
|
Hodnota |
BER-kódování |
|
0 |
02 01 00 |
|
12710 = 7F16 |
02 01 7F |
|
12810 = 8016 |
02 02 00 80 |
|
25610 = 10016 |
02 02 01 00 |
|
-12810 (10016-8016=8016) |
02 01 80 |
|
-12910 (1000016-8116=FF7F16) |
02 02 FF 7F |
6.2.8 Výčet
Pomocí typu INTEGER lze vytvořit výčet tak, že se jednotlivé hodnoty pojmenují identifikátory. V kulatých závorkách za identifikátorem hodnoty je pak uvedena pojmenovaná hodnota.
Obecně: INTEGER [{identifikátor-1 (hodnota-1) ... identifikátor-n (hodnota-n)}]
Příklad:
Barva ::= INTEGER {cervena(1) modra(2) bila (3)}
6.2.9 Typy SEQUENCE, SEQUENCE OF, SET a SET OF
Jedná se o strukturované typy (k tágu se připočítává 2016).
Slovo OF v obou případech vyjadřuje, že posloupnost (resp. množina) může být i prázdná.
V posloupnosti (SEQUENCE) záleží na pořadí prvků, v množině (SET) nikoliv.
Syntaxe SEQUENCE o n prvcích je:
SEQUENCE {
[identifikátor-1] Typ-1 [{OPTIONAL |
DEFAULT hodnota-1}],
...
[identifikátor-n] Typ-n [{OPTIONAL |
DEFAULT hodnota-n}] }
Syntaxe SEQUENCE OF, SET a SET OF je obdobná, pouze s tím rozdílem, že slovo SEQUENCE je nahrazeno slovy SEQUENCE OF, resp. SET, resp. SET OF.
Slovo OPTIONAL vyjadřuje, že prvek je volitelný (nepovinný).
Slovo DEFAULT následované hodnotou pak určuje, že v případě, kdy prvek
není uveden, se použije implicitní hodnota.
Pro DER kódování musí být splněny dvě podmínky:
§ V případě, že prvek je nepovinný (OPTIONAL) a nabývá implicitní hodnoty (DEFAULT), pak se neuvádí, tj. nekóduje se do DER.
§ V případě množiny (SET) je pravdou, že nezáleží na pořadí, ale do kódování DER se jednotlivé prvky množiny kódují sestupně setříděny podle hodnoty tágu.
6.2.10 UTCTime
Čas se vyjadřuje v jednom z následujících tvarů:
· RRMMDDhhmmZ
· RRMMDDhhmm+hhmm
· RRMMDDhhmm-hhmm
· RRMMDDhhmmssZ
· RRMMDDhhmmss+hhmm
· RRMMDDhhmmss-hhmm
Znak Z specifikuje, že se jedná o GMT. Za znaménkem + či - je časový posun místní časové zóny.
Např.: 19851106210627.3-0500
vyjadřuje 11.6.1985 v 21:06:27,3, kde místní časové pásmo je 5 hodin západně od
Grenwiche.
V BER-kódování se UTCTime zpravidla kóduje v ASCII, tj. uvedený čas bude:
31 39 38 35 31 31 30 36 32 31 30 36 32 37 2e 33 2d 30 35 30 30
(pro orientaci: 0=3016, 1=3116 , ..., mínus je 2d).
Musíme ještě doplnit typ (UTCTime má 1716 ) a délka je 1516
čili:
17 15 31 39 38 35 31 31 30 36 32 31 30 36 32 37 2e 33 2d 30 35 30 30
6.2.11 Bit string
Řetězec bitů se zprava doplňuje výplní tak, aby jeho délka byla násobkem 8 (tj. doplní se na bajty). V DER kódování (na rozdíl od BER) musí být výplň tvořena binárními nulami.
Zleva se před řetězec doplní bajt binárně vyjadřující, o kolik bitů byl řetězec doplněn.
Příklad:
|
Řetězec |
01101110 11 |
|
Zprava doplněn šesti binárními nulami |
01101110 11000000 |
|
Převeden na bajty (vyjádřeno šestnáctkově) |
6E C0 |
|
Zleva doplněn bajtem vyjadřujícím délku výplně (6) |
06 6E C0 |
|
BER kódování (03 je tág pro bit string; 03 je i délka) |
03 03 06 6E C0 |
6.3 Identifikace objektů
Mezinárodní normalizační úřad (ISO) ve spolupráci s ITU (dříve Telefonní a telegrafní unie - CCITT) vypracovali jednotnou klasifikaci všech objektů. Tato klasifikace vytváří stromovou strukturu všech objektů. Podle této klasifikace lze klasifikovat všechny objekty Vesmíru (i ty, které budou teprve vyvinuty nebo poznány).
Na vrcholu klasifikačního stromu jsou samy normalizační úřady, protože jestliže se něco klasifikuje, pak nejprve musí být stanoveno, kdo klasifikaci provádí. Nejvyššími položkami jsou itu, iso a joint-iso-itu (společně ISO a ITU). Pod položkou itu jsou podřízené položky, které určuje ITU, pod položkou iso jsou položky stanovované ISO a pod položkou joint-iso-itu jsou položky, které stanovuje ISO společně s ITU.
ISO je tzv. registrační autorita podstromu začínajícího položkou iso, tj. registruje a je zodpovědná za objekty umístěné ve stromové struktuře pod položkou iso. Obdobně ITU je registrační autoritou pro svůj podstrom.
Registrační autorita (např. ISO) může delegovat pravomoci pro registraci objektů na registrační autoritu nižší úrovně tak, že jí určí položku, pod kterou může registrovat své objekty. Mechanizmus je podobný mechanizmu přidělování domén v DNS.
Poznámka: termín registrační autorita nemá žádnou souvislost s termínem registrační autorita z kapitoly o certifikátech v kapitole o PKI.
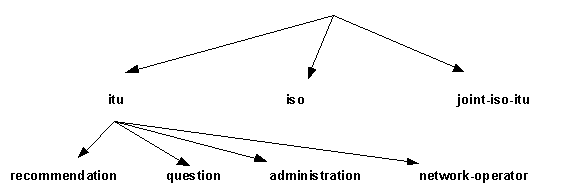
Obr. 6-5 Strom objektů
Opět slovní vyjádření názvů jednotlivých položek je pouze vhodné pro komunikaci lidí. Norma ISO 8824 zavádí číselné označení jednotlivých položek. Čísla se uvádí v kulatých závorkách za názvem položky:
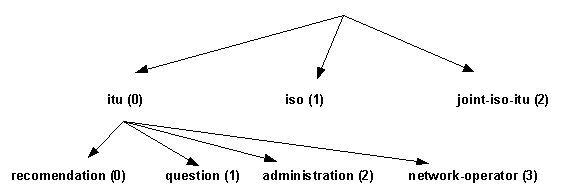
Obr. 6-6 Strom s číselným označením objektů
Položka je pak určena čísly všech položek, které vedou od kořene až k položce. Jednotlivé číslice se v textovém zápisu oddělují mezerou nebo tečkou. Např. položku question(1) můžeme zapsat jako {0.1}.
Ve většině případů je strom značně rozvětvený a cesta vede přes mnoho položek. Je možné do složených závorek napsat podstrom celé struktury. Jako první položka se ve složených závorkách pak napíše jméno položky tvořící kořen podstromu následované mezerou s číslem položky nižší úrovně.
Celý mechanizmus je názorně vidět na složitějším případě. Na obr. 6-7 je rozsáhlejší strom:

Obr. 6-7 Rozsáhlejší strom
Položka internet(1) lze zapsat jako {iso(1) org(3) dod(6) 1} nebo jako {1.3.6.1}- názvy jsou nadbytečné. Dokonce i na předchozím obrázku je uvedeno identified-organization(3) a v zápisu org(3) a význam je stejný - podstatná je trojka.
Nové objekty se definují pomocí operátoru ::= . Např. objekt internet se definuje:
internet OBJECT IDENTIFIER ::= {iso org(3) dod(6) 1}
nebo jednodušeji:
internet OBJECT IDENTIFIER ::= {1.3.6.1}
Další objekty lze definovat už i za využití podstromu. Např.:
directory OBJECT
IDENTIFIER ::= {internet 1}
mgmt OBJECT IDENTIFIER ::=
{internet 2}
mib OBJECT IDENTIFIER ::= {mgmt 1}
atd.
Cvičení: Nakreselete si strom pro položky:
pkcs-7 OBJECT IDENTIFIER ::=
{iso(1) member-body(2) US(840) rsadsi(113549)
pkcs(1) 7}
signedData OBJECT IDENTIFIER ::=
{pkcs-7 2}
envelopedData OBJECT IDENTIFIER ::=
{pkcs-7 3}
6.3.1 Kódování identifikace objektů v BER
Pro pochopení kódování do BER je docela příhodný objekt (rsadsi) specifikující firmu RSA Data Security Inc. (z předchozího cvičení), na kterém budeme ilustrovat kódování objektů do BER.
Identifikace objektu rsadsi vyjádřená ve složených závorkách je tedy {1.2.840.113549}. Při konverzi do BER se jiným způsobem konvertují první dvě čísla a jiným ostatní:
·
Konverze prvních dvou čísel je jiná, protože první
číslo nabývá hodnot 0, 1 a 2. Druhé číslo pak hodnot 0 až 39. Provede se
výpočet 1.číslo x 4010 + 2.číslo.
Pro náš případ je 1 x 4010 + 2 = 4210 = 2A16.
·
Následující čísla se pak kódují již samostatně. Jelikož
ne každé číslo se vejde do jednoho bajtu, je nutné dlouhá čísla umísťovat do
několika bajtů. Jenže jak zjistit, z kolika bajtů se které číslo skládá?
Použije se trik. Ke kódování se použije pouze 7 bitů z každého bajtu. Osmý bit
(nejvyšší tj. levý bit) slouží ke specifikaci konce čísla. Pokud je nejvyšší
bit nastaven na 1, pak i následující bajt patří k tomuto číslu. Poslední bajt
čísla má nejvyšší bit roven nule.
Problém spočívá v tom, že do každého bajtu se tedy vejde nejvíce 128 hodnot -
vše tedy musí být počítáno modulo 128.
Příklad: Číslo 840:
840 = 6 x 128 + 4816 takže číslo 840 (desítkově) bychom mohli napsat
jako 06 48 (šestnáctkově), jenže si musíme vzpomenou, že se skládá ze dvou
bajtů, takže prvnímu musíme nastavit nejvyšší bit na jedničku - jinými slovy k
prvnímu bajtu musíme přičíst šestnáctkově 80, takže výsledek:
86 48
Příklad: Číslo 1135949:
113549 = 06 x 1282 + 7716 x 1281+ 0D16
x 1280 což by se dalo zapsat jako 06 77 0D jenže k prvním a druhému
bajtu nesmíme zapomenout připočíst šestnáctkově 80, protože to nejsou poslední
bajty čísla. Takže výsledek 86 F7 0D.
Příklad: Vyjádřete v BER identifikátor objektu {1 2 840 1135949}:
· Pole typu dat je 0 (univerální objekt) + 0 (jednoduchý objekt, tj. dále již nestrukturovaný) + 6 (OBJECT IDENTIFIER) = 06
· Pole délky je 06
· Datové pole je 2A 80 48 86 F7 0D (Viz předchozí příklady)
Výsledek: 06 06 2A 86 48 86 F7 0D
Cvičení: Vyjádřete v BER identifikátor objektu {1.3.6.1.2.1.1.1}, tj. objekt sysDescr používaný protokolem SNMP. (Je to jednoduché, protože není třeba nic počítat modulo 128).
Dostanete:
OBJECT
:1 3 6 1 2 1 1 1
06 07 2b 06 01 02 01 01 01
Poznámka: Identifikátor objektu identifikuje objekt, tj. např. identifikátor sysDescr identifikuje objekt „popis počítače“. Jenže konkrétní počítač má své jméno např. „AlphaServer“. V praxi je tedy třeba svázat objekt s nějakým typem, který naplní objekt obsahem. I hovorově řekneme: „počítač: AlphaServer“.
V ASN.1 se pro svázání objektu s jeho obsahem zpravidla
používá typ SEQUENCE. Např.
SEQUENCE {
sysDescr OBJECT IDENTIFIER,
popis
OCTED STRING}
Příklad objektu „AlphaServer“:
SEQUENCE
30 16
OBJECT
:1 3 6 1 2 1 1 1
06 07 2b 06 01 02 01 01 01
OCTET STRING :AlphaServer
04 0b 41 6c 70 68 61 53 65 72 76 65 72
Tj. pokud chce jeden počítač druhému sdělit: „počítač je AlphaServer“,
pak mu prostě binárně pošle: „30 16 06 07 2b 06 01 02 01 01 01 04 0b 41 6c 70
68 61 53 65 72 76 65 72“ a on už ví, kolik uhodilo.
6.4 Odvozené typy
Chceme-li popisovat nějakou strukturu (tj. typ SEQUENCE, SEQUENCE OF, SET, atd.), pak u typu SET je potíž s pořadím položek (množina není obecně uspořádaným typem). Skládá-li se množina např. ze tří celých čísel popisujících rozměry nějakého předmětu, pak je třeba říci, které číslo je výška, které šířka a které hloubka. To lze dosáhnout v principu třemi cestami:
· Zavést identifikátor objektu výška, objektu šířka a objektu hloubka. Naši množinu pak sestavit ze tří sekvencí (SEQUENCE). Každá by se skládala z příslušného identifikátoru a hodnoty. Toto řešení je možné, ale trochu složité pro takto jednoduchý případ.
· Místo typu SET použít typ SEQUENCE. Jenže s typem SEQUENCE jsou podobné potíže v případě, že některé prvky SEQUENCE jsou volitelné. Např. může být volitelná výška a šířka (použije se jen je-li jiná než běžná) a už nevíme, zdali je první hodnota výška nebo šířka.
· Můžeme odvodit od typu INTEGER tři nové typy, které budou (v rámci kontextu, aplikace nebo firmy) specifikovat výšku šířku a hloubku - odvodíme nový typ.
Typ se skládá ze třídy (context-specific, application, private - univerzální třídu zavádí pouze norma) a tágu (ten si určím sám).
Na následujících příkladech ukážeme, jak se nové typy odvozují.
Příklad A: Určete typy pro šířku, výšku a
hloubku tak, aby byly platné v rámci vaší firmy (tj. zavádíme privátní typ).
Jako tágy si zvolte čísla 1 (výška), 2 (šířka) a 3 (hloubka).
Takže jedná se o privátní typy (+ C016) jednoduché dále
nestrukturované typy (+ 0) plus příslušný tág, takže dostaneme C1, C2 a C3.
Příklad B: V kódování BER zapište podle předchozího příkladu předmět vysoký 1m, široký 2m a hluboký 1m.
Výsledkem bude 30 09 c1 01 01 c2 01 02 c3 01 01, tj.:
SEQUENCE
30 09
priv [ 1 ]
c1 01 01
priv [ 2 ]
c2 01 02
priv [ 3 ]
c3 01 01
Zápis priv [1] znamená, že se jedná o typ třídy PRIVATE s tágem 1.
U takto definovaných typů musí příjemce vědět, že typ C1 je odvozen od typu INTEGER (nikde uvnitř nově zavedeného typu není původní typ INTEGER nikterak zakódován). Takto definované typy se nazývají implicitně odvozené typy.
U explicitně odvozených typů je navíc uvedeno, z jakého typu je odvozen. Jedná se tedy o složený (konstruovaný) typ obsahující jednu položku, ale ta se skládá z pole typu, pole délky a pole dat.
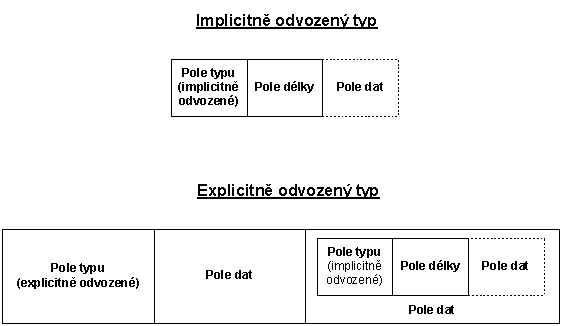
Obr. 6-8 Struktura implicitně a explicitně odvozeného typu
Příklad A (obdoba pro explicitně odvozené typy):
Jelikož explicitně odvozený typ je typem konstruovaným, tak nesmíme zapomenout
přičíst šestnáctkově 20.
Výška bude mít typ C016 (privátní třída) plus 2016 (konstruovaný typ) plus 1 (výška), tedy E1. Obdobně šířka E2 a hloubka E3.
Příklad B (obdoba pro explicitně odvozený typ): Nyní musíme každý rozměr popsat samostatně. Např. výška:
· Pole typ je E1 (viz příklad A).
· Pole data obsahuje hodnotu 1, tj. typ INTEGER, délka 1 a datové pole opět 1. Výsledek je 02 01 01.
· Pole délka je tedy 03.
Čili délka bude E1 03 02 01 01. Obdobně šířka bude E2 03 02 01 02 a výška E3 03 02 01 01.
Výsledek:
SEQUENCE
30 0f
priv [ 1 ]
e1 03
INTEGER :01
02 01 01
priv [ 2 ]
e2 03
INTEGER :02
02 01 02
priv [ 3 ]
e3 03
INTEGER :01
02 01 01
V ASN.1 je syntaxe odvozených typů vyjádřena následujícím přiřazením:
ImplicitniOdvozenyTyp ::= [třída tág] IMPLICIT typ
resp.
ExplicitniOdvozenyTyp ::= [třída tág] EXPLICIT typ
Je třeba si uvědomit, že dvojice (třída, tág) se kóduje do jednoho bajtu (třída je v prvních dvou bitech). V případě, že není třída specifikována, pak se myslí specifická třída.
Příklad:
UTF8String ::= [UNIVERSAL 12] IMPLICIT OCTET STRING
Přímo v doporučení X.690 je velice pěkný příklad, na kterém
je pěkně ilustrována syntaxe:
|
Mějme definovány následující typy: Type1
::= VisibleString Hodnota řetězce je: "Jones" (4A6F6E657316) V BER dostaneme: Type1:
|
6.5 CHOICE
CHOICE umožňuje výběr z několika variant v jazyce ASN.1.
Např. v normě PKCS#7 se zavádí struktura (nejedná se o definici certifikátu dle PKI, ale podle PKCS#7):
ExtendedCertificateOrCertificate
:== CHOICE {
certificate Certificate,
extendedCertificate [0]
IMPLICIT ExtendedCertificate
}
Tím se chce říci, že struktura ExtendedCertificateOrCertificate je buď
certificate
Certificate
nebo
extendedCertificate [0] IMPLICIT ExtendedCertificate
Tj. buď je certifikát podle X.509 verze 1 nebo podle X.509 verze 3. Jenže příjemci je nutné sdělit, jaký typ certifikátu je mu posílán, takže v případě certifikátu verze 1 je poslán samotný certifikát a v případě rozšířeného certifikátu (verze 3) je rozšířený certifikát předcházen nulou (třída: specifická; tág nula).
Z hlediska kódování BER, typ ANY se v rámci CHOICE
nikterak nekóduje, protože se vždy kóduje pouze alternativa, která je vybrána.
6.6 ANY
Typ ANY označuje jakýkoliv typ.
Příklad opět z certifikátu X.509:
AlgorithmIdentifier ::= SEQUENCE {
algorithm OBJECT IDENTIFIER,
parameters ANY DEFINED BY algorithm OPTIONAL}
V příkladu se chce vyjádřit, že identifikátor parameters
může nabývat jakýchkoliv typů. Ovšem ne zcela jakýchkoliv, ale jen těch, které
jsou definovány při definici identifikátoru algorithm. Slovo OPTIONAL
specifikuje, že některé algoritmy nemusí mít parametr žádný, tj. identifikátor parameters
pak nabývá typu NULL.
6.7 Kódování UTF-8
Doposud jsme do textových řetězců plnili pouze znaky kódu US-ASCII. Ale co si počít s tím „Václavem Vopičkou“?, kterého jsme již zakódovali v kapitole o kódování hlaviček elektronické pošty, ale nyní si bude chtít třeba vystavit certifikát s předmětem obsahujícím jeho jméno a to pěkně česky! A certifikát je kódován v DER.
Zatímco v anglicky mluvících zemích vystačí se 128 znaky kódu US-ASCII, tak ve většině ostatních zemí tomu tak není. V minulosti byl znak reprezentován jedním bajtem. Prvních 128 znaků je zpravidla využito právě kódem US-ASCII a zbylých 128 možností zbylo pro všechny ostatní jazyky světa. Nelze se pak divit, že se jednotlivé jazyky v těchto 128 možnostech překrývaly. S textovou zprávou proto bylo nutné přepravovat i informaci o znakové sadě, ve které se má text zobrazit.
Řešením je norma ISO/IEC 10646-1, která definuje vícebajtovou reprezentaci jednoho znaku, kterou nazývá Universal Character Set (UCS). Zavádí čtyřbajtové kódování znaku pod označením UCS-4 a dále zavádí dvojbajtové kódování znaků UCS-2, které kóduje pouze prvních 64K znaků. Kódování UCS-2 je též označováno jako Basic Multilingual Plane (BMP).
Kódování UCS je někdy též označováno jako Unicode.
Nepříjemné je, že kódování UCS nezahrnuje jako podmnožinu kódování US-ASCII, protože kódování UCS kóduje každý znak vždy do dvou (resp. čtyřech) bajtů – nikdy ne do jednoho znaku (i když číselně je binární hodnota u US-ASCII znaků stejná s kódováním Unicode). Např. znak „A“ se kóduje šestnáctkově v kódu US-ASCII jako „41“, kdežto v kódu UCS-2 se písmeno A kóduje jako „00 41“, tj. je tam navíc nula.
Problém řeší kódování UTF-8, které kóduje znak do jednoho až šesti bajtů. Přitom možnost kódovat do jednoho znaku je určena pro znaky US-ASCII, tj. pro znaky US-ASCII je výsledek kódování UTF-8 a US-ASCII identický.
Nyní jaký je rozdíl mezi kódování UTF-8 a UCS. Chtěl jsem napsat, že žádný, ale to není pravda. Jedná se o jednoduchou mechanickou konverzi:
· Pokud je nejvyšší bit bajtu nastaven na nulu, pak se jedná o znak US-ASCII.
· Pokud je nejvyšší bit v bajtu nastaven na jedničku, pak je rozhodující, kolik jedniček za sebou následuje za jedničkou v nejvyšším bitu do následující nuly. Tento počet jedniček určuje, do kolika dalších bajtů je znak kódován.
· Další bajty znaku mají na nejvyšší pozici 102, tj. pro kódování znaku lze v nich využít pouze 6 bitů.
· Nikdy v kódu UTF-8 po sobě nenásledují znaky FE16 a FF16. Důvod je prostý: stačí se podívat do libovolného souboru uloženého v kódu UTF-8 na vašem PC např. ve Windows 2000. Tyto znaky vždy najdete na počátku těchto souborů (systém si jimi označuje, že soubor je kódován v kódu Unicode).
Názorně lze konverzi snadno pochopit na následující tabulce. Znak z rozsahu UCS-4 se převede do dvojkové soustavy. Zjistí se, kolik potřebuje bitů pro své kódování, a jeho jednotlivé bity se umístí do kódu UTF-8 na pozice vyznačené „x“. Výsledek se pak převede do šestnáctkové soustavy a jsme hotovi.
|
UCS-4 rozsah (šestnáctkově) |
UTF-8 binárně |
|
0000
0000-0000 007F 0000
0080-0000 07FF 0000
0800-0000 FFFF 0001
0000-001F FFFF 0020
0000-03FF FFFF 0400
0000-7FFF FFFF |
0xxxxxxx 110xxxxx
10xxxxxx 1110xxxx
10xxxxxx 10xxxxxx 11110xxx
10xxxxxx 10xxxxxx 10xxxxxx 111110xx
10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 1111110x
10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
Asi nejlépe je uvést nějaký příklad. Jelikož Windows 2000 (jako i většina ostatních systémů) podporují kódování Unicode, tak si lze s nimi na toto téma docela pěkně pohrát. Windows 2000 konkrétně podporují kód UCS-2 (lidově označovaný jako „dvojbajtový Unicode“).
V prvním kole jsem vzal textový editor WordPad a pořídil v něm následující řetězec:
AaÄäBbCcČčDdĎďEeÉéĚěKkLlĹ弾OoÓóÔôÖöPpQqRrŘřSsŠšTtŤťUuÚúŮůÜüVvWwXxYyÝýZzŽžß
Pokud si říkáte, proč právě tyto znaky, tak důvod je velice prostý. Jedná se o znaky české slovenské a německé. U těchto jazyků lze předpokládat, že nedojde k deformaci řetězce při konverzi tohoto rukopisu do systému Desk Top Publishing vydavatele.
Nejprve jsem tento řetězec uložil jako „normální“ textový soubor, tj. jednobajtově v kódování Windows. A posléze v kódování Unicode (konkrétně UCS-2). Na oba výsledky uložení jsem se podíval hexadecimálním editorem a s výsledkem jsem byl docela překvapen. Jednobajtové uložení bylo podle očekávání, ale uložení v Unicode je zajímavé tím, že jsou jednotlivé bajty každého znaku uloženy v opačném pořadí. Výsledek jsem znak po znaku zaznamenal do následující tabulky. Ještě zbývá dodat, že následující tabulka neobsahuje znaky FE FF, kterými je soubor v kódu Unicode uvozen.
|
Znak |
Název znaku |
Kód Windows |
UCS-2 na disku |
UCS-2 hexa. |
UCS-2 binárně |
UTF-8 binárně |
UTF-8 |
|
A |
|
41 |
41 00 |
|
|
|
41 |
|
a |
|
61 |
61 00 |
|
|
|
61 |
|
Ä |
A s dvěma tečkami |
C4 |
C4 00 |
00 C4 |
11 000100 |
11000011 10000100 |
C3 84 |
|
ä |
a s dvěma tečkami |
E4 |
E4 00 |
00 E4 |
11 100100 |
11000011 10100100 |
C3 A4 |
|
B |
|
42 |
42 00 |
|
|
|
42 |
|
b |
|
62 |
62 00 |
|
|
|
62 |
|
C |
|
43 |
43 00 |
|
|
|
43 |
|
c |
|
63 |
63 00 |
|
|
|
63 |
|
Č |
|
C8 |
0C 01 |
01 0C |
100 001100 |
11000100 10001100 |
C4 8C |
|
č |
|
E8 |
0D 01 |
01 0D |
100 001101 |
11000100 10001101 |
C4 8D |
|
D |
|
44 |
44 00 |
|
|
|
44 |
|
d |
|
64 |
64 00 |
|
|
|
64 |
|
Ď |
|
CF |
0E 01 |
01 0E |
100 001110 |
11000100 10001110 |
C4 8E |
|
ď |
|
EF |
0F 01 |
01 0F |
100 001111 |
11000100 10001111 |
C4 8F |
|
E |
|
45 |
45 00 |
|
|
|
45 |
|
e |
|
65 |
65 00 |
|
|
|
65 |
|
É |
|
C9 |
C9 00 |
00 C9 |
11 001001 |
11000011 10001001 |
C3 89 |
|
é |
|
E9 |
E9 00 |
00 E9 |
11 101001 |
11000011 10101001 |
C3 A9 |
|
Ě |
|
CC |
1A 01 |
01 1A |
100 011010 |
11000100 10011010 |
C4 9A |
|
ě |
|
EC |
1B 01 |
01 1B |
100 011011 |
11000100 10011011 |
C4 9B |
|
F |
|
46 |
46 00 |
|
|
|
46 |
|
f |
|
66 |
66 00 |
|
|
|
66 |
|
G |
|
47 |
47 00 |
|
|
|
47 |
|
g |
|
67 |
67 00 |
|
|
|
67 |
|
H |
|
48 |
48 00 |
|
|
|
48 |
|
h |
|
68 |
68 00 |
|
|
|
68 |
|
I |
|
49 |
49 00 |
|
|
|
49 |
|
i |
|
69 |
69 00 |
|
|
|
69 |
|
Í |
|
CD |
CD 00 |
00 CD |
11 001101 |
11000011 10001101 |
C3 8D |
|
í |
|
ED |
ED 00 |
00 ED |
11 101101 |
11000011 10101101 |
C3 AD |
|
J |
|
4A |
4A 00 |
|
|
|
4A |
|
j |
|
6A |
6A 00 |
|
|
|
6A |
|
K |
|
4B |
4B 00 |
|
|
|
4B |
|
k |
|
6B |
6B 00 |
|
|
|
6B |
|
L |
|
4C |
4C 00 |
|
|
|
4C |
|
l |
|
6C |
6C 00 |
|
|
|
6C |
|
Ĺ |
L s čárkou nad |
C5 |
39 01 |
01 39 |
100 111001 |
11000100 10111001 |
C4 B9 |
|
ĺ |
l s čárkou nad |
E5 |
3A 01 |
01 3A |
100 111010 |
11000100 10111010 |
C4 BA |
|
Ľ |
L s háčkem |
BC |
3D 01 |
01 3D |
100 111101 |
11000100 10111101 |
C4 BD |
|
ľ |
l s háčkem |
BE |
3E 01 |
01 3E |
100 111110 |
11000100 10111110 |
C4 BE |
|
O |
|
4F |
4F 00 |
|
|
|
4F |
|
o |
|
6F |
6F 00 |
|
|
|
6F |
|
Ó |
|
D3 |
D3 00 |
00 D3 |
11 010011 |
11000011 10010011 |
C3 93 |
|
ó |
|
F3 |
F3 00 |
00 F3 |
11 110011 |
11000011 10110011 |
C3 B3 |
|
Ô |
O s vokáněm |
D4 |
D4 00 |
00 D4 |
11 010100 |
11000011 10010100 |
C3 94 |
|
ô |
o s vokáněm |
F4 |
F4 00 |
00 F4 |
11 110100 |
11000011 10110100 |
C3 B4 |
|
Ö |
O s dvěma tečkami |
D6 |
D6 00 |
00 D6 |
11 010110 |
11000011 10010110 |
C3 96 |
|
ö |
O s dvěma tečkami |
F6 |
F6 00 |
00 F6 |
11 110110 |
11000011 10110110 |
C3 B6 |
|
P |
|
50 |
50 00 |
|
|
|
50 |
|
p |
|
70 |
70 00 |
|
|
|
70 |
|
Q |
|
51 |
51 00 |
|
|
|
51 |
|
q |
|
71 |
71 00 |
|
|
|
71 |
|
R |
|
52 |
52 00 |
|
|
|
52 |
|
r |
|
72 |
72 00 |
|
|
|
72 |
|
Ř |
|
D8 |
58 01 |
01 58 |
101 011000 |
11000101 10011000 |
C5 98 |
|
ř |
|
F8 |
59 01 |
01 59 |
101 011001 |
11000101 10011001 |
C5 99 |
|
S |
|
53 |
53 00 |
|
|
|
53 |
|
s |
|
73 |
73 00 |
|
|
|
73 |
|
Š |
|
8A |
60 01 |
01 60 |
101 100000 |
11000101 10100000 |
C5 A0 |
|
š |
|
8A |
61 01 |
01 61 |
101 100001 |
11000101 10100001 |
C5 A1 |
|
T |
|
54 |
54 00 |
|
|
|
54 |
|
t |
|
74 |
74 00 |
|
|
|
74 |
|
Ť |
|
8D |
64 01 |
01 64 |
101 100100 |
11000101 10100100 |
C5 A4 |
|
ť |
|
9D |
65 01 |
01 65 |
101 100101 |
11000101 10100101 |
C5 A5 |
|
U |
|
55 |
55 00 |
|
|
|
55 |
|
u |
|
75 |
75 00 |
|
|
|
75 |
|
Ú |
|
DA |
DA 00 |
00 DA |
11 011010 |
11000011 10011010 |
C3 9A |
|
ú |
|
FA |
FA 00 |
00 FA |
11 111010 |
11000011 10111010 |
C3 BA |
|
Ů |
U s kroužkem nad |
D9 |
6E 01 |
01 6E |
101 101110 |
11000101 10101110 |
C5 AE |
|
ů |
|
F9 |
6F 01 |
01 6F |
101 101111 |
11000101 10101111 |
C5 AF |
|
Ü |
|
DC |
DC 00 |
00 DC |
11 011100 |
11000011 10011100 |
C3 9C |
|
ü |
|
FC |
FC 00 |
00 FC |
11 111100 |
11000011 10111100 |
C3 BC |
|
V |
|
56 |
56 00 |
|
|
|
56 |
|
v |
|
76 |
76 00 |
|
|
|
76 |
|
W |
|
57 |
57 00 |
|
|
|
57 |
|
w |
|
77 |
77 00 |
|
|
|
77 |
|
X |
|
58 |
58 00 |
|
|
|
58 |
|
x |
|
78 |
78 00 |
|
|
|
78 |
|
Y |
|
59 |
59 00 |
|
|
|
59 |
|
y |
|
79 |
79 00 |
|
|
|
79 |
|
Ý |
|
DD |
DD 00 |
00 DD |
11 011101 |
11000011 10011101 |
C3 9D |
|
ý |
|
FD |
FD 00 |
O0 FD |
11 111101 |
11000011 10111101 |
C3 BD |
|
Z |
|
5A |
5A 00 |
|
|
|
5A |
|
z |
|
7A |
7A 00 |
|
|
|
7A |
|
Ž |
|
8E |
7D 01 |
01 7D |
101 111101 |
11000101 10111101 |
C5 BD |
|
Ž |
|
9E |
7E 01 |
01 7E |
101 111110 |
11000101 10111110 |
C5 BE |
|
ß |
Ostré s |
DF |
DF 00 |
00 DF |
11 011111 |
11000011 10011111 |
C3 9F |
U některých znaků jsem si uvedl i jejich název, abych je mohl zkontrolovat při korekturách.
V tabulce je vidět kód UCS-2 jednotlivých znaků ve dvojkové soustavě. V dalším sloupci je pak vidět, jak kód UTF-8 přidává bity na začátek každého bajtu. Výsledek je pak v posledním sloupci převeden do šestnáctkové soustavy.
Kód UTF-8 z posledního sloupce všech znaků jsem pořídil hexadecimálním editorem WinVi (viz obr. 6-9). Výsledek jsem uložit jako soubor unicode2.htm
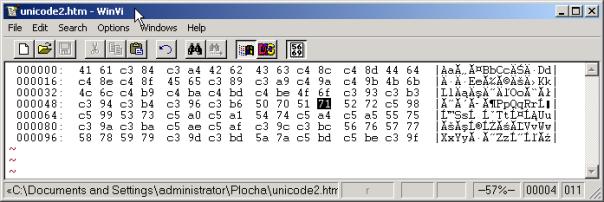
Obr. 6-9 Hexadecimálně pořízený řetězec v kódu UTF-8
Nyní ověříme výsledek naší snahy programem MS Explorer tak, že tento soubor jím otevřeme (viz obr. 6-10)
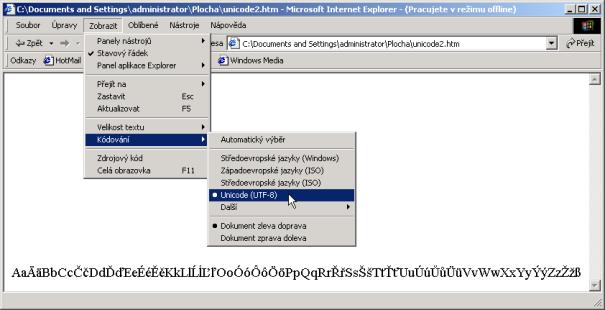
Obr. 6-10 Řetězec zobrazený MS Explorerem
Na obr. 6-10 je vidět, že jsem musel explicitně nastavit kódování UTF-8. To by pochopitelně nebylo nutné, kdybych data obdržel z webového serveru s hlavičkou protokolu HTTP:
Content-Type:
text/utf-8
Asi jste zklamáni, že jsme si neukázali žádné zajímavější znaky. Jak se k nim dostat je vcelku jednoduché. MS Windows 2000 mají aplikaci Mapa znaků (obr. 6-11).
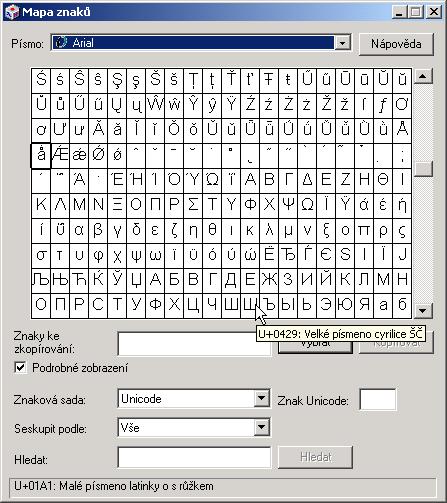
Obr. 6-11 Aplikace Mapa znaků
Stačí zvolit písmo podporující kód Unicode a kurzorem najet např. na znak ruského velkého ŠČ. A v okénku se nám objeví, že v kódu Unicode je tento znak kódován šestnáctkově jako 04 29. V následující tabulce je pak pár příkladů včetně toho velkého ŠČ.
|
Název znaku |
UCS-2 (Unicode) |
UCS-2 binárně |
UTF-8 binárně |
UTF-8 |
|
Velké řecké písmeno ómega |
03 A9 |
1110 101001 |
11001110 10101001 |
CE A9 |
|
Malé řecké písmeno pí |
03 C0 |
1111 000000 |
11001111 10000000 |
CF 80 |
|
Velké písmenu cyrilice ŠČ |
04 29 |
10000 101001 |
11010000 10101001 |
D0 A9 |
|
Malé písmeno cyrilice ju |
04 4E |
10001 001110 |
11010001 10001110 |
D1 8E |
|
Hebrejské písmeno álef |
05 D0 |
10111 010000 |
11010111 10010000 |
D7 90 |
|
Hebrejské písmeno alternativní ajin |
FB 20 |
1111 101100 100000 |
11101111 10101100 10100000 |
EF AC A0 |
|
Znak pro ženu |
26 40 |
10 011001 000000 |
11100010 10011001 10000000 |
E2 99 80 |
|
Znak Eura |
20 AC |
10 000010 101100 |
11100010 10000010 10101100 |
E2 82 AC |
|
Znak copyrightu |
00 A9 |
10 101001 |
11000010 10101001 |
C2 A9 |
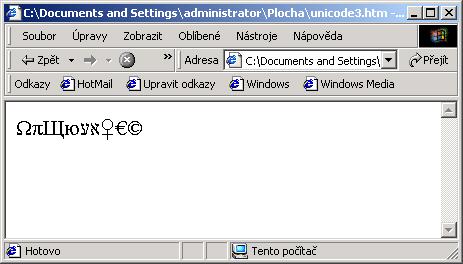
Nakonec jsem vám vše, co je v pravém sloupci pořídil do
souboru a zobrazil na následujícím obrázku 6-12 opět programem MS Explorer.
Obr. 6-12 Znaky z předchozí tabulky zobrazené MS Explorerem